高级 RAG 检索策略之自动合并检索

之前介绍了高级 RAG 检索的句子窗口检索策略,今天我们再来介绍另外一种高级检索策略——自动合并检索,它比句子窗口要复杂一些,但请不用担心,下面的介绍会让你理解其中原理,同时会介绍如何使用 LlamaIndex 来构建一个自动合并检索,最后使用 Trulens 来对检索效果进行评估,并与之前的检索策略进行对比。
自动合并检索介绍
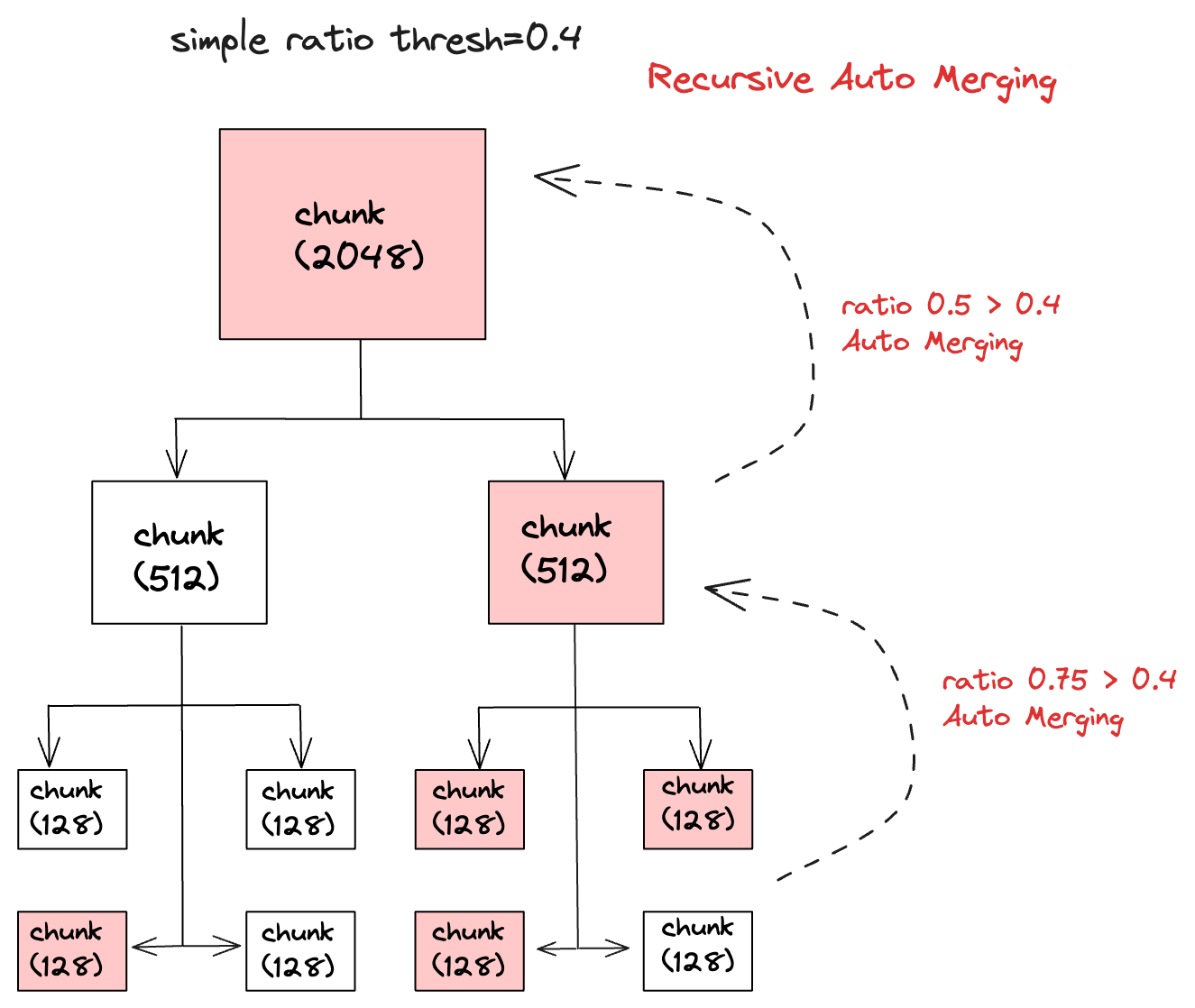
自动合并检索主要是将文档按照块大小拆分成不同层级的节点,这些节点包括父节点和子节点,然后在检索过程中找到相似度高的叶子节点,如果一个父节点中有多个子节点被检索到,那么这个父节点就会被自动合并,最终将父节点的所有文档都作为上下文发送给 LLM(大语言模型),下面是自动合并检索的示意图:
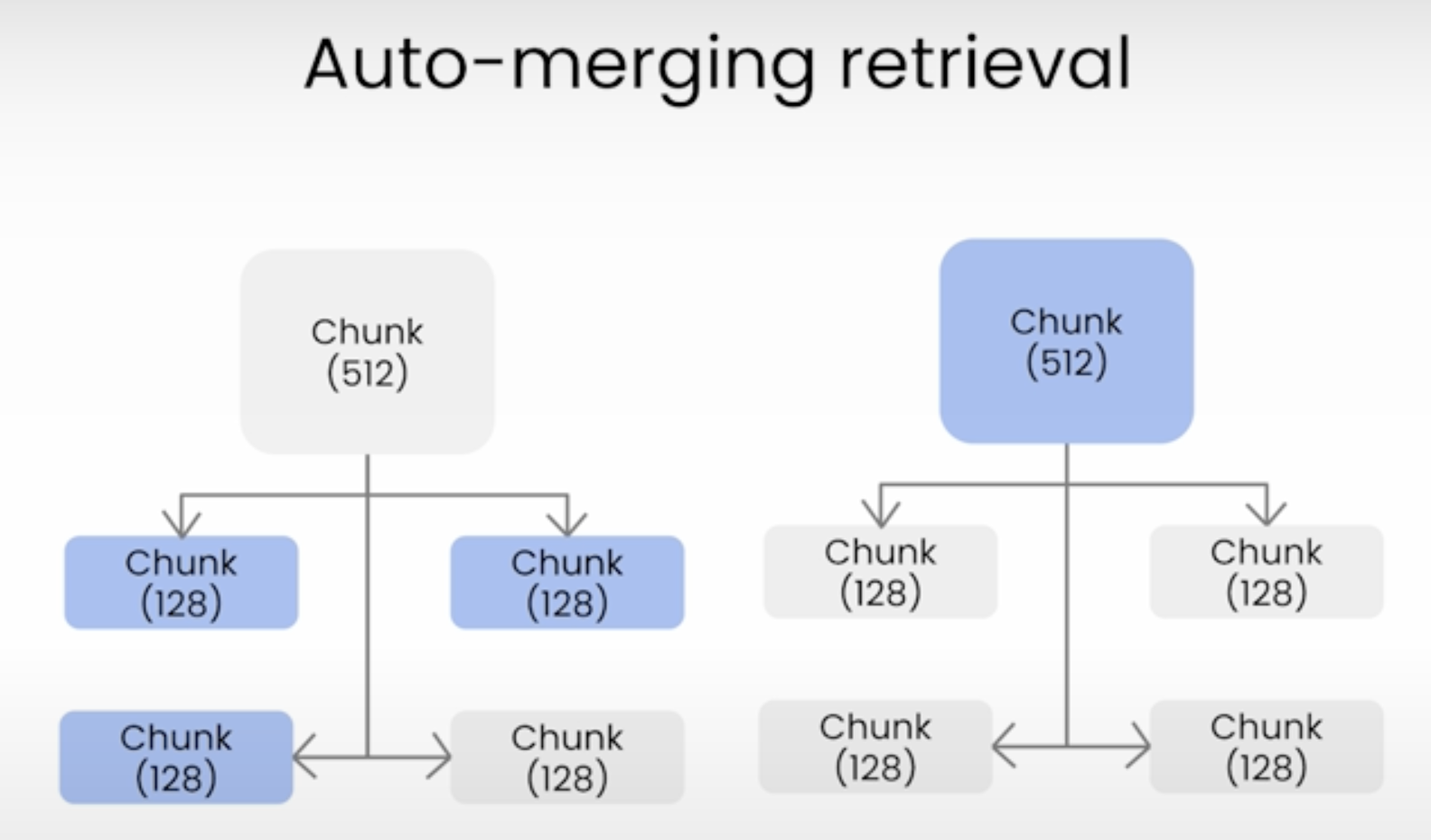
自动合并检索是 LlamaIndex 中的一种高级检索功能,主要有文档拆分和文档合并两个过程,下面我们将通过代码来讲解其中的原理。
文档拆分
在构建一个自动合并检索时,我们首先要创建一个 HierarchicalNodeParser 文档解析器:
1 | from llama_index.core import SimpleDirectoryReader |
- 首先我们从
