使用 API 生成 Stable Diffustion 文字和二维码隐藏图片

Stable Diffusion 前段时间有几个比较火的效果,一个是将文字隐藏在图片中,放大看时是一张正常图片,缩小看却可以看到图片中的隐藏文字,另外一个效果与前者类似,但是图片中隐藏的是一个二维码,通过扫描图片可以进入二维码中的网址。由于出图效果好,很多人想要根据自己的需求制作这种图片,甚至有人在网上出售这种图片的定制服务。今天我们就来介绍下如何使用 API 的方式 在 Stable Diffusion 中实现这种效果。
预安装环境
硬件要求: 首先要使用 Stable Diffusion,建议有一张 GPU 显卡,CPU 的话速度会比较慢,显存建议是 6G 及以上,否则可能会出现显存不足的情况。
Stable Diffusion WebUI
软件方面需要安装 Stable Diffusion WebUI(下面简称 sd-webui),安装方法可以参考其仓库上的安装说明,里面有针对 Linux 系统的一键安装脚本,这里就不再赘述。
安装完软件后,系统会默认下载 Stable Diffusion 1.5 的模型,为了后面出图效果更好,建议大家下载以下 2 个模型,这 2 个模型都是写实风格的:
- Realistic Vision V5.1:人物写实风格
- Photon:场景写实风格
模型下载下来后放到 sd-webui 的models/Stable-diffusion目录下,然后重启服务即可。
sd-webui 插件
安装完 sd-webui 后,还需要安装以下几个插件。
sd-webui-controlnet
