在 Sharedarraybuffers 中使用 Atomics 来避免竞态条件

这是 3 篇文章中的第三篇:
- 内存管理速成教程
- 通俗漫画介绍 ArrayBuffers 和 SharedArrayBuffers
- 在 Sharedarraybuffers 中使用 Atomics 来避免竞态条件
原文链接:Avoiding race conditions in SharedArrayBuffers with Atomics
在 Sharedarraybuffers 中使用 Atomics 来避免竞态条件
在上一篇文章 中,我讲述了使用 SharedArrayBuffers 会导致竞态条件,这让 SharedArrayBuffers 使用困难,我们不希望应用开发人员直接使用 SharedArrayBuffers。
但在其他语言上有多线程开发经验的库开发人员可以使用新的底层 API 来创建高级别的工具,应用开发人员就可以使用这些工具而无需直接接触 SharedArrayBuffers 和 Atomics。
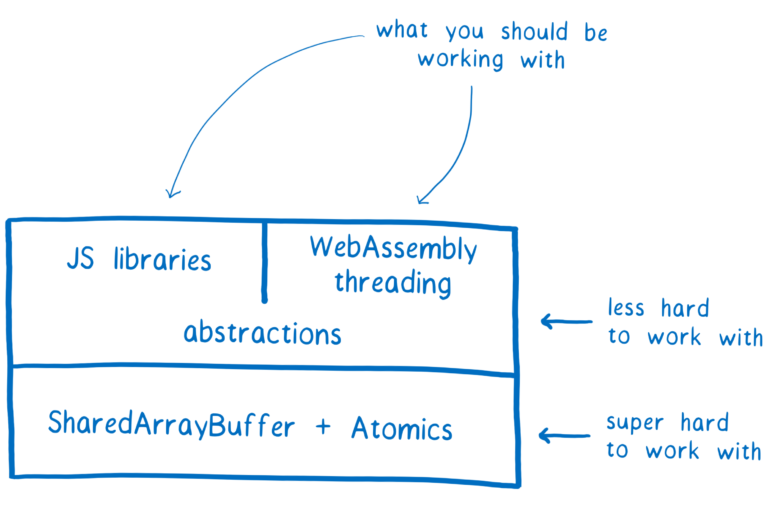
尽管你可能不会直接同 SharedArrayBuffers 和 Atomics 打交道,但我觉得了解它们的工作原理还是比较有意思的,所以在这篇文章中,我将讲解它们会带来哪种类型的竞态条件,然后 Atomics 是如何帮助我们避开它们的。
