使用 LlamaIndex 结合 Eleasticsearch 进行 RAG 检索增强生成

检索增强生成(Retrieval-Augmented Generation,RAG)是一种结合了检索(Retrieval)和生成(Generation)的技术,它有效地解决了大语言模型(LLM)的一些问题,比如幻觉、知识限制等。随着 RAG 技术的发展,RAG 涉及到的向量技术受到了大家的关注,向量数据库也慢慢被大家所了解,一些老牌的数据库厂商也纷纷表示支持向量检索,比如 Elasticsearch 也在最近的版本增加了向量检索的支持。本文将介绍 Elasticsearch 和 RAG 中相关的 Embedding 模型的部署,以及在 LLM 框架 LLamaIndex 中如何使用 Elasticsearch 进行文档索引入库和检索。
RAG 介绍
在使用 LLM 时我们经常会遇到这样一些情况,比如当我们的问题超出 LLM 的知识范围时,它要么解释说这个问题超出它的知识范围(这是 LLM 的知识限制),要么它会很自信地瞎编一些答案(这是我们所说的 LLM 幻觉)。
为了应对 LLM 的这些问题,RAG(检索增强生成)技术应运而生,RAG 的主要原理是将文档向量化后进行存储,在提出问题时将问题进行向量检索,检索出相关的文档,然后再将文档作为问题的上下文,一起发送给 LLM,让 LLM 来生成问题的答案,有了相关文档的支持,LLM 在内容的生成上就会参考这些文档,这样就可以有效地解决 LLM 的幻觉问题。同时,RAG 可以让 LLM 更快地了解到最新的信息,通常要让 LLM 了解到更新的信息,需要对 LLM 进行重新训练,训练方式不管是预训练还是微调,成本都是比较高的,而 RAG 只需要将最新的文档加入到数据库中即可,这样 LLM 就可以通过向量检索的方式来获取最新的信息。
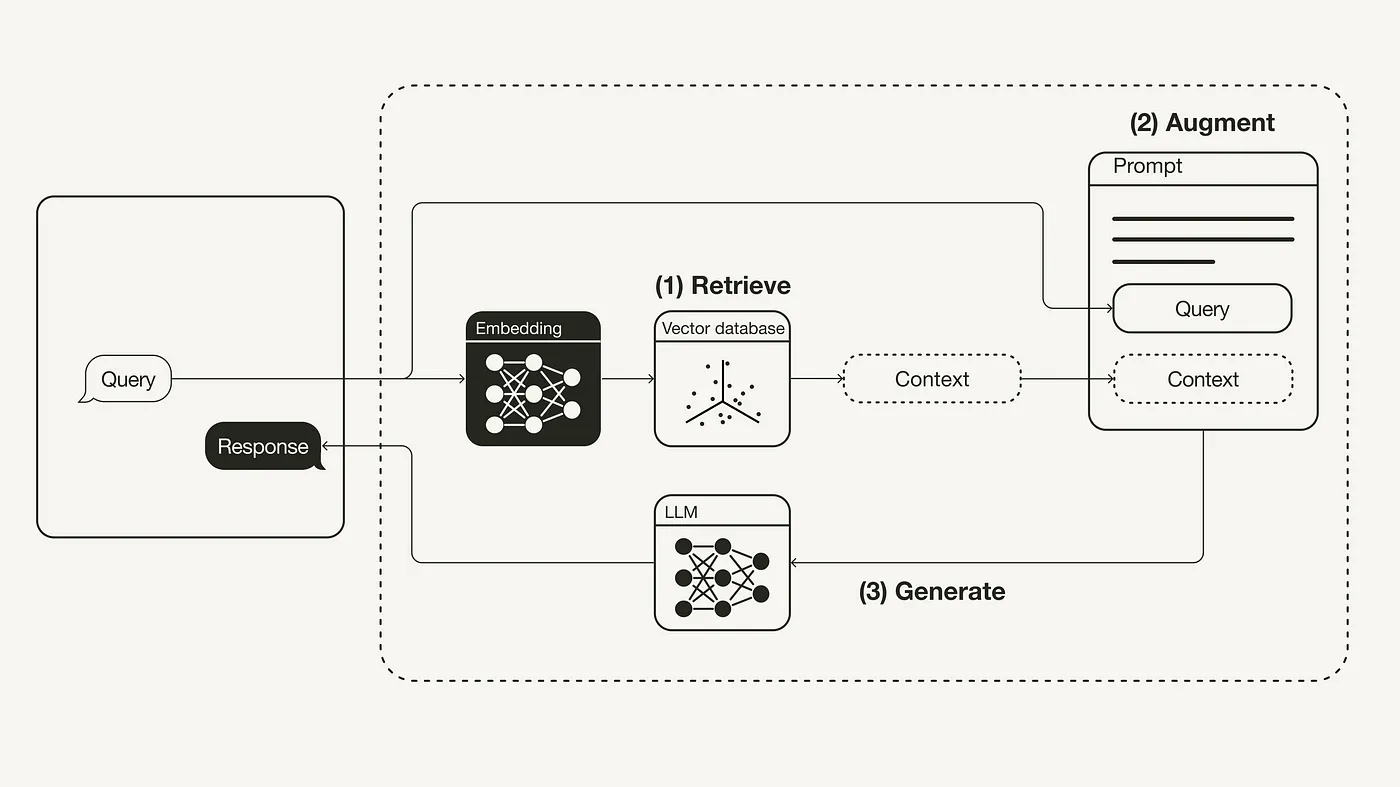
关键字检索和语义检索
RAG 的相关技术包括向量检索,也称为语义检索,它不同于传统的关键字检索,关键字检索依赖于在文档中查找与查询中使用的确切词汇匹配的单词或短语,它通常只关注字面上的匹配,而不考虑查询的上下文或语义含义,而语义检索旨在理解查询的意图和上下文含义,不仅仅是文字匹配,它通过分析词语的语义关系(如同义词、词义消歧)来提高检索的相关性。