要实现隐藏效果图片,需要借助大名鼎鼎的神经网络架构 ControlNet,它可以使我们在图像生成过程中拥有更多的结构和艺术控制能力。ControlNet 在 sd-webui 中有相应的插件——sd-webui-controlnet,安装方法可以参考其仓库上的安装说明。
安装完插件后,我们还需要下载 2 个插件相关的模型(这里的模型是指 ControlNet 的模型,之前的模型是 Stable Diffusion 的模型,两者并不相同):
- monster-labs/control_v1p_sd15_qrcode_monster:这个模型是用来生成隐藏效果图的关键模型,下载仓库中的
diffusion_pytorch_model.safetensors文件即可,下载完成后将文件名修改成control_v1p_sd15_qrcode_monster.safetensors。 - ioclab/control_v1p_sd15_brightness:这个模型的效果是让亮的地方更亮,让暗的地方更暗,总的来说就是让隐藏的效果更加明显,下载仓库中的
diffusion_pytorch_model.safetensors文件即可,下载完成后将文件名修改成control_v1p_sd15_brightness.safetensors。
模型下载下来后放到 sd-webui 的extensions/sd-webui-controlnet/models目录下。
sd-webui-qrcode-toolkit
sd-webui-qrcode-toolkit插件主要用来生成普通的二维码,然后将生成后的二维码图片放到文生图中制作隐藏效果图,安装方法可以参考其仓库上的安装说明。
ADetailer
