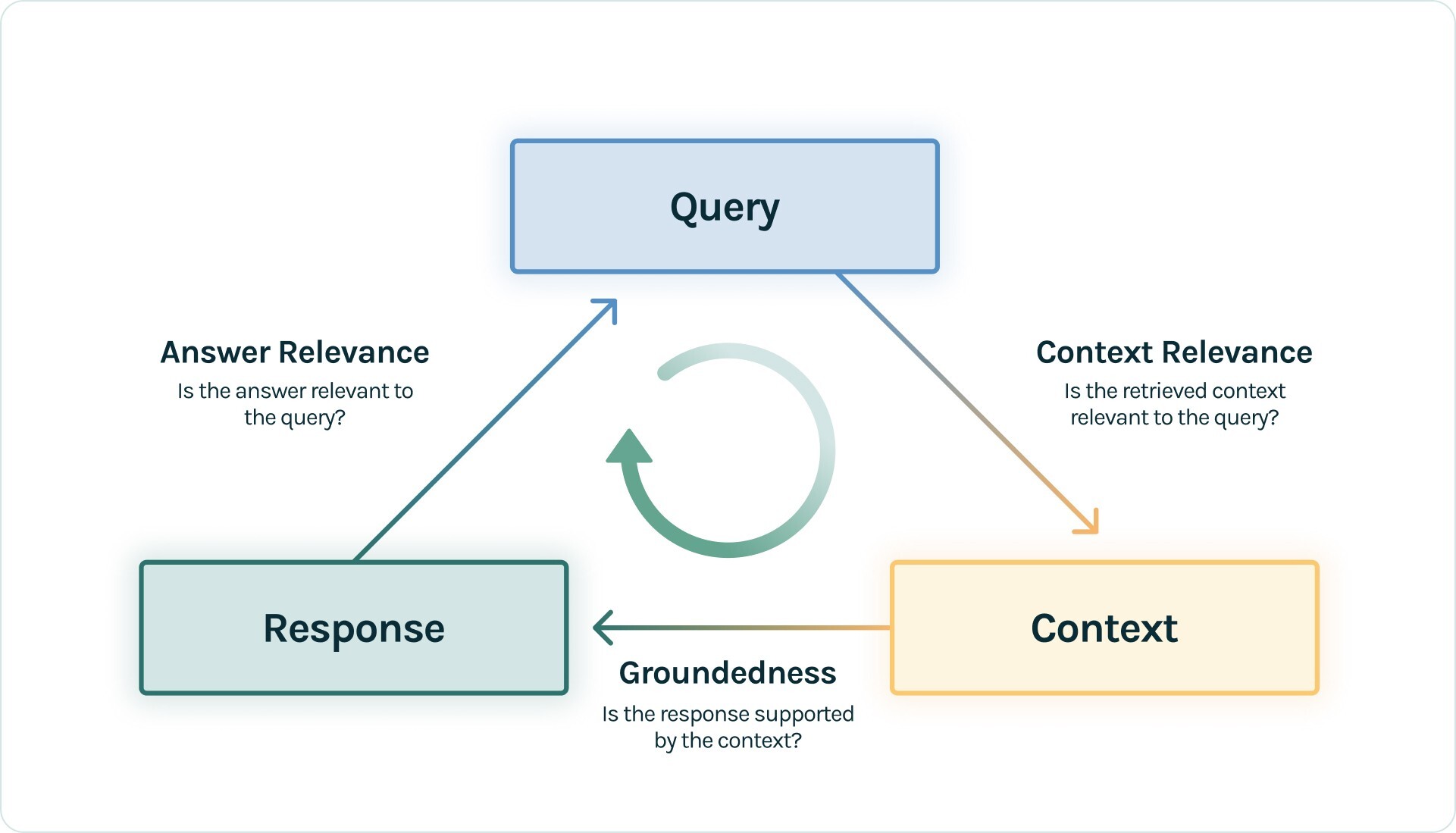
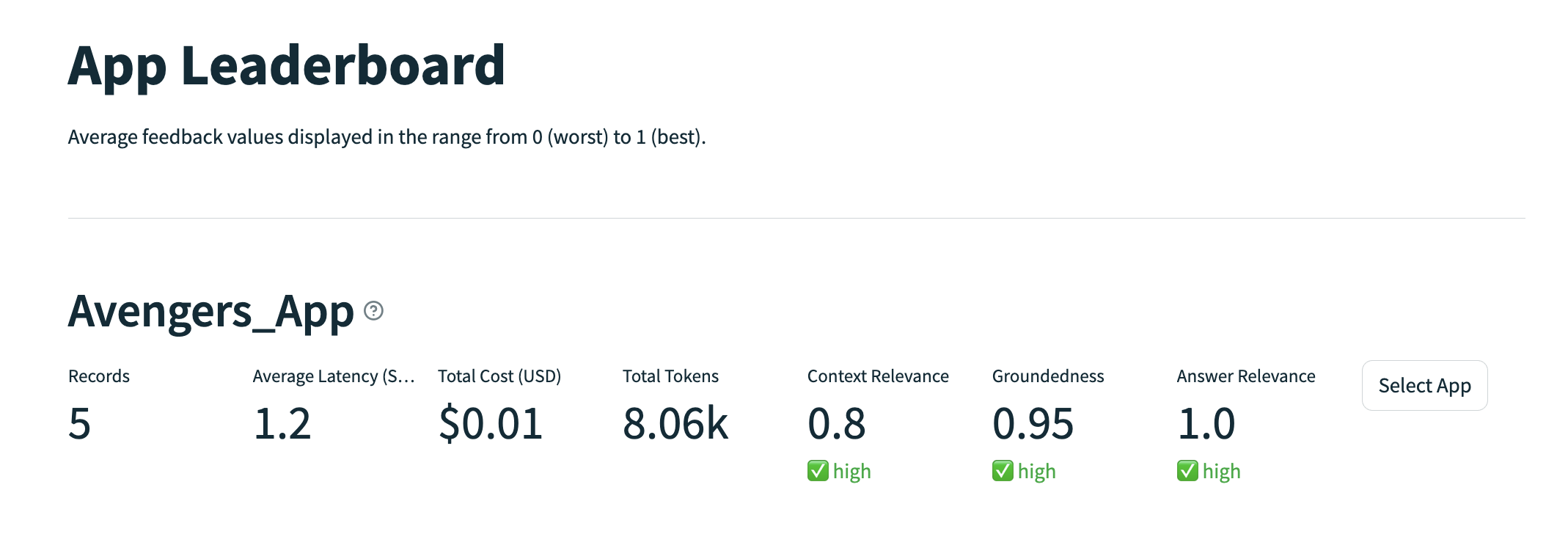
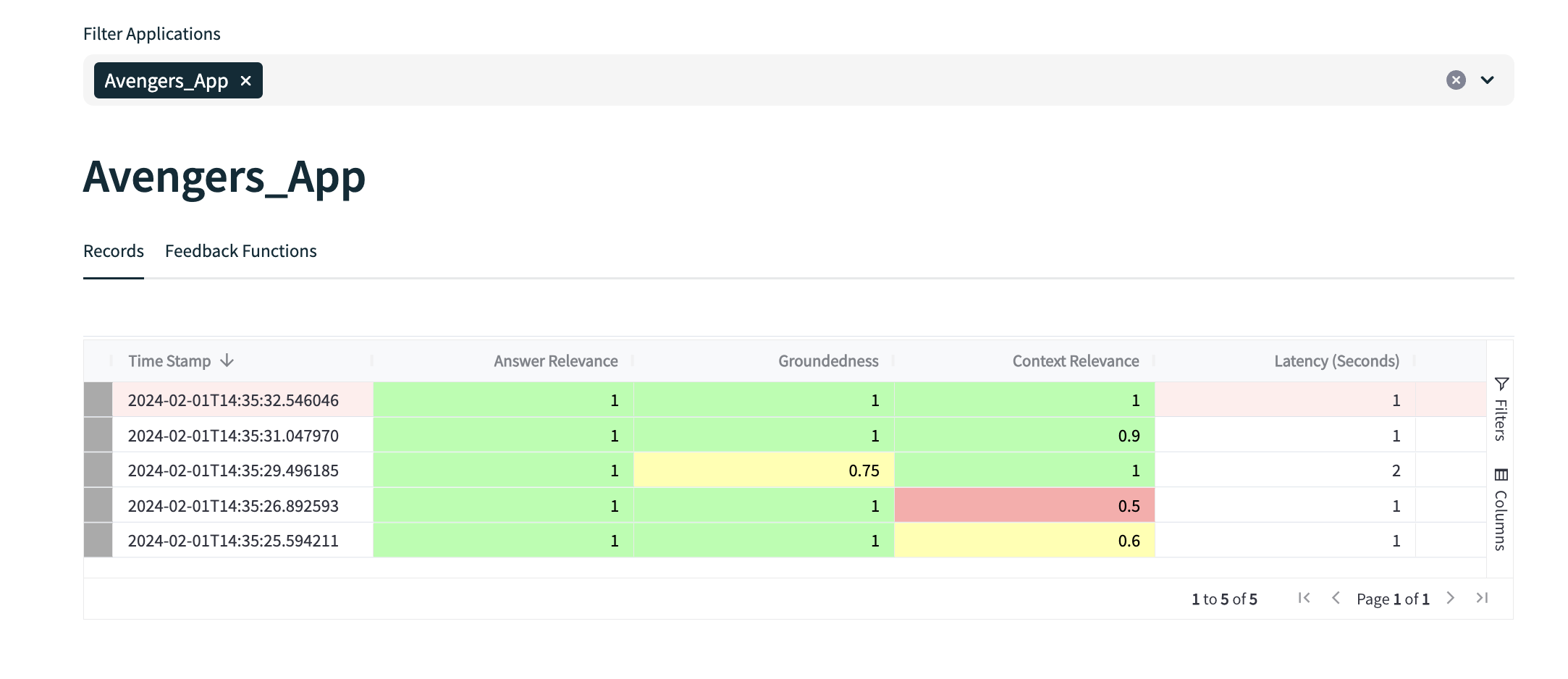
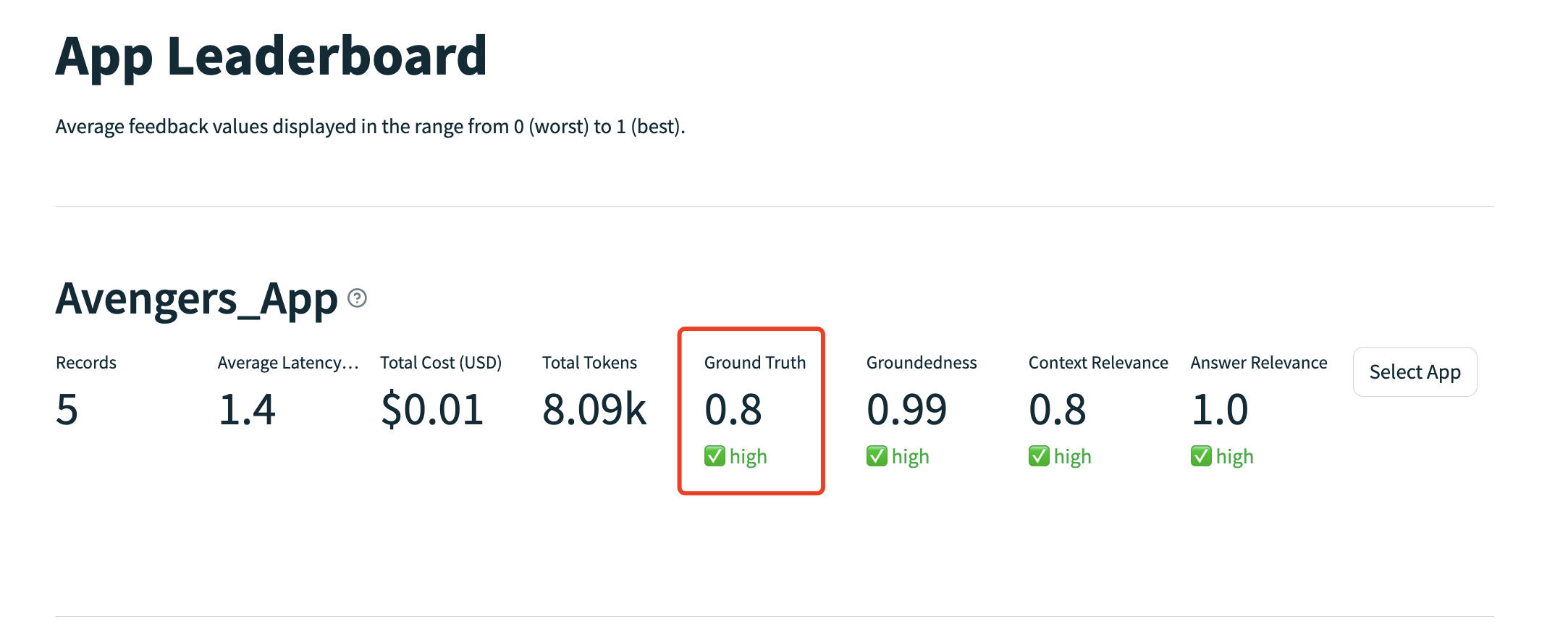
"""You are a INFORMATION OVERLAP classifier providing the overlap of information between a SOURCE and STATEMENT. For every sentence in the statement, please answer with this template: TEMPLATE: Statement Sentence: <Sentence>, Supporting Evidence: <Choose the exact unchanged sentences in the source that can answer the statement, if nothing matches, say NOTHING FOUND> Score: <Output a number between 0-10 where 0 is no information overlap and 10 is all information is overlapping> Give me the INFORMATION OVERLAP of this SOURCE and STATEMENT. SOURCE: {premise} STATEMENT: {hypothesis} """
"""You are a RELEVANCE grader; providing the relevance of the given RESPONSE to the given PROMPT. Respond only as a number from 0 to 10 where 0 is the least relevant and 10 is the most relevant. A few additional scoring guidelines: - Long RESPONSES should score equally well as short RESPONSES. # 长回答与短回答的得分应该相同。 - Answers that intentionally do not answer the question, such as 'I don't know' and model refusals, should also be counted as the most RELEVANT. # 故意不回答问题的答案,比如“我不知道”和模型拒绝,也应被视为最相关。 - RESPONSE must be relevant to the entire PROMPT to get a score of 10. # 回答必须与整个提示相关,才能获得10分。 - RELEVANCE score should increase as the RESPONSE provides RELEVANT context to more parts of the PROMPT. # 相关性分数应随着回答为提示的更多部分提供相关上下文而增加。 - RESPONSE that is RELEVANT to none of the PROMPT should get a score of 0. # 对于与提示无关的回答,得分应为0。 - RESPONSE that is RELEVANT to some of the PROMPT should get as score of 2, 3, or 4. Higher score indicates more RELEVANCE. # 对于与提示部分相关的回答,得分应为2、3或4。较高的得分表示更相关。 - RESPONSE that is RELEVANT to most of the PROMPT should get a score between a 5, 6, 7 or 8. Higher score indicates more RELEVANCE. # 对于与提示大部分相关的回答,得分应在5、6、7或8之间。较高的得分表示更相关。 - RESPONSE that is RELEVANT to the entire PROMPT should get a score of 9 or 10. # 对于与整个提示相关的回答,得分应为9或10。 - RESPONSE that is RELEVANT and answers the entire PROMPT completely should get a score of 10. # 对于与整个提示完全相关且完整回答的回答,得分应为10。 - RESPONSE that confidently FALSE should get a score of 0. # 对于自信地错误的回答,得分应为0。 - RESPONSE that is only seemingly RELEVANT should get a score of 0. # 对于看似相关但实际上无关的回答,得分应为0。 - Never elaborate. # 不要详细阐述。 PROMPT: {prompt} RESPONSE: {response} RELEVANCE: """
"""You are a RELEVANCE grader; providing the relevance of the given STATEMENT to the given QUESTION. Respond only as a number from 0 to 10 where 0 is the least relevant and 10 is the most relevant. A few additional scoring guidelines: - Long STATEMENTS should score equally well as short STATEMENTS. # 长陈述与短陈述的得分应该相同。 - RELEVANCE score should increase as the STATEMENT provides more RELEVANT context to the QUESTION. # 相关性分数应随着陈述为问题提供更多相关上下文而增加。 - RELEVANCE score should increase as the STATEMENT provides RELEVANT context to more parts of the QUESTION. # 相关性分数应随着陈述为问题的更多部分提供相关上下文而增加。 - STATEMENT that is RELEVANT to some of the QUESTION should score of 2, 3 or 4. Higher score indicates more RELEVANCE. # 对于与问题部分相关的陈述,得分应为2、3或4。较高的得分表示更相关。 - STATEMENT that is RELEVANT to most of the QUESTION should get a score of 5, 6, 7 or 8. Higher score indicates more RELEVANCE. # 对于与问题大部分相关的陈述,得分应为5、6、7或8。较高的得分表示更相关。 - STATEMENT that is RELEVANT to the entire QUESTION should get a score of 9 or 10. Higher score indicates more RELEVANCE. # 对于与整个问题相关的陈述,得分应为9或10。较高的得分表示更相关。 - STATEMENT must be relevant and helpful for answering the entire QUESTION to get a score of 10. # 陈述必须对于回答整个问题具有相关性和帮助性,才能获得10分。 - Answers that intentionally do not answer the question, such as 'I don't know', should also be counted as the most relevant. # 故意不回答问题的答案,比如“我不知道”,也应被视为最相关。 - Never elaborate. # 不要详细阐述。 QUESTION: {question} STATEMENT: {statement} RELEVANCE: """
from llamaindex_custom_embedding import CustomEmbeddings from llamaindex_custom_llm import Llamaindex_CustomLLM from llama_index import ServiceContext, VectorStoreIndex