举一个简单的例子,比如我们输入苹果 2024 新品发布,关键字检索可能返回关于苹果公司 2024 年的任何新闻发布,但也可能包括与水果苹果相关的新品种发布的信息,语义检索则会查找出关于苹果公司最新电子产品发布的新闻,而忽略与水果苹果相关的内容。
Elasitcsearch(以下简称 ES) 虽然一开始只是全文搜索引擎,也就是关键字检索,但是随着向量检索技术的发展,ES 也开始支持向量检索,这让 ES 成为了一个既可以做关键字检索,又可以做语义检索的数据库。下面我们就来介绍 ES 数据库的部署。
Elasticsearch 部署
部署 ES 最简单的方式是通过 Docker,首先需要安装 Docker,可以参考 Docker 的官方安装文档。
Docker 安装完成后开始安装 ES,我们需要使用 ES 的最新版本,因为最新的版本包括了向量检索的功能,目前最新的版本是8.11.3,安装启动命令如下:
1 | docker run -d --name es -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:8.11.3 |
使用docker run命令启动 ES 服务,-d参数表示以后台方式运行,--name参数表示容器的名称,-p参数表示端口映射,-e参数表示环境变量,elasticsearch:8.11.3表示使用elasticsearch相关版本的镜像。如果你是单机部署的话,可以不需要映射9300端口,这个端口主要用于 ES 集群内部节点之间的通信。
修改 ES 用户密码
ES 默认的配置会开启安全认证,这意味着在访问 ES 时需要通过用户名和密码认证,因此我们需要先获取到 ES 的用户名和密码,ES 的默认用户是elastic,如果不清楚该用户的密码,可以通过以下命令来重置用户密码:
1 | # 进入 ES 容器 |
在 ES 容器中我们通过elasticsearch-reset-password命令来重置elastic用户的密码,重置完成后,我们可以通过在浏览器中输入https://localhost:9200来访问 ES(注意 url 地址是 https,不是 http,后面会讲如何关闭 https),首次访问时会提示你输入用户名和密码:
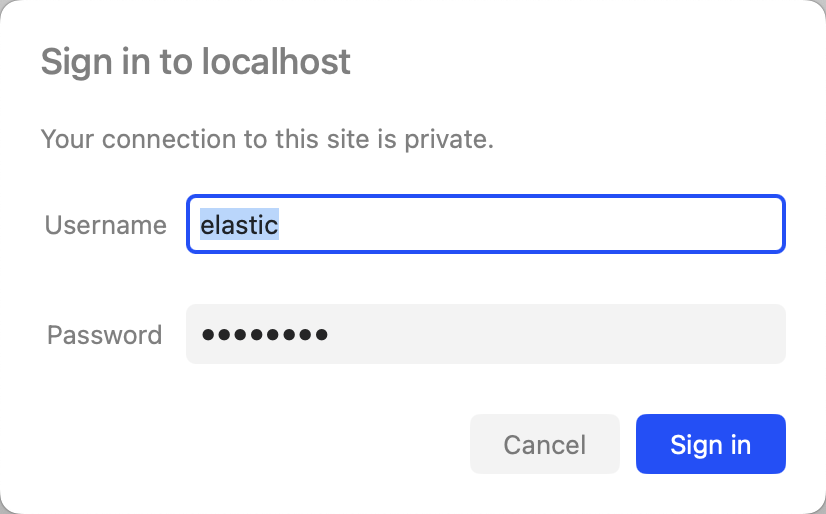
输入用户名和密码后,我们就可以看到 ES 相关的 JSON 信息。
关闭 ES SSL 认证
ES 为了加强系统的安全性,会默认开启 SSL 认证,在访问 ES 时需要使用 HTTPS 协议,但如果我们只是本地使用的话不太需要这种级别的安全认证,因此我们可以关闭 ES 的 SSL 认证,关闭 SSL 认证的需要修改 ES 的配置文件elascitsearch.yml。修改该文件我们先要将 ES 默认的配置文件拷贝到本地磁盘,然后修改配置文件,最后在 ES 容器启动时挂载修改后的配置文件。
首先我们将刚才启动的 ES 容器中的配置目录拷贝到本地磁盘,然后原来的 ES 容器就可以关闭了,命令如下:
1 | # 拷贝配置文件 |
config文件夹包含了elascitsearch.yml和其他配置文件,然后我们修改elascitsearch.yml文件来关闭 SSL 认证,修改内容如下:
1 | # Enable encryption for HTTP API client connections, such as Kibana, Logstash, and Agents |
修改完成后,我们需要重新运行一个新的 ES 容器,并将修改后的配置文件挂载到容器中,命令如下:
1 | docker run -d --name es -p 9200:9200 -p 9300:9300 -v "$PWD/config":/usr/share/elasticsearch/config -e "discovery.type=single-node" elasticsearch:8.11.3 |
等容器启动后,我们就可以通过http://localhost:9200来访问 ES 了。这里要注意的是因为重新部署了 ES 容器,所以刚才修改的用户密码也会失效,需要重新重置用户密码。
ES 监控工具
想要查看 ES 中的数据,如果是使用命令行工具的话可能不太方便,因此我们需要一个 GUI 工具,这里推荐elasticvue,一个基于浏览器的 ES GUI 工具,安装也非常简单,同样是使用 docker 来进行安装:
1 | docker run -p 9080:8080 --name elasticvue -d cars10/elasticvue |