ADetailer插件主要是用来做人物面部修复,隐藏效果图中如果包含人物,生成出来的图片有时候会因为隐藏信息导致人物的面部发生扭曲,使用这个插件可以修复这个问题,安装方法同样参考其仓库上的安装说明。
手动实现
想要通过 API 实现隐藏效果图,我们先要知道在 sd-webui 页面上是如何实现的,然后再根据这个过程来实现 API 功能。
隐藏文字图片
首先我们来看隐藏文字图片的生成,和普通图片的生成一样,需要先构造图片的提示词,这里推荐灵羽助手这个基于 ChatGPT 的桌面 AI 工具,它有多种提示词模板,其中包括中英文翻译,生成 AI 绘画中文提示词等,每天有 10 次免费的额度,想白嫖的话用每天的免费额度就足够了。
在灵羽助手中先通过生成AI绘画中文提示词命令加上几个简单的词语描述就可以生成一段文生图的中文提示词,然后再利用翻译成英文命令将其翻译成英文,最后将英文提示词放到 sd-webui 的文生图正向提示词框中就可以了,这里我们准备生成一张海岸和海浪的图片。

反向提示词我们用这个就好了:cartoonpaintingllustration, (worst quality, low quality, normal quality:2),其他配置可以参照下图,注意图片的宽度和高度要和 ControlNet 插件中上传的图片一致。
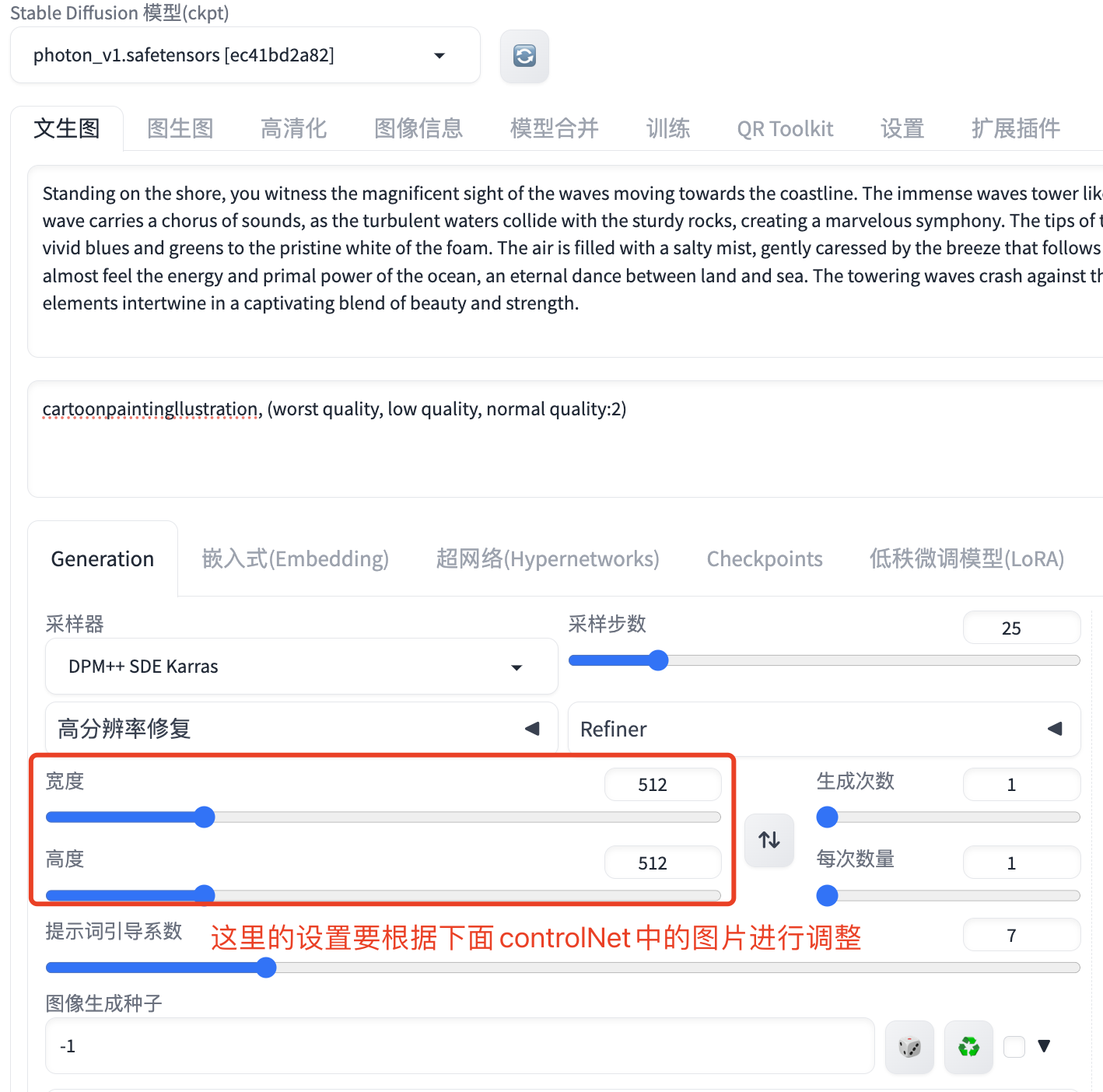
在 ControlNet 插件中,我们需要用到 2 个 ControlNet Unit,在第一个 Unit 中我们先上传一张文字图片,这个文字就是要在图片中隐藏的文字,可以用 Word 或者 WPS 写一个字然后截图保存下来,保存下来后记得看下图片的尺寸,然后修改上面提到的图片宽度和高度。其他属性的修改可以参考下图,模型要选择control_v1p_sd15_qrcode_monster:
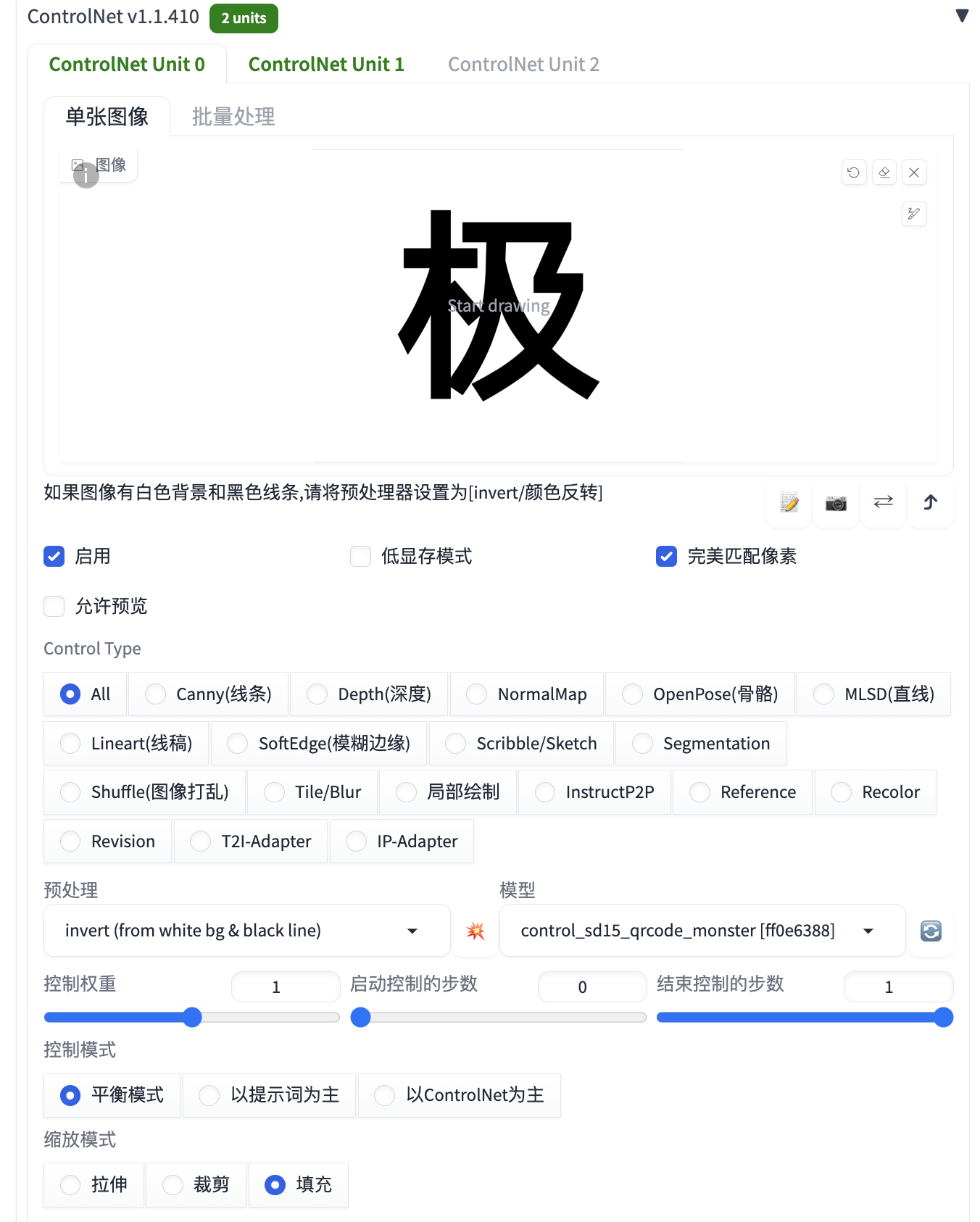
因为文字图片是白底黑字的,需要在预处理中选择invert,如果文字图片是黑底白字的话就需要选择无。
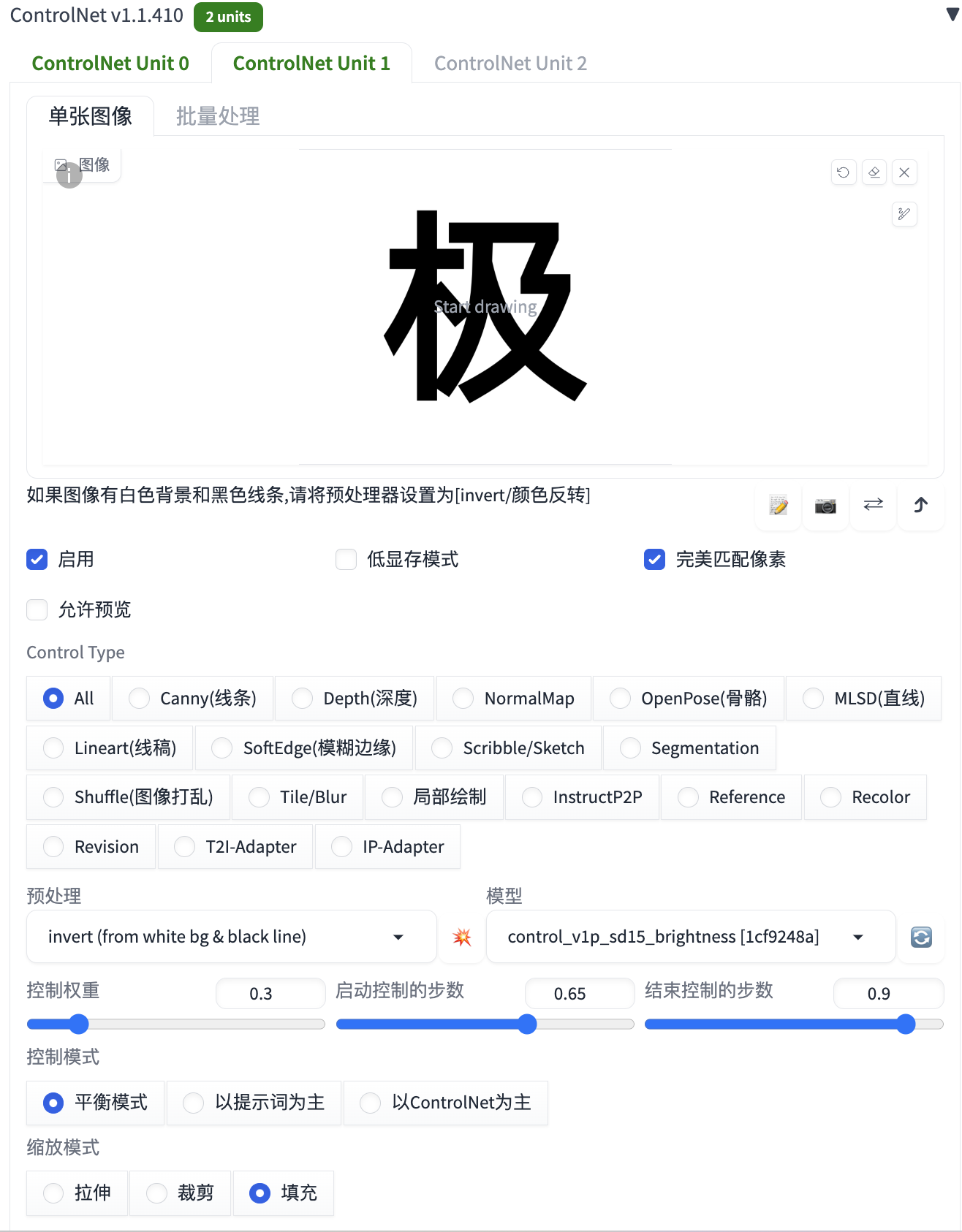
ControlNet 第二个 Unit 的配置大致相同,上传同样的图片,但模型要选择control_v1p_sd15_brightness,还有控制权重、启动控制的步数和结束控制的步数也需做相应调整,详细配置信息如下:
生成的效果如下:
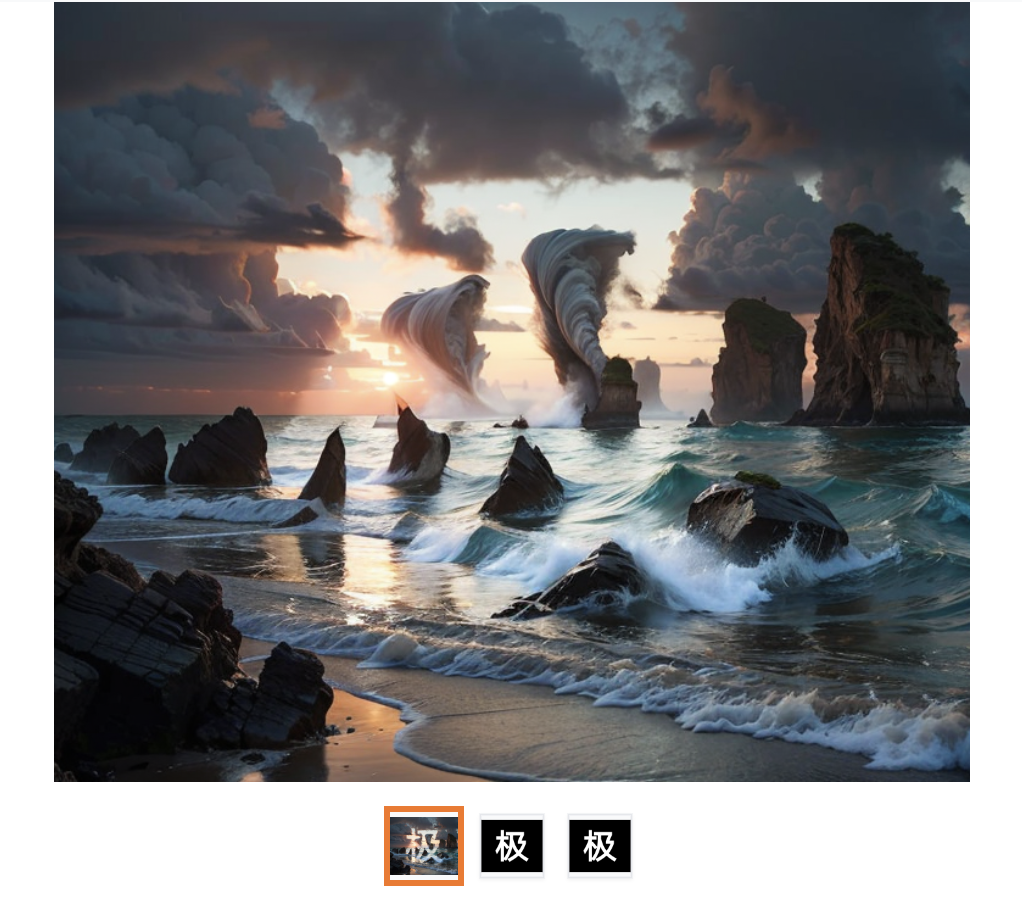
除了隐藏文字外,我们还可以隐藏 LOGO,比如将文字图片中的文字换成 APPLE 的 LOGO,也可以实现类似的效果。
隐藏二维码图片
生成隐藏二维码图片我们需要先制作一张二维码图片,这张图片要放到 ContolNet 插件中作为图片生成的引导。二维码图片的制作需要用到之前预安装的sd-webui-qrcode-toolkit插件,安装完插件后,我们可以在 sd-webui 的顶部菜单栏中看到QR Toolkit这个菜单,进入后可以看到如下界面:
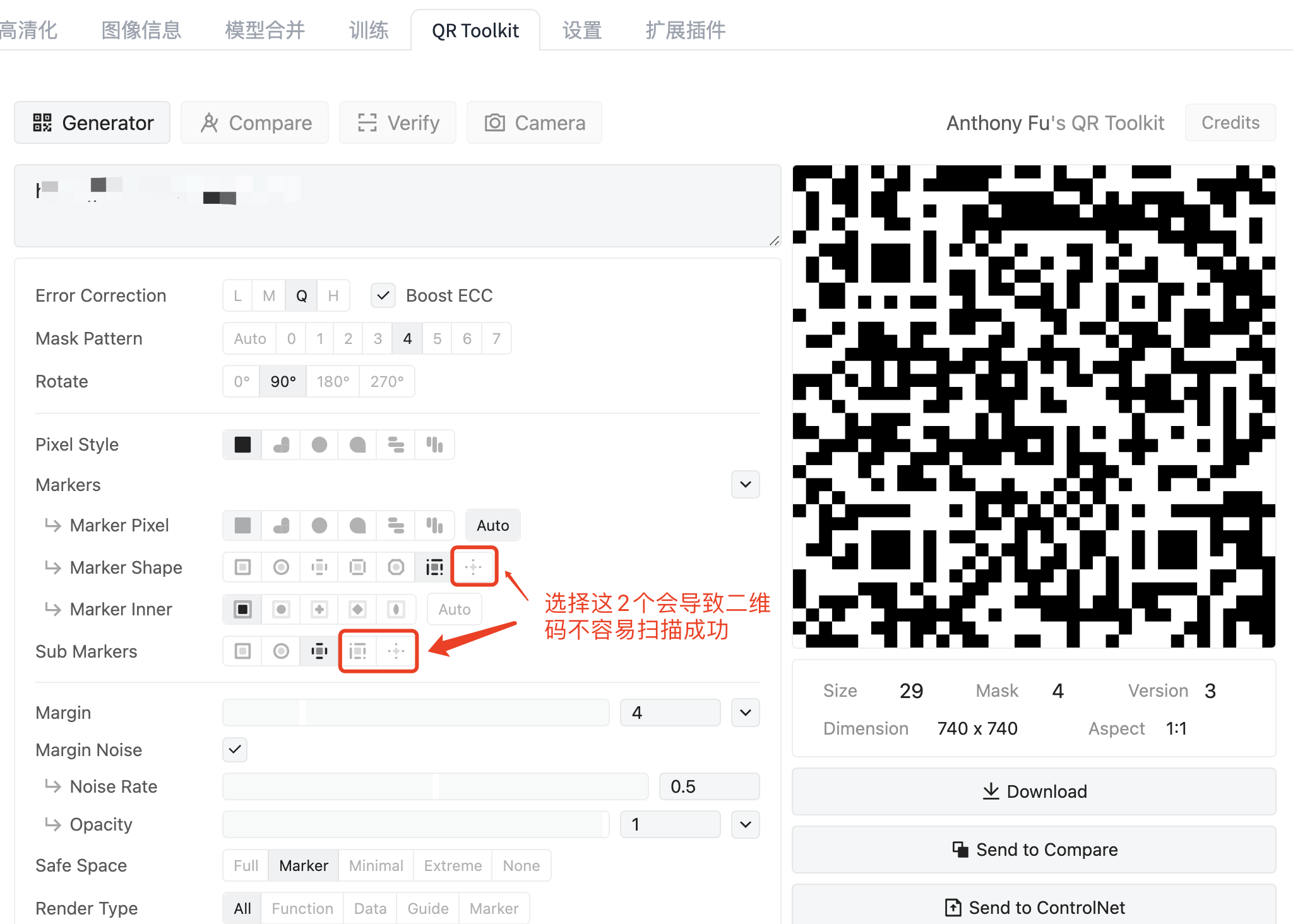
