LlamaIndex 与 RAG 评估工具

LlamaIndex 是一个 LLM(大语言模型)应用开发框架,很多开发人员喜欢用它来开发 RAG(Retrieval-Augmented Generation)应用,在开发 RAG 应用的过程中,我们经常需要对相关数据进行评估,以便更好地对应用进行调整和优化。随着 RAG 技术的发展,出现了越来越多优秀的评估工具,可以帮助我们方便且准确地评估 RAG 应用。今天,我将介绍一些可以和 LlamaIndex 集成使用的 RAG 评估工具,并对它们进行对比分析。
什么是 RAG 评估工具
RAG 评估工具是一种用于测试和评估基于检索的文本生成系统的方法或框架,评估的内容包括检索的准确性、生成内容的质量和相关性等,评估指标包括精确度、召回率、一致性和合理性等。它可以帮助开发人员更好地了解和优化 RAG 应用,使其更适用于实际应用。相对于人工评估,RAG 评估工具更加客观、准确和高效,并且可以通过自动化的方式进行大规模的评估,从而让应用更快地进行迭代和优化。实际上有一些应用已经在这样做了,将 RAG 评估工具集成到 CI/CD 流程中,实现系统的自动化评估和优化。
实体术语
在 RAG 应用中有一些常用的实体,评估工具主要使用这些实体来进行评估,但在众多的 RAG 评估工具中,这些实体的名称可能有所不同,因此在介绍具体的评估工具之前,我们先来看一下这些实体的定义:
- Question: 指用户输入的问题,RAG 应用通过问题检索到相关的文档上下文,在一些评估工具中,这个实体也会被称呼成
Input或者Query - Context: 指检索到的文档上下文,RAG 应用检索到相关文档后会将这些上下文结合用户问题一起提交给 LLM,最后生成答案,有的评估工具会将其称呼为