但首先,什么是竞态条件?
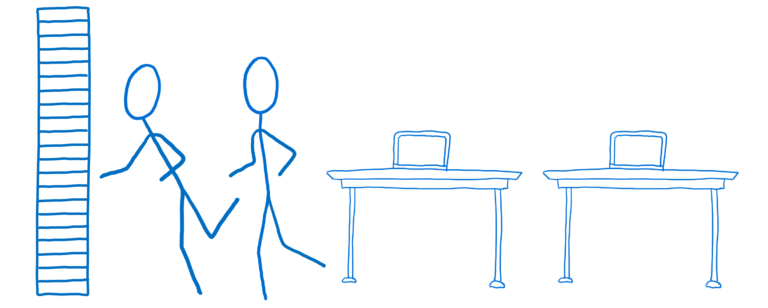
竞态条件:一个你之前可能看过的例子
一个相当简单的竞态条件的例子就是,你在两个线程间共享一个变量。说具体一些,一个线程想要加载一个文件,另外一个线程想检查文件是否存在,它们共享了一个变量叫fileExists,通过它来进行通信。
开始时,fileExists被设置为 false。

只要线程 2 的代码先运行,文件将会被加载。

但如果线程 1 的代码先运行,那么它将给用户一个错误记录,说文件不存在。
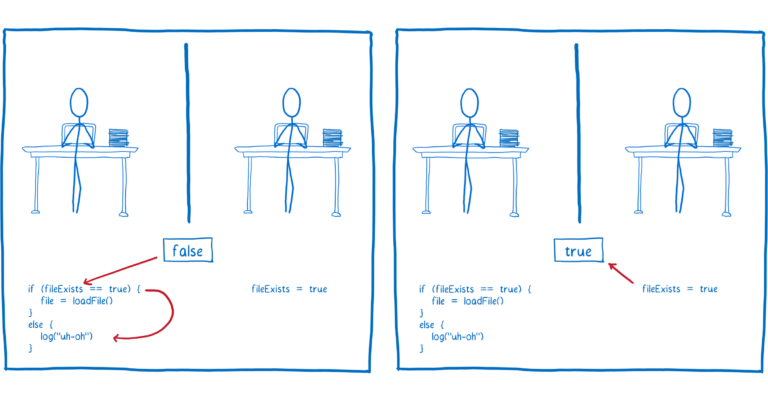
但文件是否存在不是问题所在,真正的问题是竞态条件。
即使是在单线程代码中,很多 JavaScript 开发人员也会遇到这类竞态条件。要了解为什么这是竞态,并不需要明白什么是多线程。
尽管如此,有些类型的竞态条件在单线程代码中不会出现,但在你进行共享内存的多线程编程时会出现。
不同类型的竞态条件和 Atomics 如何辅助
让我们来探索一些你在多线程代码中会遇到的不同类型的竞态条件,然后 Atomics 如何帮助我们避开它们。这里没有覆盖所有的竞态条件,但告诉了你关于为什么 API 会提供这些方法的一些想法。