在 QR Toolkit 中输入一个网址后右边会生成二维码,下面的各种参数用来调整二维码图片的效果,截图之外的参数不需要调整,只需要调整上图中的参数即可。这里主要的目标是尽量让二维码图片看起来不那么像二维码,这样生成出来的图片二维码的痕迹就不会那么重。但如果二维码图片调整太过的话,可能导致生成的图片无法被正常扫描,因此要做好其中的权衡,在调整过程中如果二维码不容易被扫描,QR Toolkit 会提示:This QR Code may or may not be scannable. Please verify before using。调整完后下载二维码图片以备用。
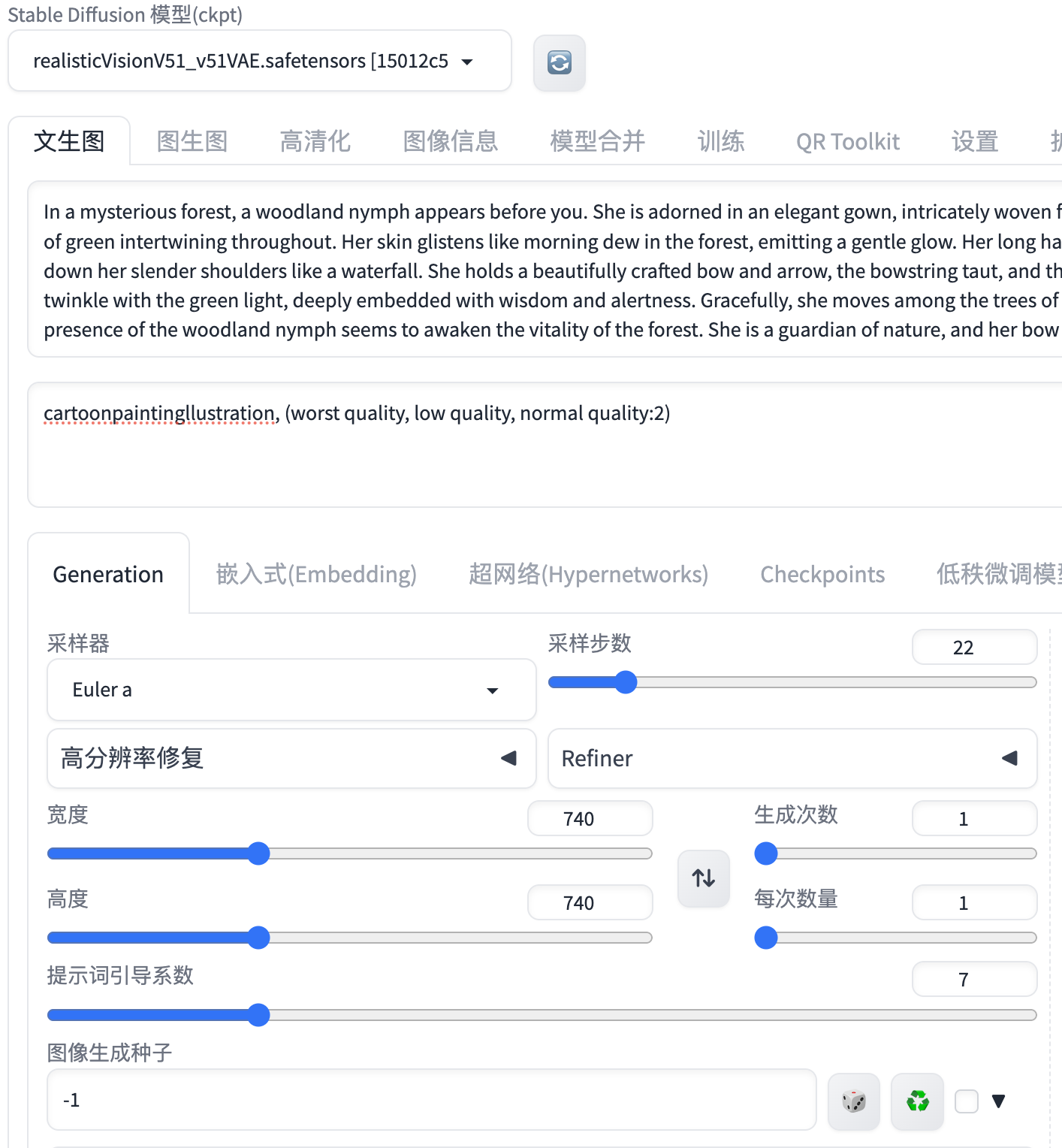
回到文生图界面中,这次我们选择的模型是Realistic Vision V5.1,准备生成一张森林女精灵的图片,采样器建议选择Euler a,注意宽度和高度要和二维码图片的高度和宽度一致,详细配置信息如下所示:
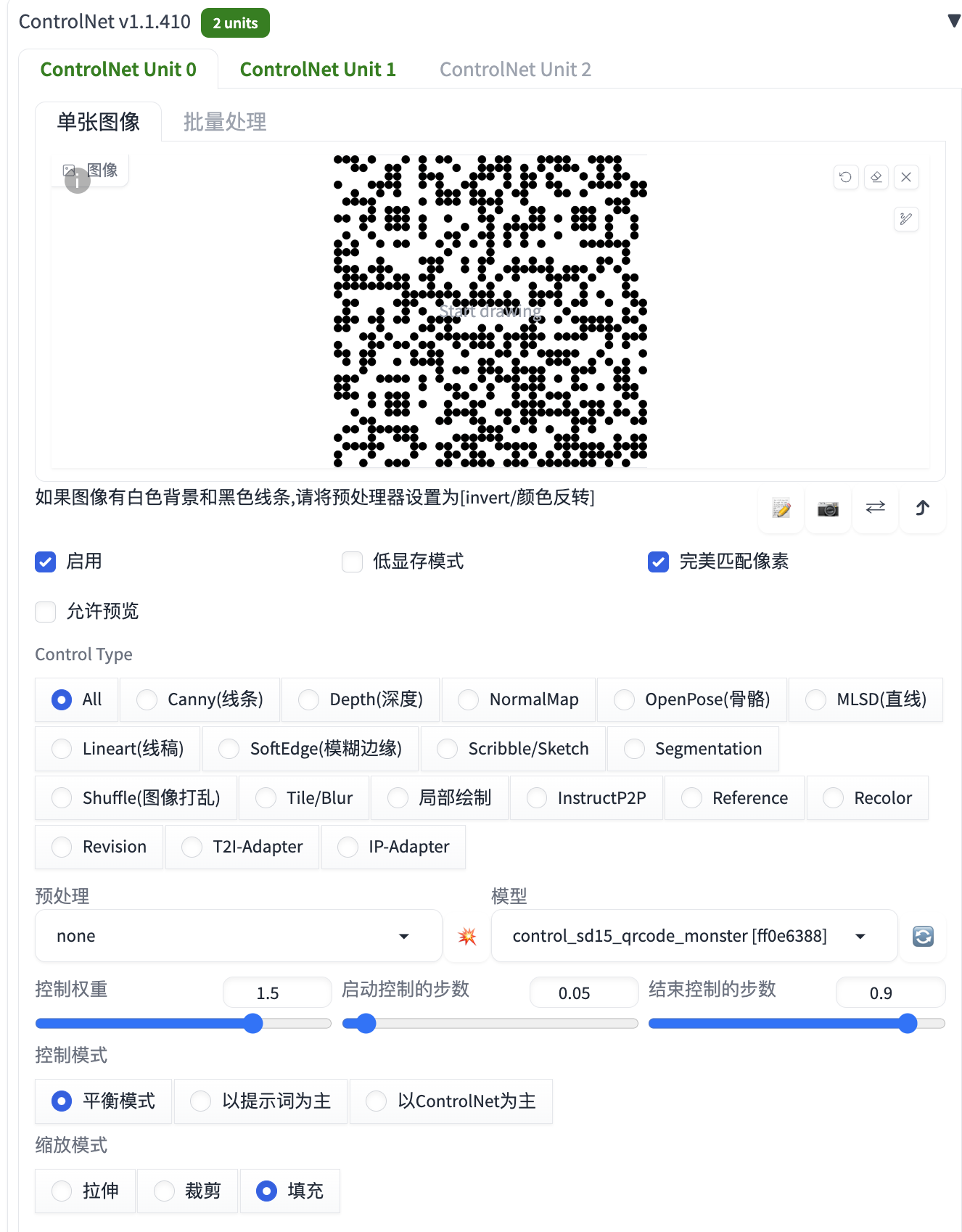
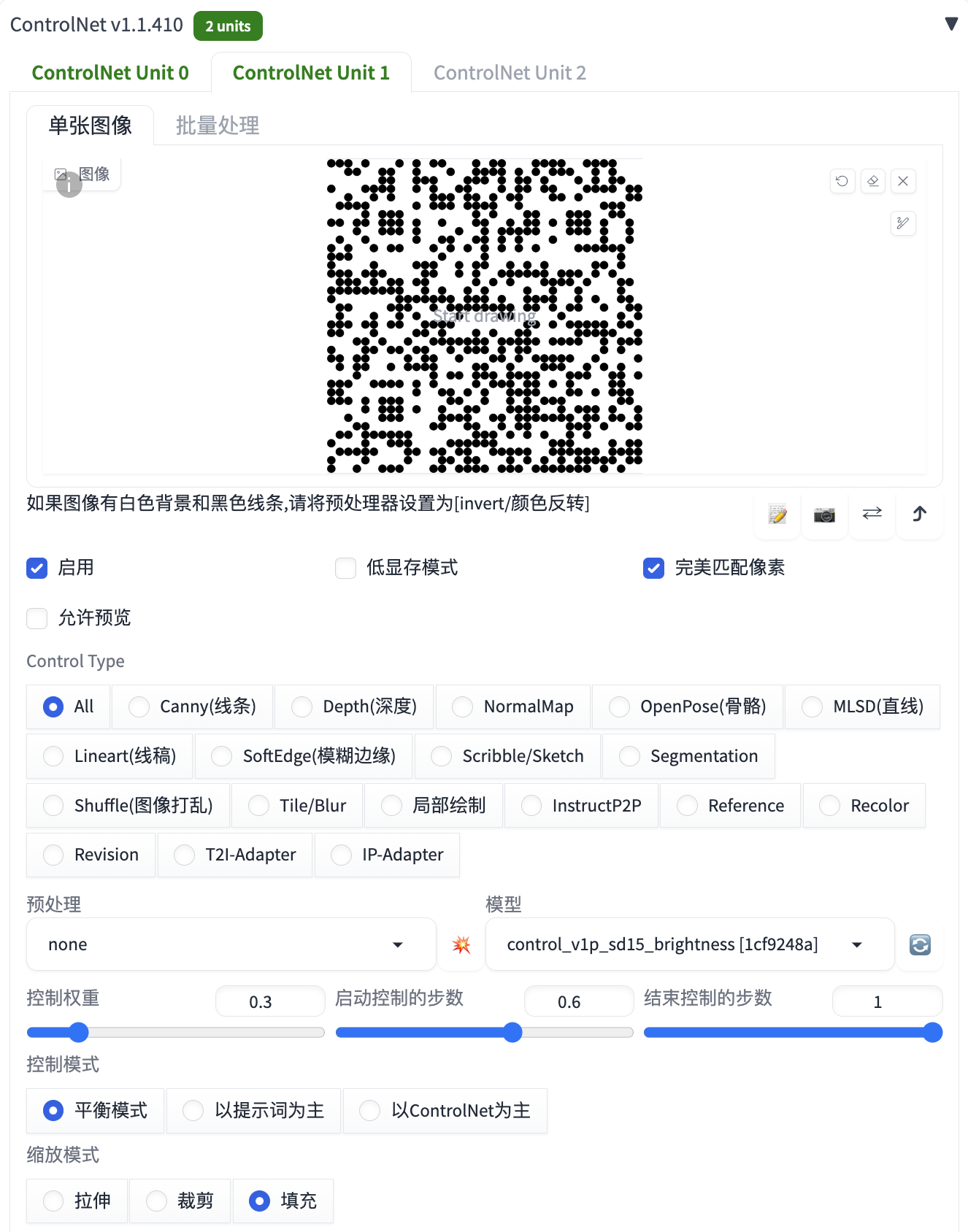
在 ControlNet 插件中,同样需要用到 2 个 ControlNet Unit,步骤与隐藏文字相同,只是将文字图片替换成之前生成的二维码图片,详细配置信息如下:
因为这次生成的图片有人物,所以我们要用到 ADetailer 插件来进行面部修复,ADetailer 的配置信息如下:
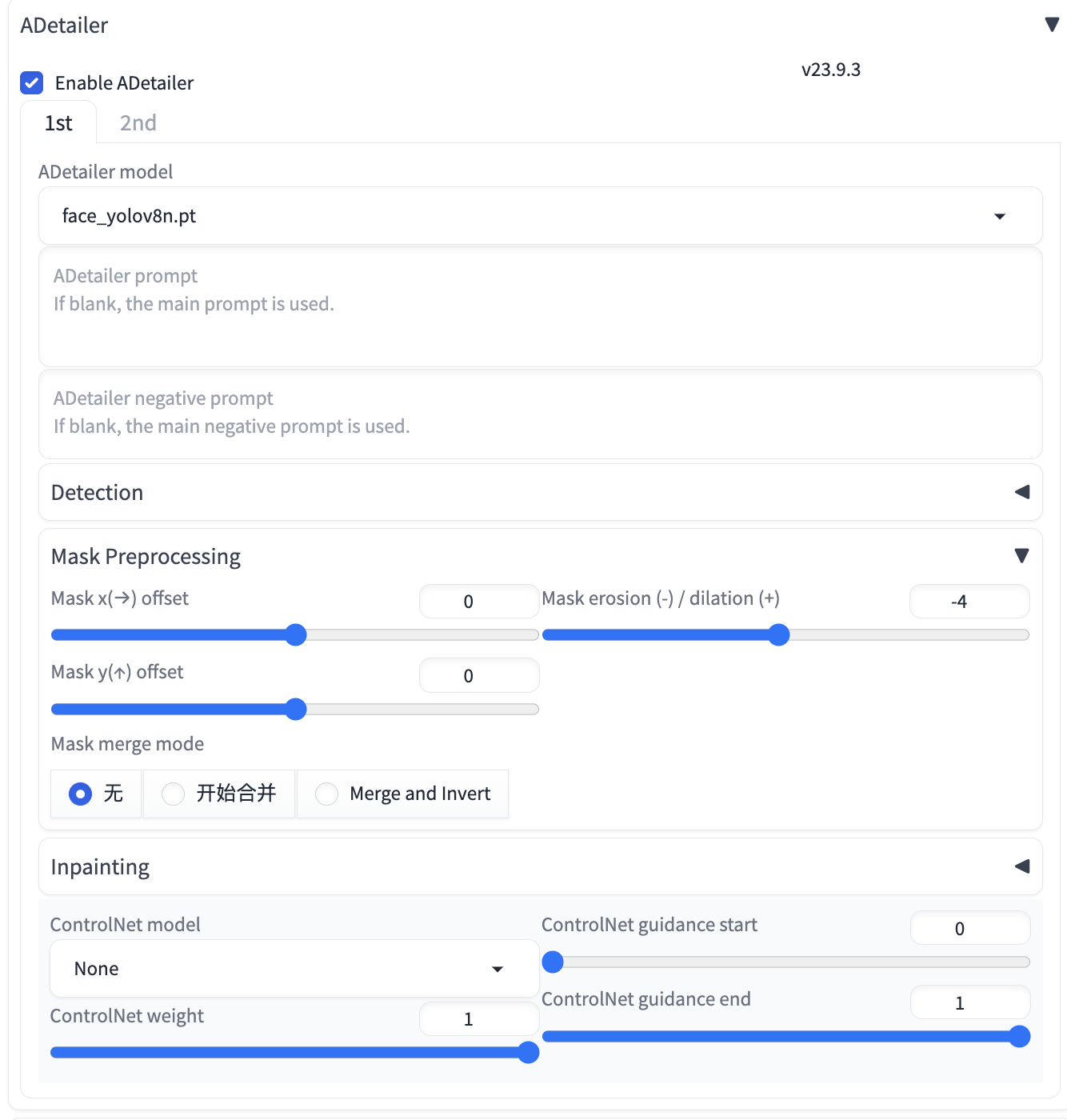
生成的效果如下:

使用 API 实现
了解了手动实现的过程后,我们再来看 API 的实现方式。
sd-webui API 服务