然后我们在浏览器中输入http://localhost:9080来访问 elasticvue,进到首页后点击ADD ELASTICSEARCH CLUSTER按钮,可以看到如下界面:
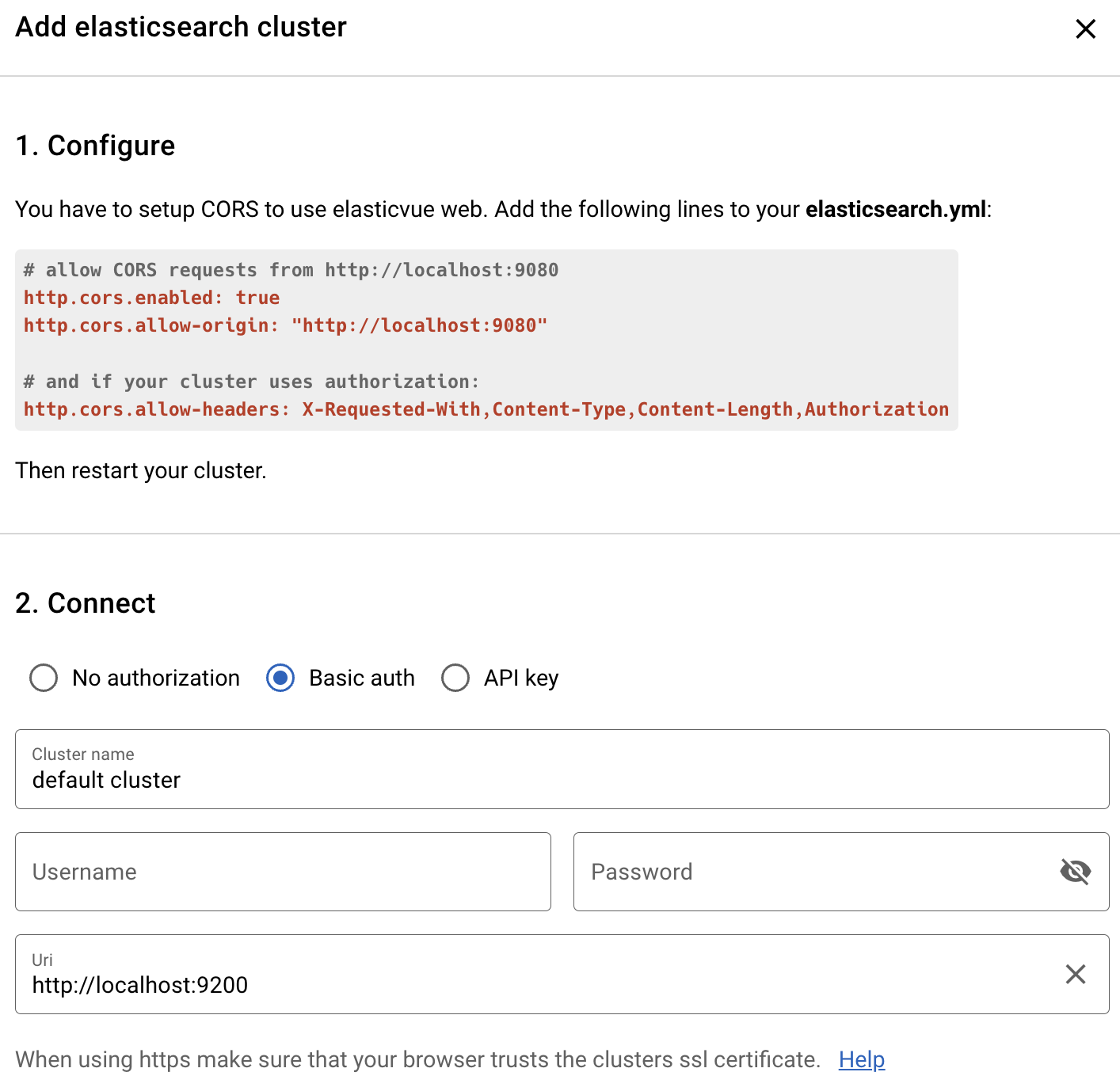
根据上图上半部分的Configure提示,需要修改 ES 的配置文件elascitsearch.yml以接入 elasticvue,修改内容可以参考图中的Configure部分,修改完后重启 ES 容器即可。
1 | docker restart es |
然后在 elasticvue 中添加 ES 集群,输入 ES 的地址http://localhost:9200,选择Basic auth输入用户名和密码,这样就可以连上我们的 ES 服务了。
Embedding 模型部署
向量检索的核心是向量,而向量是由 Embedding 模型生成的,我们可以使用一些线上的 Embedding 模型,比如 OpenAI 的 Embedding 模型,也可以自己部署 Embedding 模型。这里我们选择部署自己的 Embedding 模型,我们使用 BAAI/bge-base-en-v1.5 模型,这是一个英文 Embedding 模型,可以用于英文的向量生成。
我们使用 FastChat 来部署 Embedding 模型,FastChat 是一个模型训练、部署、评估的开发平台,不仅支持 LLM 模型,还支持 Embedding 模型,下面来介绍如何使用 FastChat 部署 Embedding 模型。
首先我们要安装 FastChat,然后通过 FastChat 来部署一个兼容 OpenAI API 的 Embedding API 服务,安装命令如下:
1 | pip3 install "fschat[model_worker,api]" |
安装完成后,先使用 FastChat 的命令行工具来启动 controller 服务,命令如下:
1 | $ python3 -m fastchat.serve.controller --host 0.0.0.0 |
然后重新打开一个终端,使用 FastChat 的命令行工具来启动 worker 服务,命令如下:
1 | $ python3 -m fastchat.serve.model_worker --model-path BAAI/bge-base-en-v1.5 --host 0.0.0.0 |
执行命令后,FastChat 会自动从 huggingface 上下载 BAAI/bge-base-en-v1.5 模型,下载完成后就会启动 worker 服务,worker 服务会自动连接到 controller 服务。
我们再打开一个终端,使用 FastChat 的命令行工具来启动 兼容 OpenAI API 的 API 服务,命令如下:
1 | $ python3 -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 8000 |
服务启动后,我们可以访问http://localhost:8000/docs来查看 API 服务的 swagger 文档:
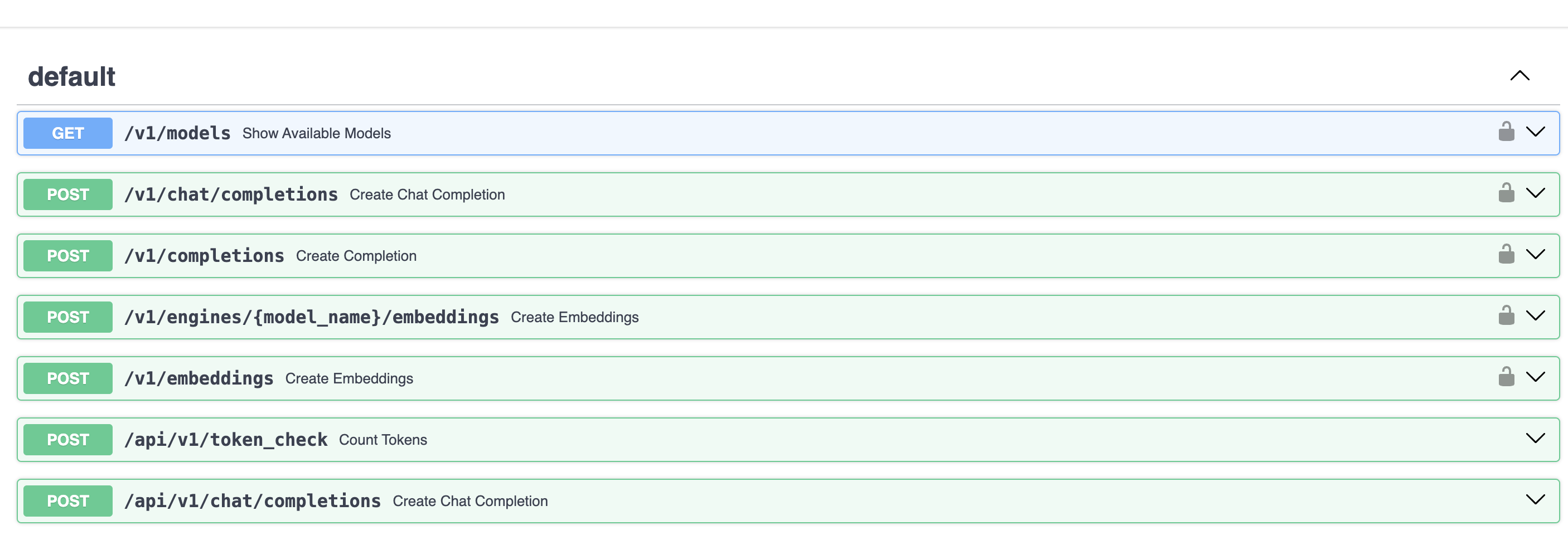
可以看到图中的/v1/embeddings接口就是我们需要调用的 Embedding 接口,我们可以通过 curl 命令来测试一下该接口,命令如下:
1 | curl -X 'POST' \ |
我们在请求参数中输入模型名称和需要被向量化的文本,命令执行完成后,我们可以看到返回的结果包含了 embedding 后的向量数据,并且返回格式跟 OpenAI API 的格式是一样的。
FastChat 更多的相关部署内容可以参考 FastChat 的文档。
LlamaIndex 文件加载与检索
LlamaIndex 是继 LangChain 之后另外一个 LLM 应用开发框架,整体功能以 RAG 为主,现在也慢慢在开发一些 Agent 相关的功能。该框架的主要编程语言是 Python,具有广泛的社区支持和贡献,包括众多的 forks 和 stars,表明其在开发社区中的受欢迎程度和实用性。
下面我们来介绍使用 LlamaIndex 结合 ES 进行文档加载与检索,在开始编写代码之前,我们需要安装 LlamaIndex 和 ES 的 Python 包,命令如下:
1 | pip install llama-index elasticsearch |
Embedding 自定义类