在我们开始之前,我想要再次申明:你不应该直接使用 Atomics。编写多线程代码是公认的难题,相反地,你应该在你的多线程代码中使用可靠的库来和共享内存打交道。

单个操作中的竞态条件
比方说我们有两个线程来递增相同的变量,你可能会认为不管哪个线程先执行,最终的结果都是一样的。
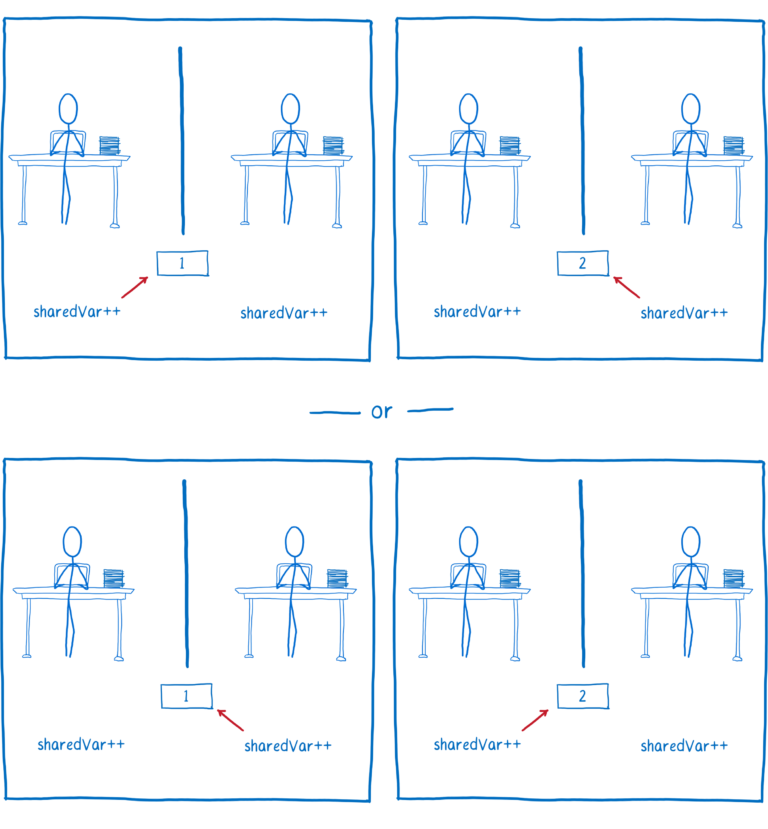
尽管在源码中,递增一个变量看起来是一个单步操作,但在编译后的代码中,它并不是一个单步操作。
在 CPU 层面,递增变量分为三个指令,那是因为计算机既有长期内存也有短期内存(我在另外一篇文章 讲过它们是如何工作的)。
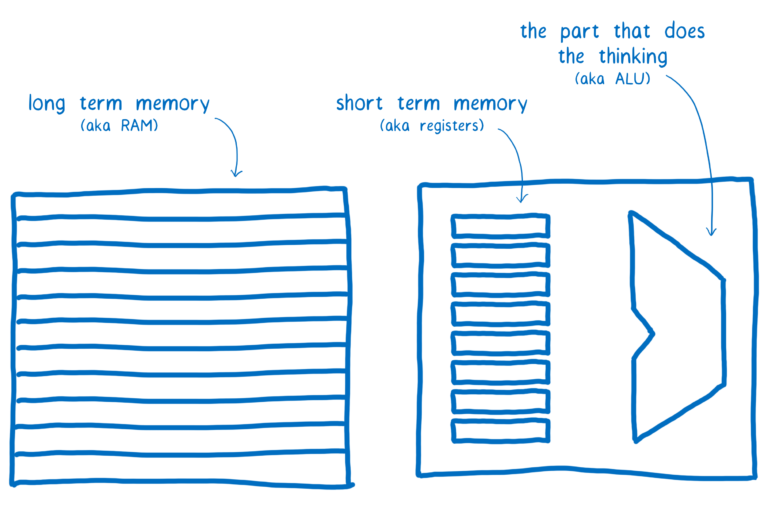
所有线程都共享长期内存,但线程间不共享短期内存(注册者)。
每个线程需要从内存中取到值并放入到短期内存中,然后在短期内存中执行运算,然后把结果从短期内存写回到长期内存。
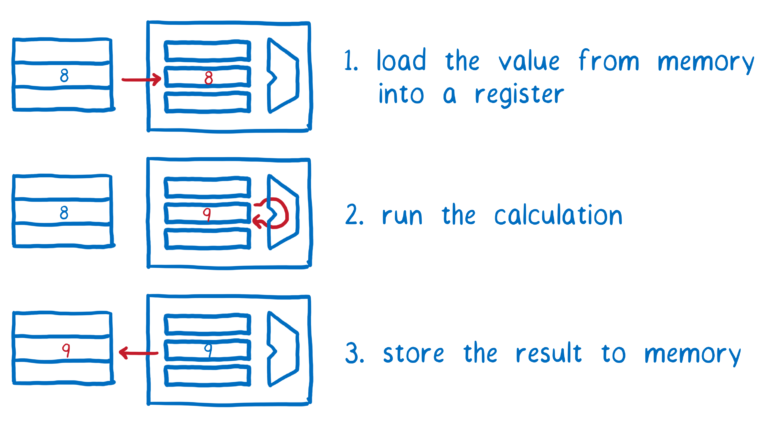
如果线程 1 的所有操作都先发生,然后线程 2 的所有操作接着发生,那么我们将得到期望的结果。

但如果它们交叉进行,线程 2 放入它的注册者中的值不是内存中同步运行后的结果,这意味着线程 2 没有考虑线程 1 的计算结果,它放弃了线程 1 将自己的值写入到内存的结果。
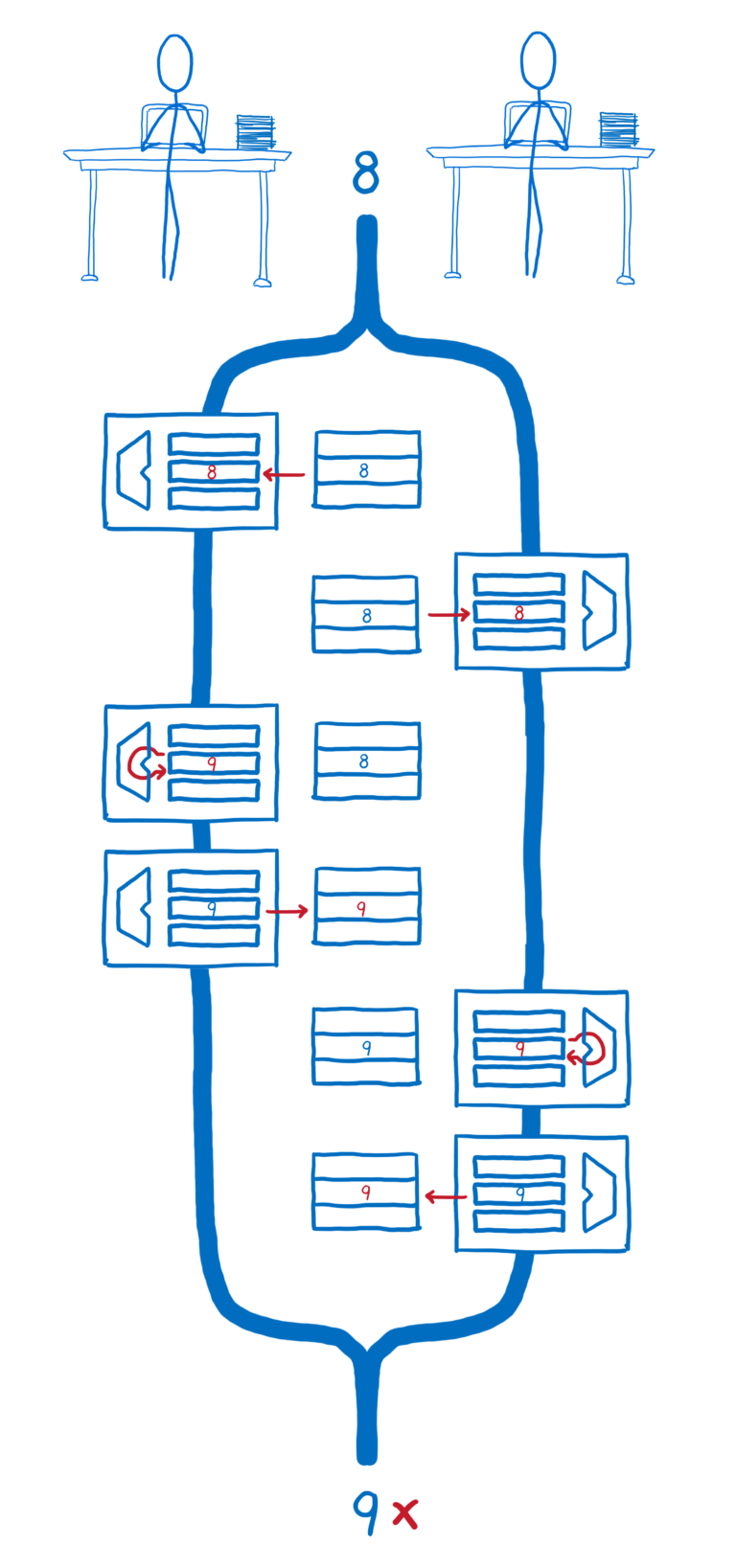
