使用 FastChat 部署 LLM
之前介绍了Langchain-Chatchat 项目的部署,该项目底层改用了 FastChat 来提供 LLM(大语言模型)的 API 服务,下来出于好奇又研究了一下 FastChat,发现它的功能很强大,可以用来部署市面上大部分的 LLM 模型,可以将 LLM 部署为带有标准应用程序编程接口(API)的软件服务,它还提供了 WebUI 界面方便用户通过浏览器来使用 LLM。今天我们就来介绍一下如何使用 FastChat 来部署 ChatGLM2-6B 和 Llama2 模型。
FastChat 介绍
FastChat是一个用于训练、服务和评估基于大型语言模型的聊天机器人的开放平台。其核心功能包括:
- 最先进 LLM 模型的权重、训练代码和评估代码。
- 带有 WebUI 和与 OpenAI 兼容的 RESTful API 的分布式多模型服务系统。
FastChat 安装
FastChat 的安装方式有两种,一种是通过 Pip 进行安装,一种是通过源码安装,由于源码的方式比较复杂,这里就不介绍了,我们使用 Pip 的方式来安装。
1 | pip install fschat |
有些环境在安装完成后,运行 FastChat 的命令会报缺少accelerate这个依赖库的错误,所以为了安全起见,我们也一并安装accelerate这个库。
1 | pip install accelerate |
LLM 下载
LLM 的下载我们可以通过git clone直接从HuggingFace上进行下载,我们在这次演示中需要下载 2 个 LLM,一个是ChatGLM2-6B,一个是Llama2,下载命令如下所示:
1 | # 开启大文件下载 |
如果 Llama2 下载不下来,可能是没有同意协议,可以参考我之前的这篇文章来解决。
另外如果你是用 AutoDL 的 GPU 服务器的话,可以在终端开启学术资源加速,开启后下载 HuggingFace 的资源会快很多。
FastChat 命令行部署