Retrieval Context - Answer: 指生成的答案,RAG 应用将问题和上下文提交给 LLM 后,LLM 会根据这些信息来生成答案,这个实体的称呼比较多样,包括:
Actual Output、Response等 - Grouth Truth: 指人工标注的正确答案,利用这个实体可以对生成的答案进行分析,从而得到评估结果,有的评估工具会将其称呼为
Expected Output
在下面的评估工具介绍中,也会沿用这些实体术语,以便更好地理解和对比。
准备工作
测试文档
我们统一使用大家熟知的漫威电影复仇者联盟相关剧情来作为测试文档,文档内容主要从维基百科上的复仇者联盟条目中获取,主要包括 4 部复仇者联盟电影的剧情信息。
数据集
基于测试文档,我们需要创建Question和Ground Truth的数据,这样方便我们进行评估工作,下面是我们定义的数据集:
1 | questions = [ |
检索引擎
接下来我们再使用 LlamaIndex 来创建一个普通的 RAG 检索引擎,后面评估工具会使用该检索引擎来生成Answer和Context:
1 | from llama_index.core import VectorStoreIndex, SimpleDirectoryReader |
- 我们先从
data目录中加载文档 - 然后使用
VectorStoreIndex来创建一个文档向量索引 - 最后将文档向量索引转换为查询引擎,并设置相似度阈值为 2
TruLens
首先我们来看一下 TruLens,它是一款旨在评估和改进 LLM 应用的软件工具。
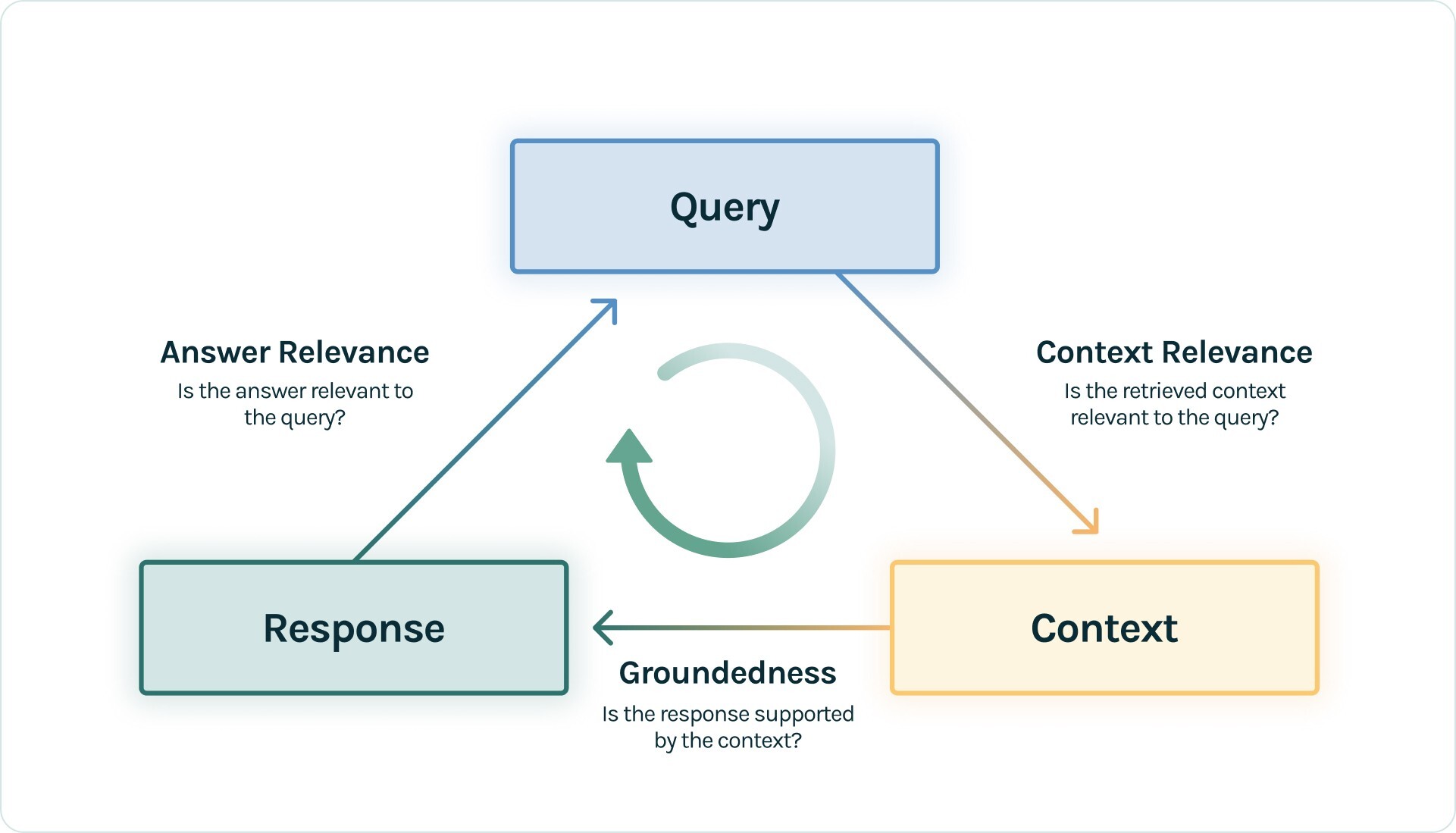