首先我们要启动 sd-webui 的 API 服务,正常启动 sd-webui 是通过webui.sh命令(Windows 是webui.bat)进行启动,默认方式启动后只能是本地访问,如果你的 sd-webui 是部署在服务器上的话,那么你无法通过{服务器IP}:7860这个地址进行访问,这时候你需要添加参数--listen,添加过后就可以通过{服务器IP}:7860地址进行访问了。
1 | bash webui.sh --listen |
如果你想在浏览器上安装插件的话,系统会报安全错误提示,这意味着不允许你在服务器上直接安装 sd-webui 插件,这时候你需要添加参数--enable-insecure-extension-access。
1 | bash webui.sh --listen --enable-insecure-extension-access |
这样启动 sd-webui 服务后只能访问 web 页面,并没有 API 服务,如果想要启动 API 服务的话,需要添加参数--api,这样启动后就可以通过{服务器IP}:7860/docs地址来访问 sd-webui 的 API 文档了。
1 | bash webui.sh --listen --enable-insecure-extension-access --api |
如果你想为 sd-webui 增加一些安全性,可以添加参数--gradio-auth,启动服务后用户只要访问{服务器IP}:7860就会看到一个登陆页面,需要输入用户名和密码才能访问。
1 | bash webui.sh --listen --enable-insecure-extension-access --api --gradio-auth {username}:{password} |
隐藏文字图片