安装完依赖包后,我们开始编写相关代码,首先我们需要创建一个自定义的 Embedding 类,这个 Embedding 类会调用我们刚才部署的 Embedding API 接口来实现文本的向量化,代码如下:
1 | from llama_index.embeddings.base import BaseEmbedding, Embedding |
- 使用 LlamaIndex 实现自定义的 Embedding 类,需要继承 BaseEmbedding 类,并实现相关的方法
- 这里我们实现了
_aget_query_embedding、_aget_text_embedding、_get_query_embedding、_get_text_embedding、_get_text_embeddings这几个方法,这几个方法会调用其他公共方法来实现文本转向量的功能。
我们再来看一下get_embedding和get_embeddings这两个方法的实现,代码如下:
1 | import requests |
get_embedding和get_embeddings都使用send_request来获取文本的向量数据,不同的地方在于一个参数是字符串,一个参数是字符串数组send_request方法会发起 HTTP 请求调用 Embedding API 接口来实现文本向量化- 参考之前的 API 返回结果,Embedding 向量保存在一个数组中
get_embedding获取返回结果的第一个向量数据,get_embeddings获取所有的向量数据
向量化文档
有了自定义 Embedding 类,我们就可以使用 LlamaIndex 来实现文档的向量存储了,首先我们连接 ES 数据库,代码如下:
1 | from llama_index.vector_stores import ElasticsearchStore |
- 新建一个 ES store 来连接 ES,需要指定 ES 的地址和索引名称
- ES 如果开启了安全认证,需要在 ES 的地址中添加用户名和密码
- 使用 LlamaIndex 的 StorageContext 来集成 ES 的 store
我们再定义带有 Embedding 模型的 ServiceContext,代码如下:
1 | from llama_index import ServiceContext |
- embedding_model_url 是我们刚才部署的 Embedding API 的地址,model_name 是模型名称
接着我们来将文档转换为 LlamaIndex 的 Document 对象,我们可以使用 LlamaIndex 的示例文档paul_graham_essay来做演示,这篇文章是 Paul Graham 关于他个人生涯和工作经历的回顾,代码如下:
1 | from llama_index import SimpleDirectoryReader |
- SimpleDirectoryReader 对象可以对文件夹中的文件进行解析,txt 文件的解析不需要额外的依赖,但如果是其他格式的文件,比如 pdf,则需要安装相关的依赖 pypdf
我们将以上的对象组装在一起,示例代码如下:
1 | from llama_index import VectorStoreIndex |
- 使用 VectorStoreIndex 集成 storage_context 和 service_context,并加载 documents
- 不需要担心 ES 的索引是否已创建,如果没有该索引,LlamaIndex 会自动创建
代码执行后,我们就可以在 ES 中看到索引的文档了,我们通过 elasticvue 来查看索引的文档,如下图所示:
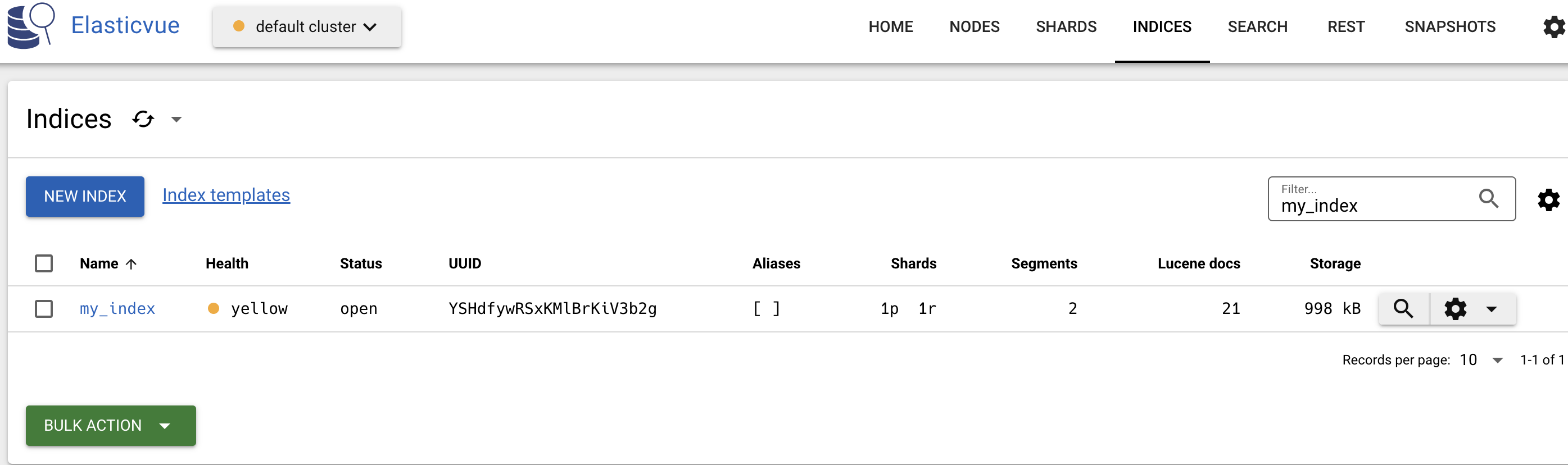
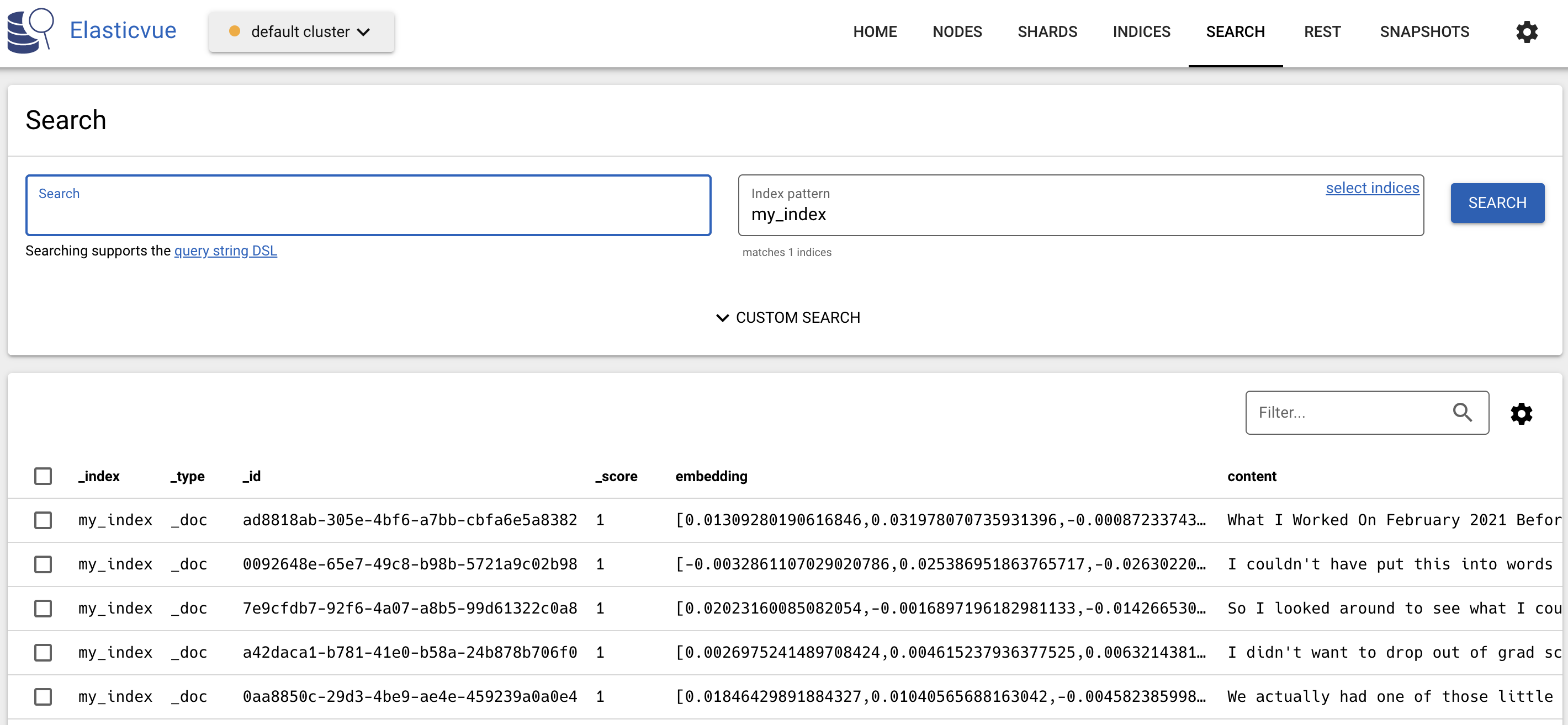
除了可以对整个文件夹进行加载外,我们还可以在已有的索引中添加新的文档,代码如下:
1 | filepath = "./data/paul_graham_essay.txt" |
- 在 VectorStoreIndex 中传入 ES store 来加载已有的 ES 索引
- SimpleDirectoryReader 也可以传入单个文件路径,这样就可以加载单个文件
- 使用 VectorStoreIndex 的 insert 方法来添加新的文档
问题检索与生成
接下来我们再使用 LlamaIndex 来对问题进行检索,代码如下:
1 | query_engine = index.as_query_engine() |