准备工作做好后,我们就可以使用 FastChat 来部署 LLM 了,FastChat 提供了命令行的方式来部署 LLM,命令行的方式比较简单,可以在命令行和 LLM 进行问答交互,我们先看下 FastChat 与 ChatGLM2 的命令行交互:
1 | $ python -m fastchat.serve.cli --model-path /你的下载路径/chatglm2-6b |
再看看 FastChat 与 Llama2 的命令行交互:
1 | $ python -m fastchat.serve.cli --model-path /你的下载路径/Llam2-2-7n-chat-hf |
可以看到我们主要使用了 FastChat 的fastchat.serve.cli命令,然后加上参数--model-path,参数的值就是我们下载的 LLM 具体路径。
FastChat API 部署
我们再来看 FastChat API 的部署,部署 API 服务分三步,第一步是启动控制器服务,启动命令如下所示:
1 | python -m fastchat.serve.controller --host 0.0.0.0 |
这次使用的是 FastChat 的fastchat.serve.controller命令,--host参数是设置服务的主机地址,这里设置为0.0.0.0,表示可以通过任何地址访问,如果不设置 host 的话在 AutoDL 环境上会报错,服务启动后默认端口是 21001。如果想查看该命令的更多信息可以执行python -m fastchat.serve.controller --help命令。
第二步是启动 Model Worker 服务,启动命令如下所示:
1 | python -m fastchat.serve.model_worker --model-path /你的下载路径/chatglm2-6b(或者是Llam2-2-7n-chat-hf) --host 0.0.0.0 |
使用 FastChat 的fastchat.serve.model_worker命令来启动服务,通过--model-path参数来指定 LLM 的路径,服务启动后默认端口是 21002,可以通过--port参数来修改端口,如果想查看该命令的更多信息可以执行python -m fastchat.serve.model_worker --help命令。