原子操作做的就是把这些计算机觉得是多步的操作作为单步操作,并让计算机也把它们看成是单步操作。
这就是为什么它们叫做原子操作,因为它们执行一个操作,通常这个操作会有多个指令(指令可以暂停和恢复),让所有指令看似瞬间发生,就好像它是一条指令,就像一个不可分割的原子。

使用原子操作,递增变量的代码看起来有点不一样。
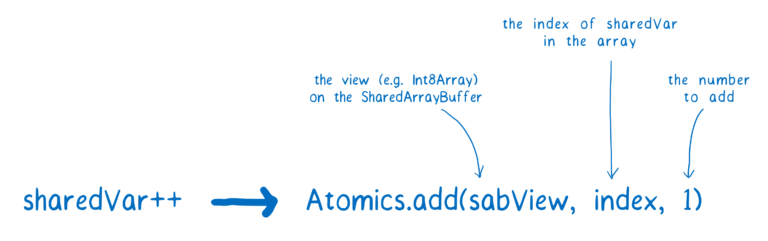
现在我们使用Atomics.add,递增变量的多个步骤将不会在线程间相互交叉,相反,一个线程在完成它的原子操作前不会让其他线程先开始,等本身线程操作执行完了后再让其他线程执行自己的原子操作。
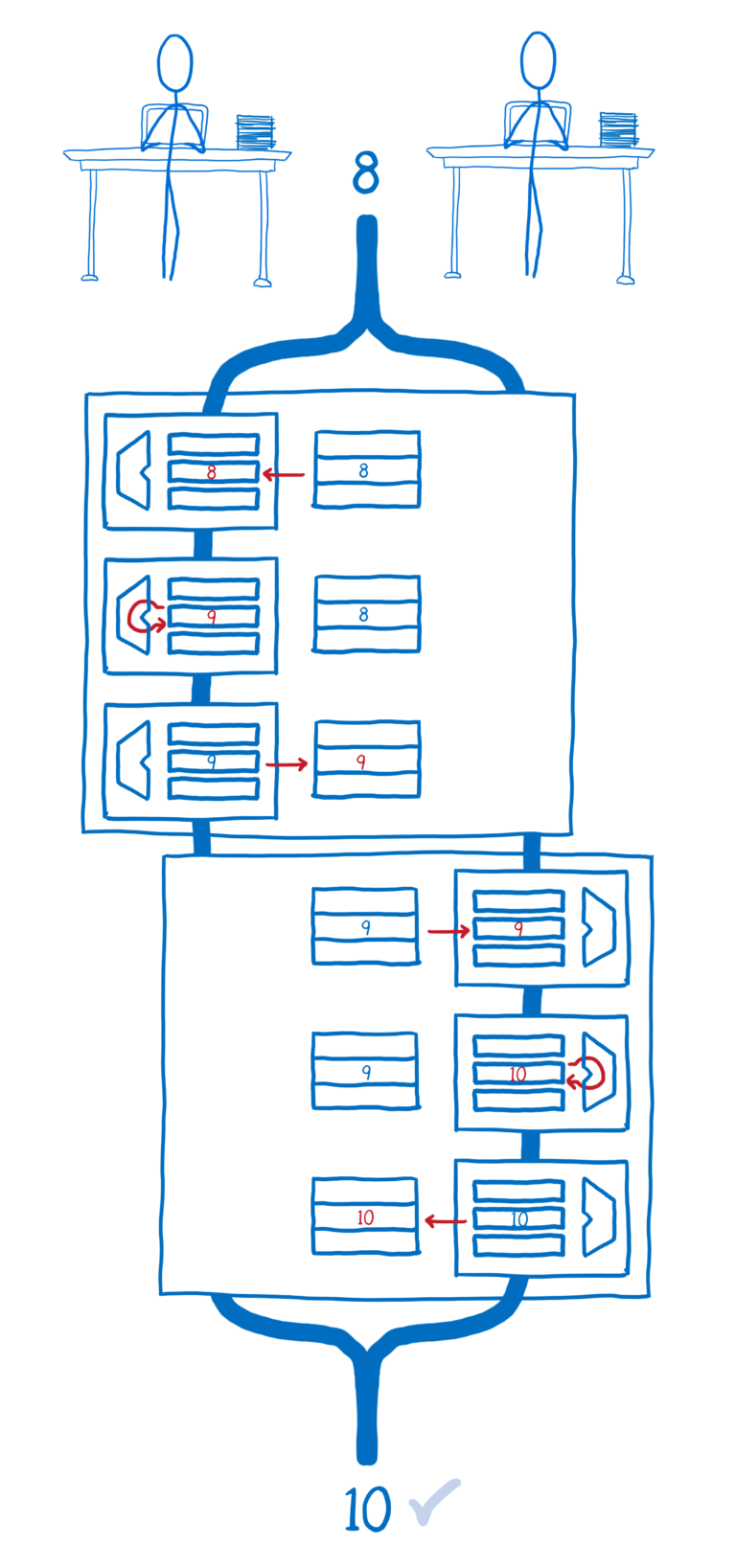
Atomics 的方法帮助避免这类竞态:
你会发现这个列表相当有限,甚至没有包括乘除操作,虽然库开发人员可以创建类似的原子操作。
开发人员可以使用Atomics.compareExchange来做到这点,通过这个方法,你可以从 SharedArrayBuffer 中取到一个值,然后执行操作,如果你是第一个检出的,就没有其他线程会更新它,执行完了再把它写回到 SharedArrayBuffer 里面;如果其他线程更新了它,那么你可以获取最新的值,然后再操作一次。
在多操作中的竞态条件