在手动生成图片的过程中,我们主要使用的是 sd-webui 的文生图功能,这个功能对应的 API 接口是sdapi/v1/txt2img,它的请求方式是POST,请求参数有模型、正向提示词、负向提示词等等,返回的结果在images参数中,是一个列表,列表中的每个元素都是一个图片的 base64 编码,我们只需要将列表中的第一个元素保存成图片即可,示例代码如下:
1 | def generate_img() -> str: |
在示例代码中我们列举了手动生成图片的几个配置参数,其中模型参数sd_model_checkpoint的值可以通过另外一个接口sdapi/v1/sd-models来获取,更多的参数信息可以参考接口文档:
在请求参数中,我们除了要传 sd-webui 的基本参数外,还需要传入我们所用到的插件的参数,比如我们在之前示例中用到的 ControlNet 插件,那么我们就需要将 ControlNet 插件的配置加入到请求参数中,示例代码如下:
1 | data=json.dumps( |
sd-webui 插件的参数都放在alwayson_scripts中,每个插件以自己名称作为 key,ControlNet 插件的 key 是controlnet,下面的 args 数组是我们用到的 2 个 ControlNet Unit,然后是每个 Unit 的配置,这里我们列举了手动示例中的几个参数。其中的model参数的值可以通过另外一个接口controlnet/modelslist来获取,更多的参数可以参考ControlNet 插件的 API 文档。