第三步是启动 RESTFul API 服务,启动命令如下所示:
1 | python -m fastchat.serve.openai_api_server --host 0.0.0.0 |
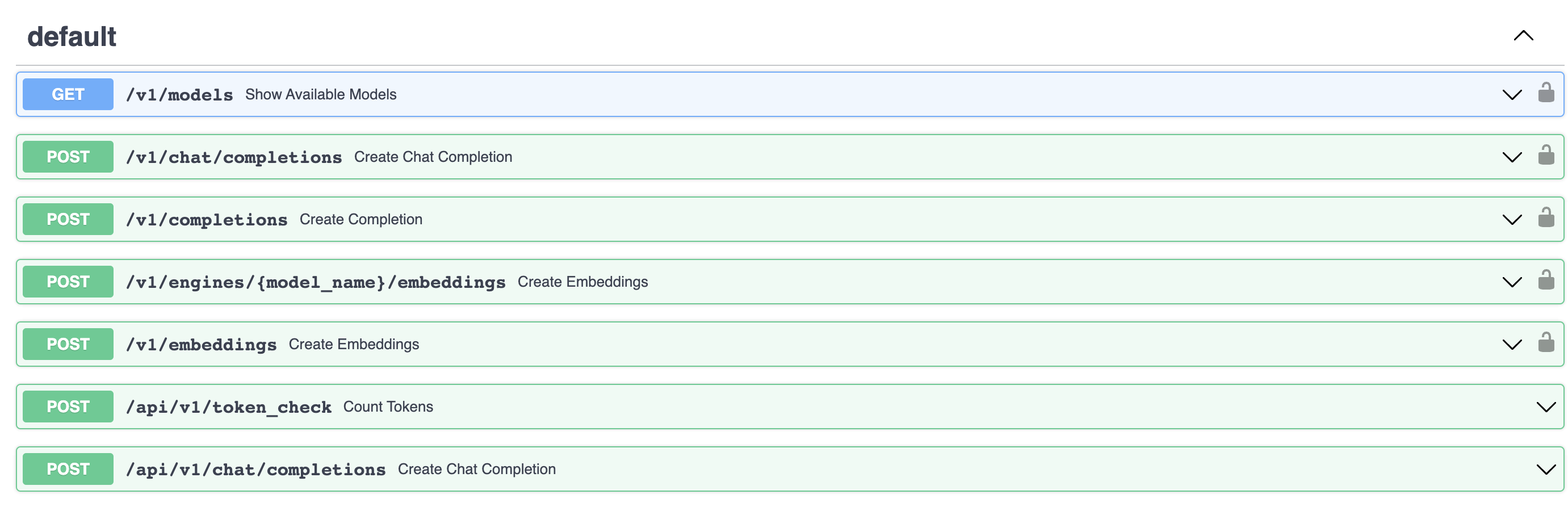
服务启动后,默认端口是 8000,可以通过--port参数来修改端口,在浏览器中访问服务的这个路径http://127.0.0.1:8000/docs可以查看接口信息,这个服务就是我们最终要用的 LLM API 服务,它的接口跟 OpenAI 的接口是兼容的,不仅可以推理,还可以进行 Embedding 操作,接口信息如下所示:
FastChat WebUI 部署
FastChat 还提供了 WebUI 界面,我们可以通过浏览器来访问 WebUI 服务来进行问答交互,在启动 WebUI 服务之前,请确保已经启动好了上面的控制器服务和 Model Work 服务,启动 WebUI 服务的命令如下所示:
1 | python -m fastchat.serve.gradio_web_server --host 0.0.0.0 |
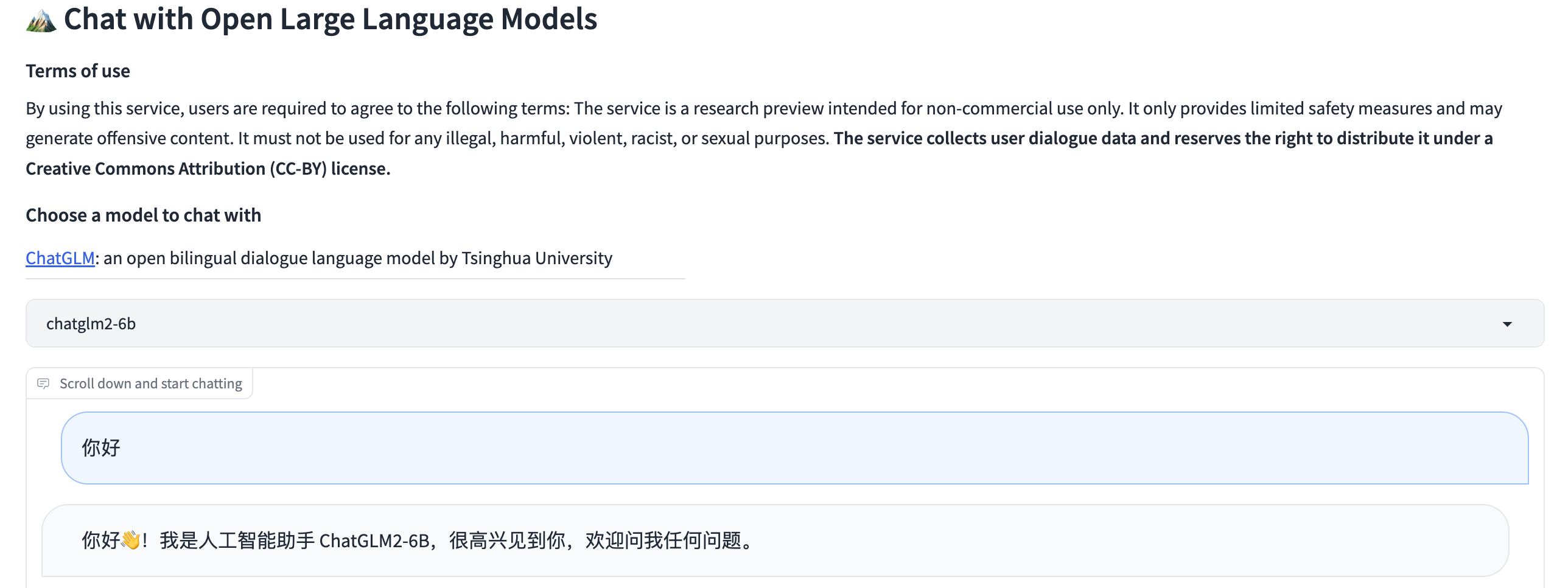
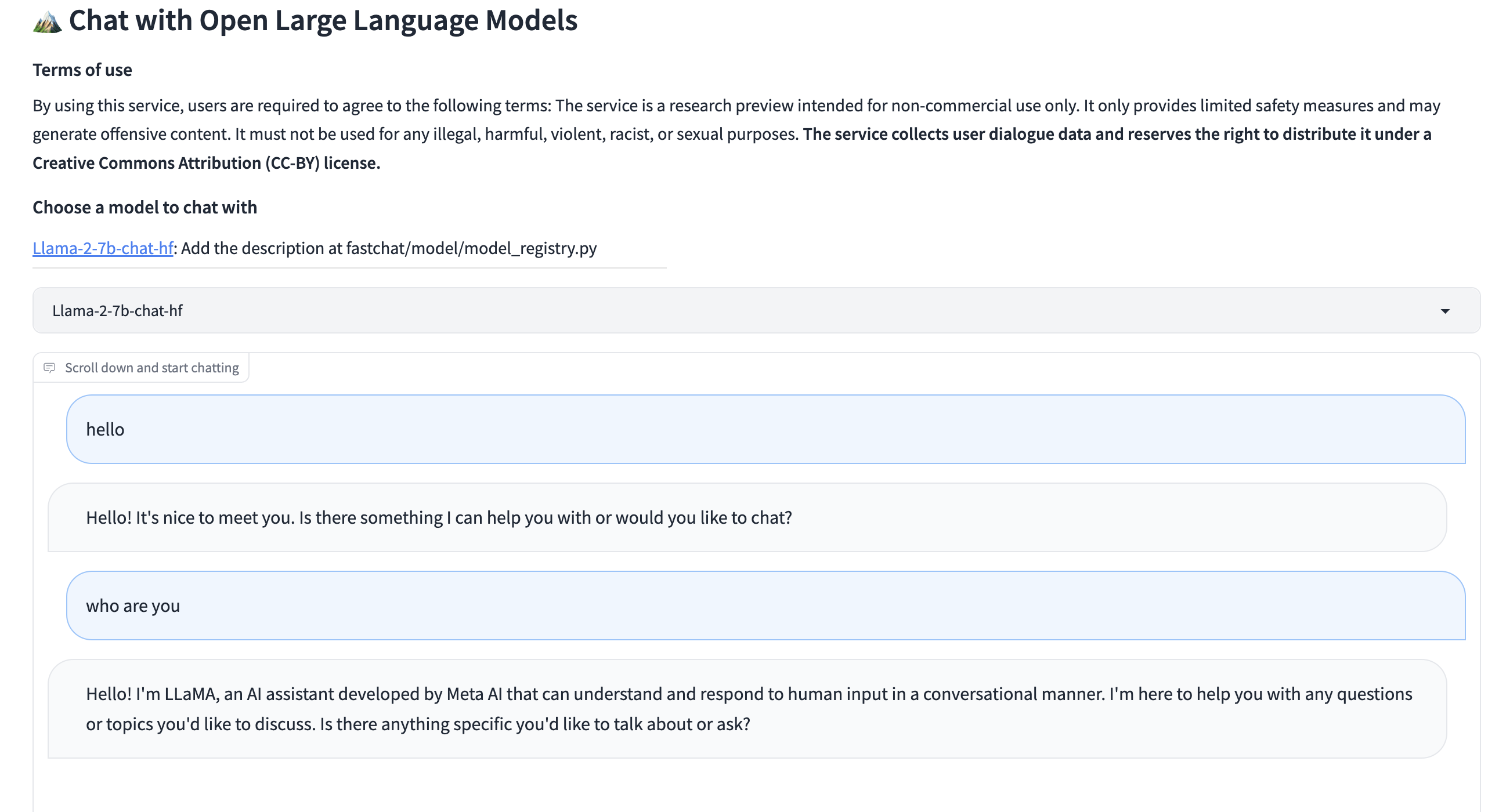
服务默认端口是 7860,可以通过--port参数来修改端口,还可以通过添加--share参数来开启 Gradio 的共享模式,这样就可以通过外网访问 WebUI 服务了,WebUI 界面如下所示:
ChatGLM2
Llama2
总结
其实 FastChat 的功能非常强大,今天介绍的部署功能只是冰山一角,如果你对 FastChat 感兴趣的话,可以去官方仓库查看更多的信息。今天的文章就到这里,如果在部署的过程中遇到问题,欢迎在评论区讨论。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。