Atomic 的操作可以帮助你在“单步操作”中避免竞态条件,但有时候你需要改变一个对象的多个值(通过多操作的方式),同时不希望在同一时刻有其他人来更新这个对象。基本上,这意味着每次对象的改变,对象本身相对其他线程来说是锁定并且不可访问的。
Atomics 对象没有提供工具来直接处理这个问题,但它提供了库开发人员可以用来解决这个问题的工具,库开发人员可以创建一个锁。

如果代码想要锁住数据,它必须要有数据的锁,然后它可以用锁来防住其他线程,只有当锁可以用的时候才可以对数据进行访问和更新。
为了创建一个锁,库开发人员可以使用Atomics.wait 和 Atomics.wake,还有其他的方法比如Atomics.compareExchange 和Atomics.store。如果你想要了解这些方法是如何工作的,可以看一下这个基本的锁实现。
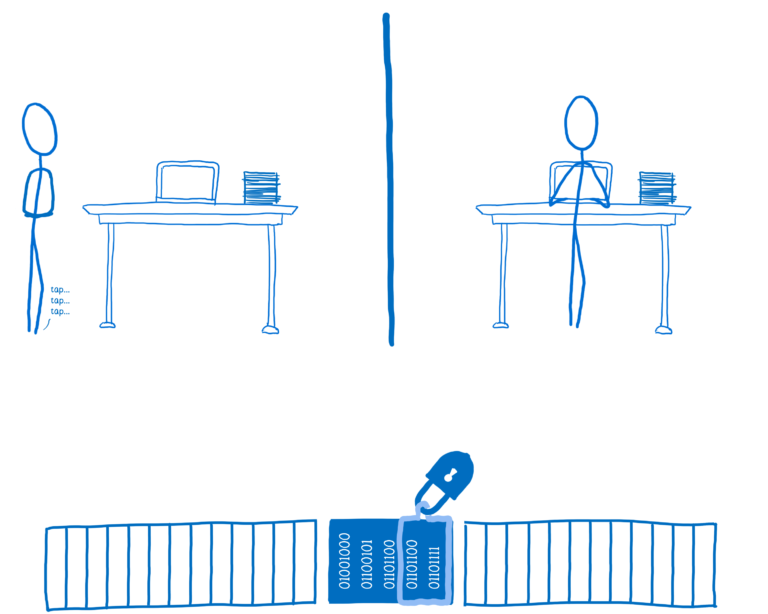
在这个例子中,线程 2 会要求数据的锁并把locked的值设为 true,这意味着在线程 2 解锁之前线程 1 不能访问数据。

如果线程 1 想要访问数据,它会尝试获取锁,但因为锁已经被占用了,所以它获取不到,线程会等待(所以会有阻塞)直到锁可用。
一旦线程 2 完成了,它会调用解锁操作,完了锁会通知那些一直在等待锁的线程们:我现在可以用了。
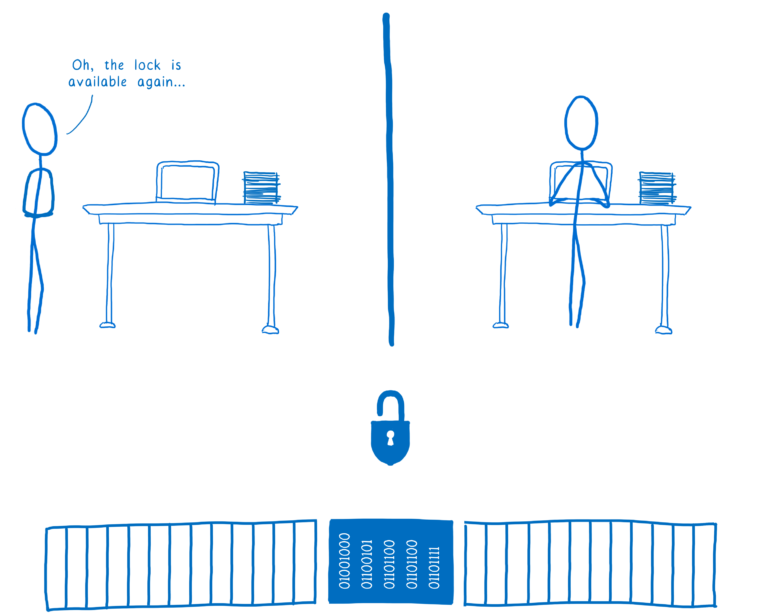
