@register_tool defweb_search( query: Annotated[str, 'The query text to be queried', True], ) -> str: """ Search the result for input `query` from web """ from serpapi import GoogleSearch
try: query_result = search.get_dict() result = process_response(query_result) return result except: import traceback ret = "Error encountered while searching!\n" + traceback.format_exc()
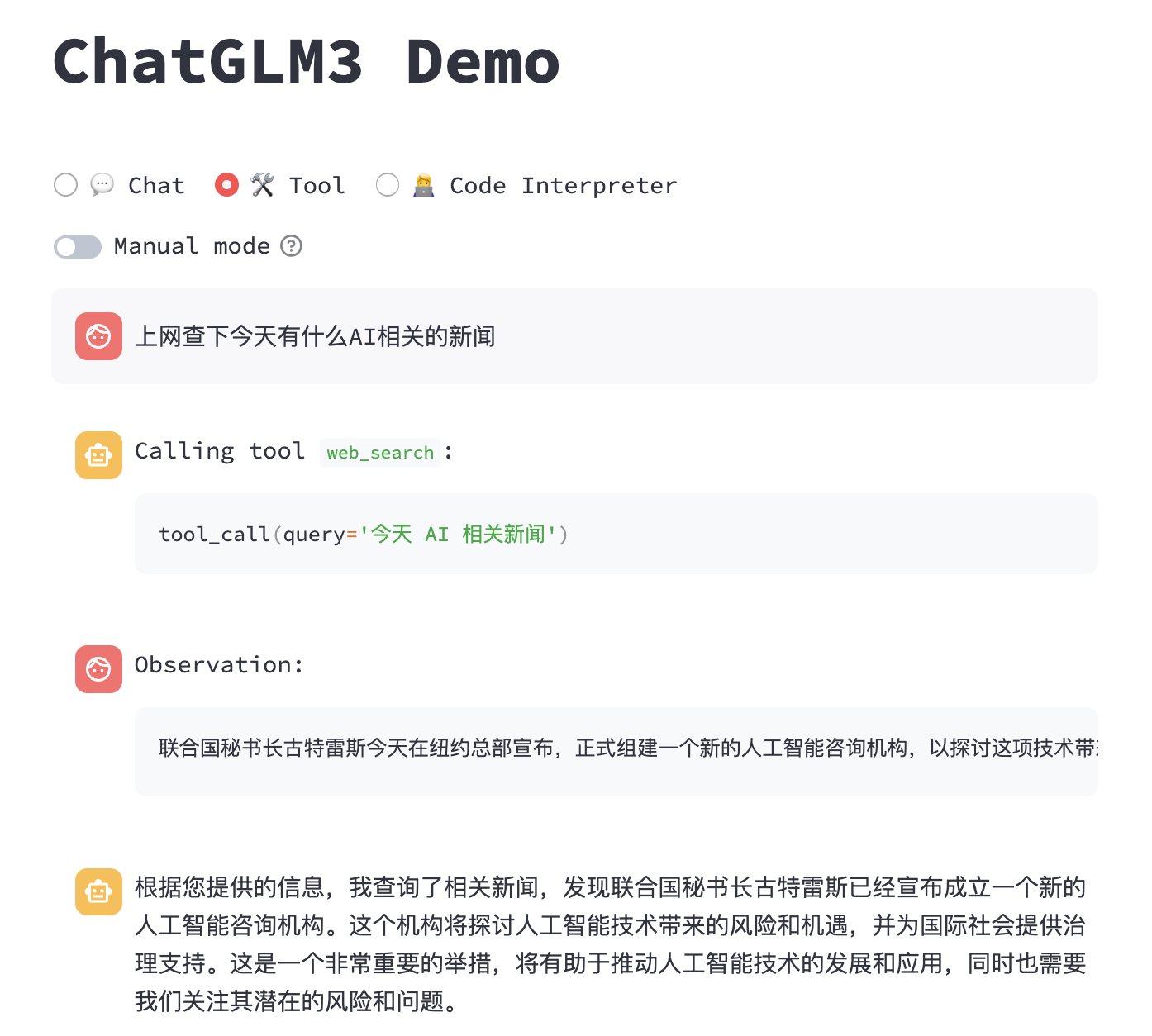
我们再来看如何在 API 接口中使用工具调用,在 API 请求参数messages的每个元素中,除了role和content外,还新增metadata和tools参数,metadata是具体工具名称,tools是可以用到的所有工具列表,其实 ChatGLM3 是参考了 ChatGPT 的Function Calling功能,这 2 个参数分别对应 Function Calling 的function_call和functions。
# 格式 1 tools = [ { "name": "get_weather", "description": "Get the current weather for `city_name`", "parameters": [ { "name": "city_name", "description": "The name of the city to be queried", "type": "str", "required": True } ] } ] # 格式 2 tools = [ { "name": "get_weather", "description": "Get the current weather for `city_name`", "parameters": { "type": "object", "properties": { "city_name": { "description": "The name of the city to be queried" } }, "required": ["city_name"] } } ]
system_info = { "role": "system", "content": "Answer the following questions as best as you can. You have access to the following tools:", "tools": tools, }
with markdown_placeholder: with st.spinner('Executing code...'): try: res_type, res = execute(code, get_kernel()) except Exception as e: st.error(f'Error when executing code: {e}') return print("Received:", res_type, res)
if res_type == 'text'andlen(res) > TRUNCATE_LENGTH: res = res[:TRUNCATE_LENGTH] + ' [TRUNCATED]'