- LlamaIndex 默认使用 OpenAI 的 LLM 来做生成,因此在执行代码之前,需要将 OPENAI_API_KEY 环境变量设置为你的 API KEY
我们询问了一个关于作者成长经历的问题,LlamaIndex 会先使用向量检索来检索相关的文档,然后再使用 LLM 来生成答案,我们可以看到 LlamaIndex 生成的答案是正确的。
如果我们将 LlamaIndex 中的 LLM 取消,那么 response 的结果会变成结合了相关文档的提示词模板,如下所示:
1 | service_context = ServiceContext.from_defaults( |
- 只需在 ServiceContext 中添加参数
llm=none即可取消默认的 OpenAI LLM - 其他代码与原来的一样
可以看到同样的问题,不使用 LLM 的情况下返回的结果是一个包含了相关文档的提示词模板。
在 response 对象中,我们还可以通过response.source_nodes可以获取到检索到的文档信息,文档的 JSON 信息如下:
1 | { |
- 可以看到 LlamaIndex 根据问题检索出 2 个 Node(可以把 Node 理解成文档的分块)
- 每个 Node 有文本内容 text,匹配分数 score 等属性
LlamaIndex 默认是使用向量检索,我们也可以将其替换为其他检索方式,代码如下:
1 | from llama_index.vector_stores.types import VectorStoreQueryMode |
更多的 LlamaIndex 用法可以参考官方文档。
总结
RAG 是 LLM 技术的一个重要方向,它不仅可以解决 LLM 中存在的一些问题,而且可以帮助我们打造更高质量的 LLM 应用。本文从 ES 和 Embedding 模型的部署一步步展开,结合 LLM 框架 LlamaIndex 来实现 RAG 的检索增强生成,并介绍了在实践过程中相关的原理和注意事项。希望本文能够帮助大家更好地理解 RAG 技术,如果对文章内容有疑问或者建议,欢迎在评论区留言。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。