然后线程会取到锁,为它自己能单独使用而将数据锁住。

一个关于锁的库会使用 Atomics 对象多个不同的方法,但在这种情况下最重要的方法是:
指令重排序引起的竞态条件
这是 Atomics 负责的第三种同步问题,这一个会让人惊讶。
你可能没有意识到这一点,但这是一个好机会(让你了解它),你写的代码没有按照你的预期顺序运行,编译器和 CPU 会重新排序代码让其跑得更快。
打个比方,假如说你要写代码来计算总数,你想要在总数计算完成后设置一个标示。

为了编译这些代码,我们需要为每个变量决定使用哪个注册机,然后我们可以将源码翻译成指令给计算机看。

到目前为止,所有事情都按预期进行。
如果你不理解计算机是如何在限制条件下工作的(和如何使用管道来执行代码),那么这看起来会不明显,第二行代码会在它执行之前稍微等一会。
大部分计算机会把执行指令的过程分成多个步骤,这样确保了 CPU 在不同区域都能保持一直忙碌,这样可以充分利用 CPU。
这里是一个指令的过程步骤示例:
- 从内存中获取下个指令
- 计算出指令告诉我们要做什么(比如解码指令),然后从注册者中取到值
- 执行指令
- 把结果写回注册者
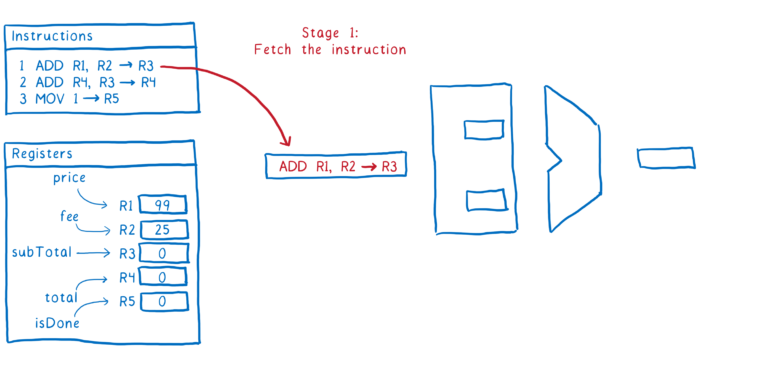
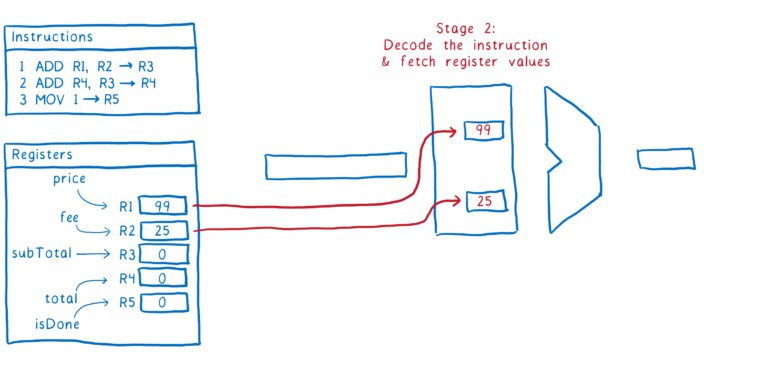