data目录中加载文档,这个目录的文档是我们我们之前使用的维基百科上的复仇者联盟电影剧情 - 然后我们创建一个
HierarchicalNodeParser文档解析器,并设置chunk_sizes为[2048, 512, 128] - 再使用文档解析器将文档解析成节点
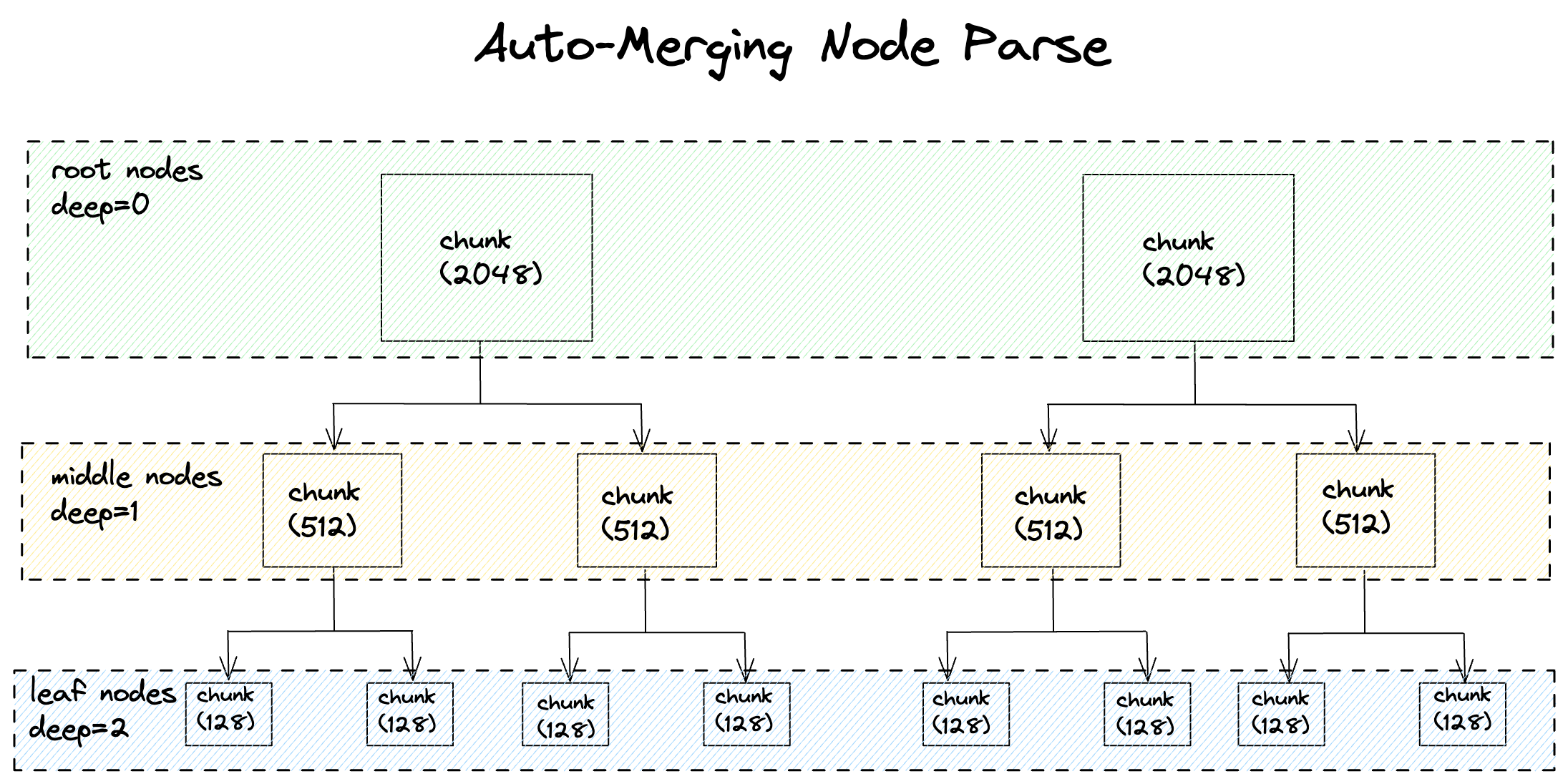
HierarchicalNodeParser 解析器中的参数chunk_sizes默认值是[2048, 512, 128],这表示将文档拆分成 3 个层级,第一个层级的文档大小为 2048,第二个层级的文档大小为 512,第三个层级的文档大小为 128。当然你也可以将层级设置为更少或者更多,比如设置成 2 级,那么chunk_sizes可以是[1024, 128],或者 4 级[2048, 1024, 512, 128]。文档拆分的越小,检索的准确度就会越高,但同时也会造成合并的概率降低,需要根据评估结果来进行调整。
获取根节点和叶子节点
LlamaIndex 提供了几个工具函数来帮助我们获取节点中不同层级的节点,首先我们看下如何获取根节点和叶子节点:
1 | from llama_index.core.node_parser import get_leaf_nodes, get_root_nodes |
get_leaf_nodes和get_root_nodes这 2 个方法都是传入一个节点列表- 可以看到总的节点数是 66,根节点是 4,叶子节点是 52