其实每个插件都会将自己的接口信息会添加到 sd-webui API 的接口文档中,比如 ControlNet 插件就增加了以controlnet开头的几个接口,文档做得好的插件还会有自己的接口文档,通常放在插件仓库的 Wiki 中,比如 ControlNet 插件的接口文档就放在了这里。
input_image参数是我们上传的文字图片,我们需要将其转换成 base64 编码,图片文件转 base64 编码的示例方法如下:
1 | def image_to_base64(image_path: str) -> str: |
调用文生图接口生成图片后,我们可以将生成的图片保存到本地,示例代码如下:
1 | def saveImg(output_path="output.jpg", ): |
这样我们就实现了通过 API 方式生成隐藏文字图片的功能了,生成的图片保存在output.png文件中。
隐藏二维码图片
隐藏二维码图片的 API 实现方式与隐藏图片的实现方式基本相同,不同的地方是我们还用到另外一个 ADetailer 插件,这个插件的配置我们也需要一起放在请求参数中,示例代码如下:
1 | data=json.dumps( |
这里我们只添加了 ADetailer 插件中的模型参数,其他参数都用默认的,插件更多参数信息可以参考ADetailer 插件的 API 文档。
总结
以上就是通过 API 实现 Stable Diffusion 文字和二维码隐藏图片的全部过程,现在有一些 APP 已经实现了这些功能,比如字画幻术图等,如果觉得自己实现起来比较麻烦的话,也可以直接使用这些 APP 来生成图片,它们的实现原理都是一样的,都是通过 sd-webui API 的方式来实现。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。