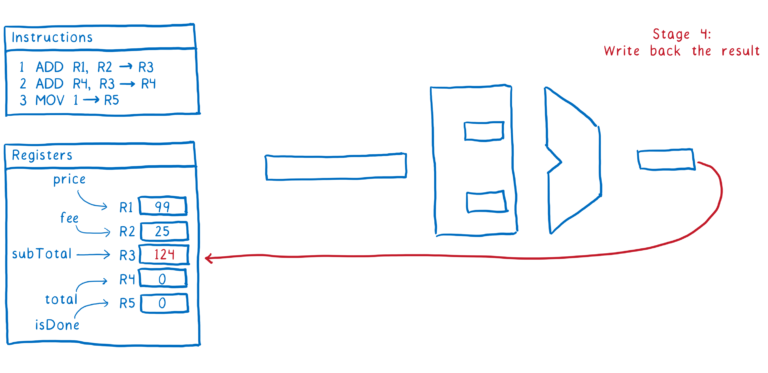
这就是一个指令是经过管道的过程。理想情况下,我们想要紧接着执行第二个命令,一旦我们进入第二步,我们就会去获取下个指令。
问题在于指令#1 和指令#2 之间会有依赖。

我们可以暂停 CPU 直到指令#1 在注册机中更新完subTotal,但这会减慢速度。
为了让事情更有效率,大部分编译器和 CPU 将会重新排序代码,他们会寻找那些没有使用subTotal或total的指令,然后把它们移动到这两行代码中间。

这可以让指令源源不断地移动通过管道。
因为第 3 行没有依赖第 1 或 2 行的值,所以编译器或者 CPU 计算出它重排序是安全的。当你在一个单线程中运行时,没有其他代码会看到这一部分值,直到整个函数执行完成。
但当你在另外一个处理器上有其他的线程在同时运行时,情况就不一样了。其它线程不用等方法完成后再去看这些变化,它可以在回写内存时马上看到它们,所以isDone标示在被告知总数前就被设置好了。
如果你想要用isDone来表示总数已经计算完成并准备用于其他线程,那么这种重排序将产生竞态条件。
Atomics 尝试解决其中的一些缺陷,当你使用一个 Atomic 写操作,就好比在代码的两部分中间放入一个栅栏。
Atomic 没有彼此间的重排序操作,也没有其他操作可以移动它们。实际上,有两个操作经常用于控制顺序:
在同一方法的代码中,所有在Atomics.store上面的变量,它们的更新在其写回内存之前都会在Atomics.store完成之前完成,即使有非原子指令在彼此间重新排序,它们中任何一个指令也不能移动到Atomics.store下面去执行。
在同一方法的代码中,所有在Atomics.load下面的变量,它们的加载都会在Atomics.load完成之后完成,同样地,即使有非原子指令在彼此间重新排序,它们中任何一个指令也不能移动到Atomics.load上面去执行。
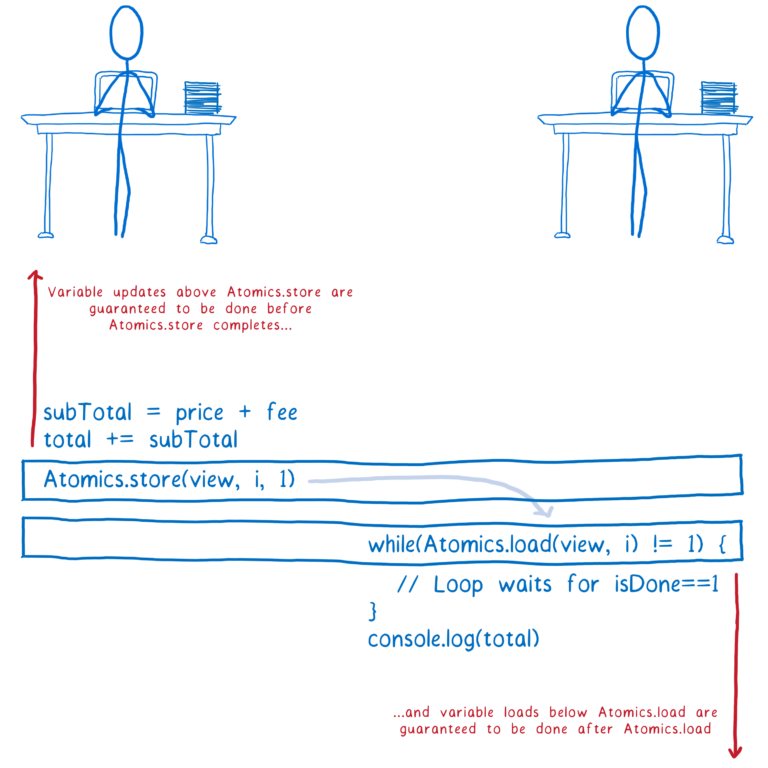
注意,我在这里展示的 while 循环叫做自旋锁,它的效率是非常低的。如果它在主线程中,它可能会让你的应用挂起,你肯定不会在真实代码中使用它。
再次申明,在应用代码中不要直接使用这些方法,相反地,库会用它们来创建锁。
总结
共享内存的多线程编程是困难的,有很多种不同类型的竞态条件的坑等着你去踩。
这就是为什么不要在你的应用代码中直接用 SharedArrayBuffers 和 Atomics,你应该依赖那些有多线程开发经验的开发者开发出来的库,他们花了很多时间在研究内存模型。
现在离 SharedArrayBuffer 和 Atomics 的到来还有点早,这些库也还没创建出来,但这些新的 API 提供了基础功能来创建它们。