- 根节点加上叶子节点的总数是 56(4+52),和总节点数 66 并不匹配,所以剩下的节点是中间层级的节点,我们可以推算出中间节点数是 10(66-56)
- 如果你的文档层级是 2 级,那么根节点和叶子节点数加起来的总数就等于总节点数
获取不同层级节点
我们再用其他工具函数来验证我们的推理是否正确,这里我们需要使用到 get_deeper_nodes 函数:
1 | from llama_index.core.node_parser import get_deeper_nodes |
- get_deeper_nodes 方法第一个参数是节点列表,第二参数是要查询的层级,0 表示第 1 层级,也就是根节点
可以看到deep0节点数是 4,相当是根节点,deep2的节点数是 52,相当是叶子节点,而deep1就是中间层级的节点,共有 10 个,和我们推理的结果是一致的。
获取子节点
LlamaIndex 还提供了 get_child_nodes 函数来获取节点的子节点:
1 | from llama_index.core.node_parser import get_child_nodes |
- get_child_nodes 方法第一个参数是要获取子节点的节点列表,第二个参数是所有节点
- 这里我们先获取根节点下的所有子节点,得到 10 个子节点,这些节点也就是中间层级节点
- 然后我们再获取这些中间节点下的所有子节点,得到 52 个子节点,这些节点也就是叶子节点
当然我们也可以获取某个节点下的子节点,比如获取第一个根节点的子节点:
1 | root0_child_nodes = get_child_nodes(root_nodes[0], all_nodes=nodes) |
这表示第一个根节点下有两个子节点,这 2 个子节点也是中间层级节点。
节点文档内容
每个父节点的文档内容包含了它所有子节点的文档内容:
1 | print(f"deep1[0] node: {deep1_nodes[0].text}") |
- 我们首先打印中间层级第一个节点的文档内容
- 然后再获取这个中间节点第一个子节点,并打印其文档内容
- 可以看到父节点的文档内容包含了子节点的文档内容
文档合并
文档合并是自动合并检索的重要组成部分,文档合并的效果决定了提交给 LLM 的上下文内容,从而影响了最终的生成结果。
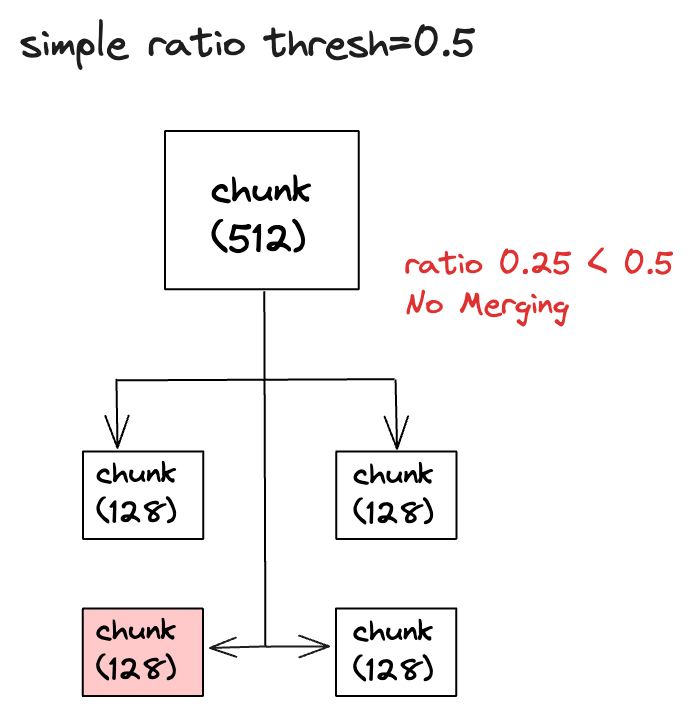
首先自动合并检索会根据问题对所有叶子节点进行检索,这使得检索的准确率比较高,在自动合并检索中有一个参数叫simple_ratio_thresh,它的默认值是 0.5,表示自动合并文档的阀值,如果在一个父节点中,子节点被检索到的比例小于这个阀值,那么自动合并功能将不会生效,这样提交给 LLM 的上下文就只会包含检索到的叶子节点。反之如果大于这个阀值,文档就会自动合并,最终提交给 LLM 的上下文就会包含这个父节点的内容。
