扒一扒 Chatgpt 背后的 web 开发技术(三)

之前介绍了 ChatGPT 的前端和后端的技术,今天我们再来说说 ChatGPT 问答系统中的数据结构。在 ChatGPT 的 Web 应用中,用户和机器人的对话不仅有普通的问答场景,而且有其他的业务场景,在本文中将详细介绍在 ChatGPT 中如何设计数据结构来支持这些业务场景。
ChatGPT 的业务场景
在 ChatGPT 的 Web 应用中,问答功能有多种业务场景。以下是这些业务场景的介绍。
普通问答
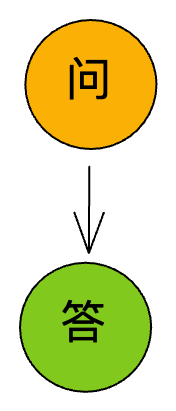
这是最常见的业务场景,用户输入问题,机器人给出答案,这里问题和答案是一对一的关系。在回答问题的过程中,用户不能再提交新的问题。需要注意的是,问题和答案是成对出现的,如果回答问题的过程中出错了(比如网络原因),用户的问题会被丢弃,用户需要重新输入问题。
编辑问题
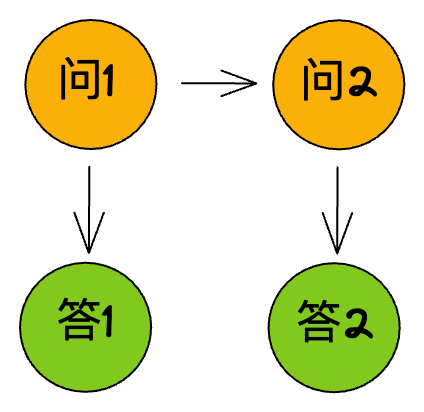
用户如果在提出问题之后,发现自己提的问题有遗漏或者是需要修改,可以通过编辑问题的方式来修改问题。编辑完问题后重新提交,机器人会重新回答问题,这样会产生第二个问答对,跟之前的问答对是平行的关系。同样地,如果在编辑问题的过程中出错了,用户的问题会被丢弃,用户需要重新编辑问题。
重新回答
机器人回答问题后,用户如果对这个答案不满意,可以通过重新回答的方式来让机器人会重新生成新的答案。这个时候就不是产生一个问答对了,而只是产生一个答案。这种方式会让一个问题有多个答案,问题和答案是一对多的关系。要注意一点的是,重新回答只能重新生成最后一个答案。

问题和答案的关系
看完 ChatGPT 的问答业务场景,我们可以梳理在一个对话中问题和答案的关系。
正常流程
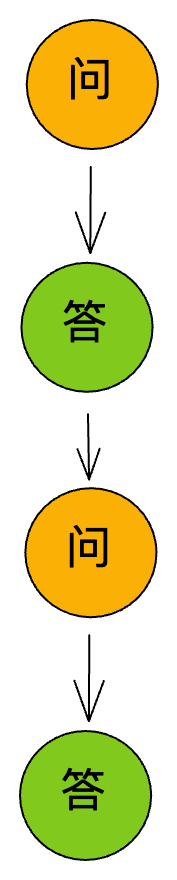
如果用户只是正常地提交问题,机器人回答问题,那么一个对话下来就是一个个问答对串行地出现。
分叉流程
如果用户使用了编辑问题和重新回答的功能,那么就会产生分叉流程。
如果是编辑问题,那么一个答案后面就会接着多个问题,这些问题是平行的关系。
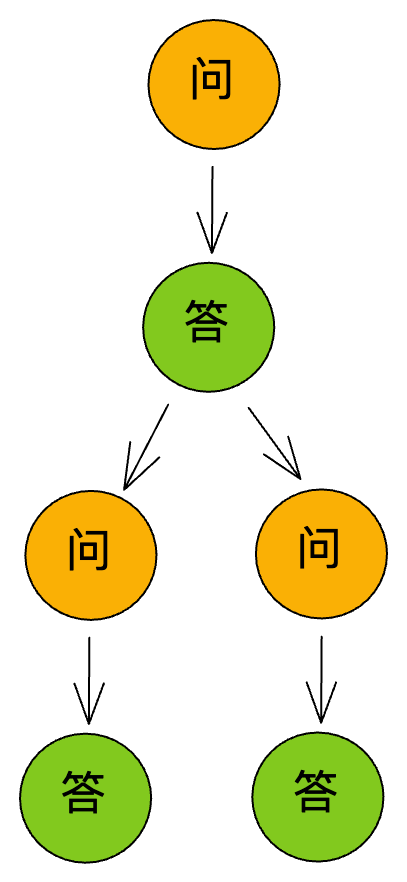
如果是重新回答,那么一个问题后面就会接着多个答案,这些答案也是平行的关系。
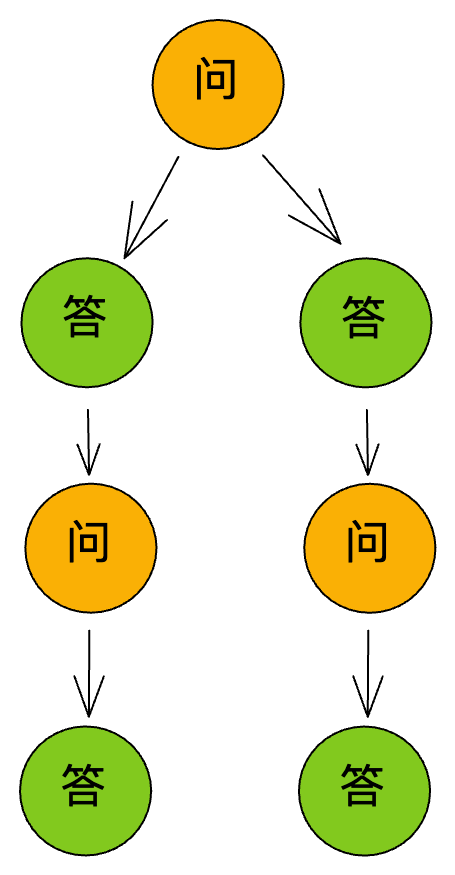
每个分叉的流程都可以继续分叉,这样就会产生一个树状的结构,通过以上的分析,我们可以得到以下结论:
- 每个问题或答案有且仅有一个父节点(第一个问题的父节点就是根节点)
- 一个问题可以有多个答案
- 一个答案只能有一个问题
数据库设计
树结构是一种抽象数据类型,用于表示具有层次关系的数据集合。它由一个根节点以及若干个子树组成,子树中的每个节点又可以拥有自己的子树。树结构的特点是每个节点都有且仅有一个父节点(除根节点外),而一个节点可以有零个、一个或多个子节点。
树结构在计算机科学中有着广泛的应用,比如文件系统、数据库索引、图形学、编译器等等,比如我们熟悉的 Git 分支就是典型的树结构,还有游戏中的分支剧情也可以用这种结构去理解。在 ChatGPT 中,我们使用树结构来表示问题和答案的关系,这样就可以很方便地处理分叉流程的问题。
我们可以使用直接父节点的方法来设计数据库,直接父节点法是一种简单的表示树结构的方法。在这种方法中,为每个节点添加一个父节点 ID 字段,用以表示其父节点。对于根节点,其父节点 ID 字段为 NULL 或特殊值,其优点是结构简单,插入和删除操作方便。表结构示例:
- id:节点 ID
- parent_id:父节点 ID
- name:节点名称(或其他属性)
这种设计可以让我们方便地从树的上层往下查找数据,也可以从树的底层往上查找数据。
多个问题或答案的选择
在 ChatGPT 中进行了问题编辑和重新回答后,在页面上可以看到问题和答案的选择,用户通过点击左右箭头可以来选择不同的分叉流程,也可以说是树的不同路径。
这里的功能是通过一个目标节点来获取树的某个路径,示例图如下:
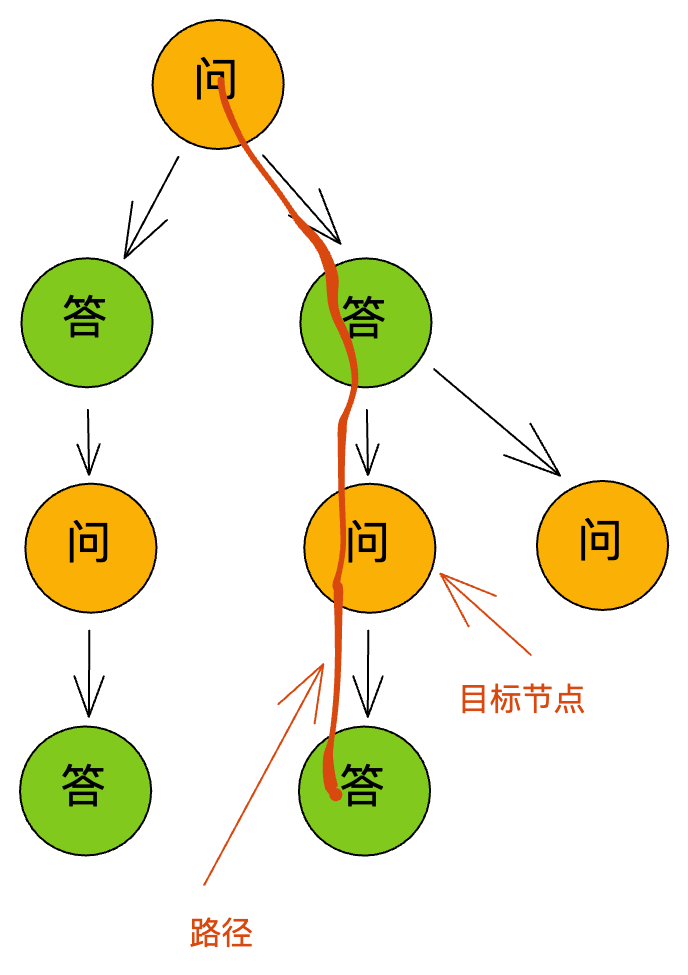
目标节点是选择的节点(问题或答案),路径是从根节点到底层节点的路径,这个路径必须经过目标节点,而且目标节点只能有一个,这样就可以得到一个路径。
刚才我们说过可以从树的上层往下查找数据,也可以从树的底层往上查找数据,这里我们就需要从目标节点开始,从下往上查找数据,直到根节点,代码示例如下:。
1 | let current = targetNode; |
然后再从目标节点开始,从上往下查找数据,直到底层节点,代码示例如下:
1 | let current = targetNode; |
最后将 2 个结果合并,就可以得到一个完整的路径了。
总结
今天介绍了 ChatGPT 中问答的几个业务场景,并根据业务场景探讨了其中的实现原理以及底层的数据结构,希望可以帮助你在今后开发中解决相类似的问题。
这个系列只是讨论 ChatGPT Web 应用中的比较有意思的技术点,并没有对所有功能进行详细的介绍,如果你对 ChatGPT 其他功能的技术实现感兴趣,可以留言进行讨论。