比如父节点有 4 个子节点,检索时发现只有 1 个子节点,那么子节点被检索到的比例就是 0.25(1/4),小于阀值 0.5,所以自动合并功能不会生效,最终提交给 LLM 的上下文就只会包含那个检索到的子节点。
如果父节点有 4 个子节点,检索时发现有 3 个子节点,那么子节点被检索到的比例就是 0.75(3/4),大于阀值 0.5,所以自动合并功能会生效,最终提交给 LLM 的上下文就是父节点的内容。
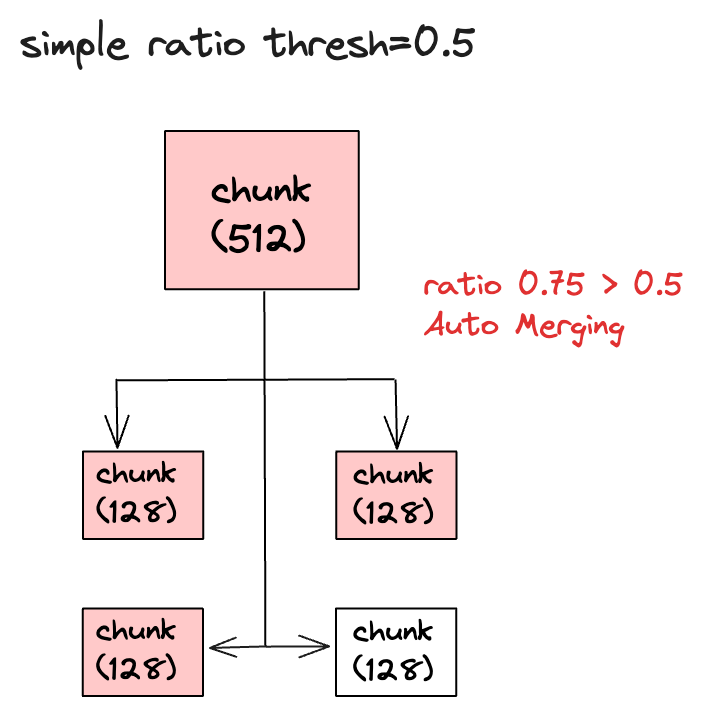
而且自动合并的功能是一个不断重复的过程,这表示自动合并会从最底层的节点开始合并,然后一直合并到最顶层的节点,最终得到所有合并后的文档,重复的次数取决于文档解析器拆分文档的层级和达到阀值的父节点数,比如chunk_sizes是[2048, 512, 128],那么文档拆分后的层级是 3,如果拆分后的文档数从下到上如果是 4-2-1,并且每一层的自动合并都被触发的话,那么总共就会自动合并 2 次。
自动合并使用
下面我们再来看看自动合并检索在实际 RAG 项目中的使用,文档数据我们还是使用之前维基百科上的复仇者联盟电影剧情来进行测试。
自动合并检索示例
我们来看下如何使用 LlamaIndex 构建自动合并检索:
1 | from llama_index.core.node_parser import ( |
- 首先我们定义了
HierarchicalNodeParser文档解析器来解析文档,这在前面已经介绍过了,这里不再赘述 - 然后我们使用 OpenAI 的 LLM 和 Embedding 模型进行答案生成和向量生成
- 再创建
storage_context来保存所有节点nodes,后面的自动合并检索会根据叶子节点来找其相关的父节点,所以这里需要保存所有节点 - 接下来我们先构建一个基础检索
base_index,这个检索会根据问题对所有叶子节点leaf_nodes进行检索,找到匹配度最高的similarity_top_k个节点,这里我们将获取 12 个匹配度最高的叶子节点 - 我们再构建一个自动合并检索
AutoMergingRetriever,这个检索会根据基础检索的结果来进行合并操作,这里我们设置了simple_ratio_thresh为 0.3,即当检索子节点比例大于这个阀值的节点就会进行自动合并。verbose参数设置为 True,表示输出合并的过程 - 最后我们使用
RetrieverQueryEngine来创建一个检索引擎
接下来我们就可以使用这个检索引擎来回答问题了:
1 | question = "奥创是由哪两位复仇者联盟成员创造的?" |
在没有经过自动合并之前,我们让基础检索获取了 12 个匹配度最高的叶子节点,在输出结果中可以看到,这 12 个节点经过了 3 次合并操作,最终我们得到了 4 个节点,这些节点中既包含叶子节点,也包含合并过后的父节点。
检索效果对比
我们再使用Trulens来评估自动合并检索的效果:
1 | tru.reset_database() |
rag_evaluate的具体代码可以看我的上一篇文章,主要是使用 Trulens 的groundedness,qa_relevance和qs_relevance对 RAG 检索结果进行评估,我们保留了之前的普通检索和句子窗口检索的评估,并添加了自动合并检索的评估。执行代码后,我们可以在浏览器中看到 Trulens 的评估结果:
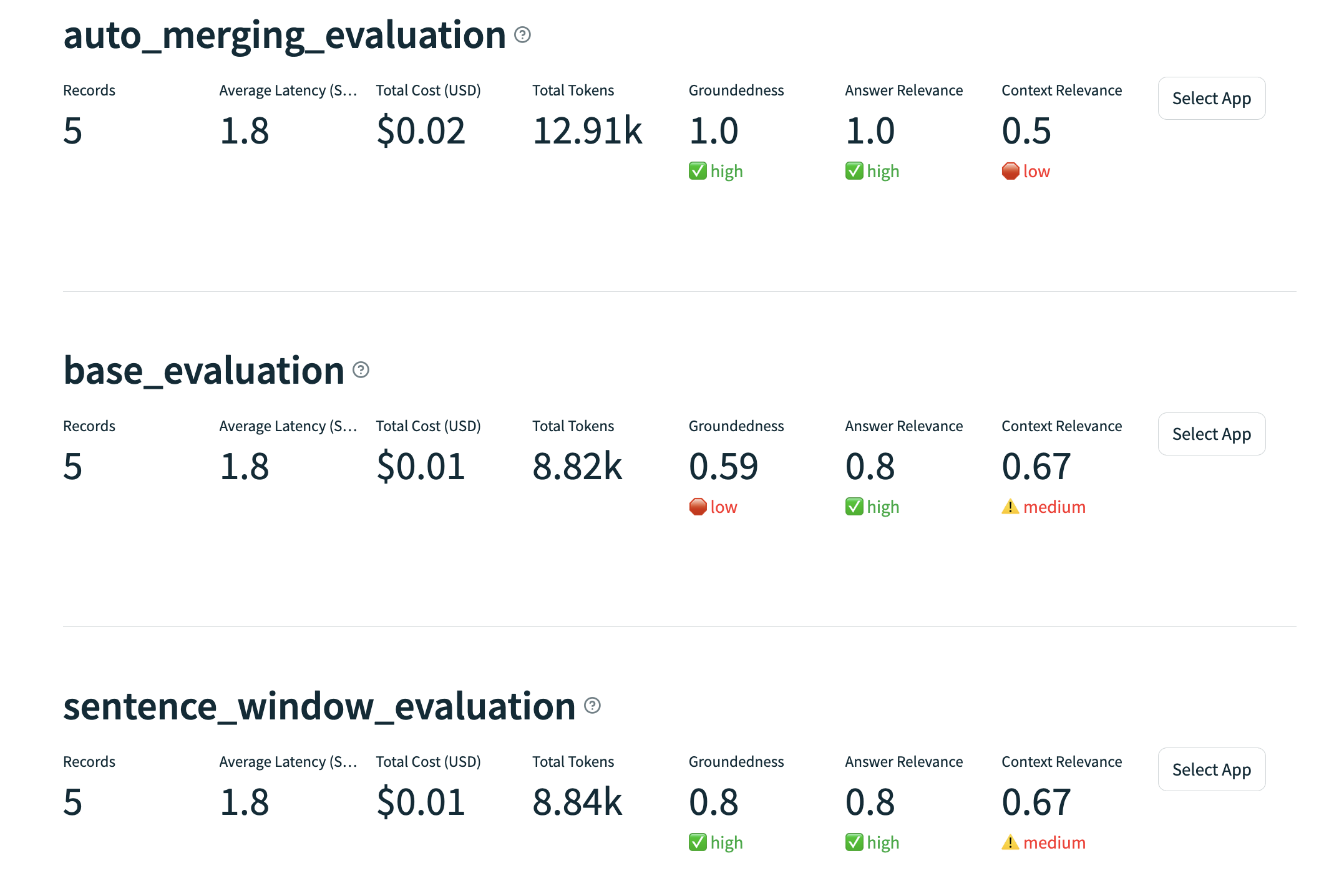
在评估结果中,我们可以看到自动合并检索相比其他两种检索的效果要好,但这不表示自动合并检索会一直比其他检索好,具体的评估效果还要看原始的输入文档,以及检索的参数设置等,总之,具体的评估效果要根据实际情况来评估。
总结
自动合并检索是高级 RAG 检索的一种方法,文档拆分和文档合并的思想是该方法的主要特点,本文介绍了自动合并检索的原理和实现方法,并使用 Trulens 来评估了自动合并检索的效果,希望可以帮助大家更好地理解和使用自动合并检索。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。