评估指标
Trulens 主要使用以下指标来评估 RAG 应用:
- Anwer Relevance:衡量
Answer如何解答Question,确保其具有帮助性和相关性。 - Context Relevance:评估
Context与Question的相关性。这一点非常重要,因为上下文构成了 LLM 答案的基础。 - Groundedness:评估
Answer是否与Context中提供的事实保持一致,确保不夸大或偏离给定的信息。 - Ground Truth:评估
Answer与Ground Truth之间的相似性,确保生成的答案与人工标注的答案一致。
使用示例
下面是使用 TruLens 进行 RAG 评估的示例:
1 | import numpy as np |
这段代码主要是使用 TruLens 对 RAG 应用进行评估,首先我们定义了Ground Truth、Groundedness、Answer Relevance和Context Relevance等反馈指标,然后使用TruLlama来记录查询引擎的查询结果,最后使用Tru来运行评估并展示评估结果。
评估结果
Trulens 的评估结果可以通过浏览器访问本地服务来进行查看,评估结果中整体的评分和详细的评估指标都会展示出来,而且指标的得分原因也可以在评估结果中查看,下面是 TruLens 的评估结果:
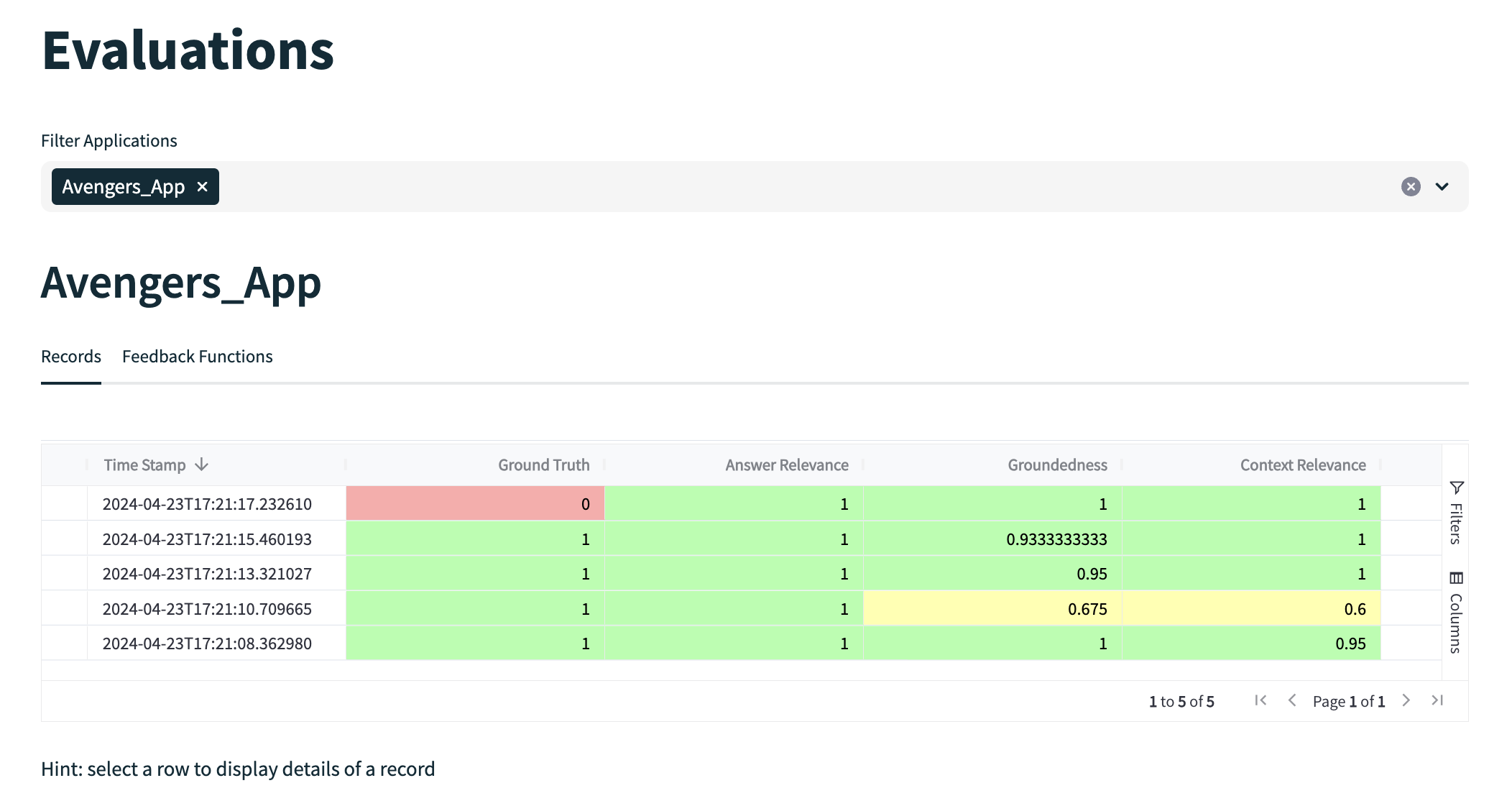
之前我已经写过一篇关于 Trulens 的文章,可以查看这里,里面有更详细的介绍和使用示例。
Ragas
Ragas 是另外一个评估 RAG 应用的框架,相比 Trulens,Ragas 拥有更多且更详细的评估指标。
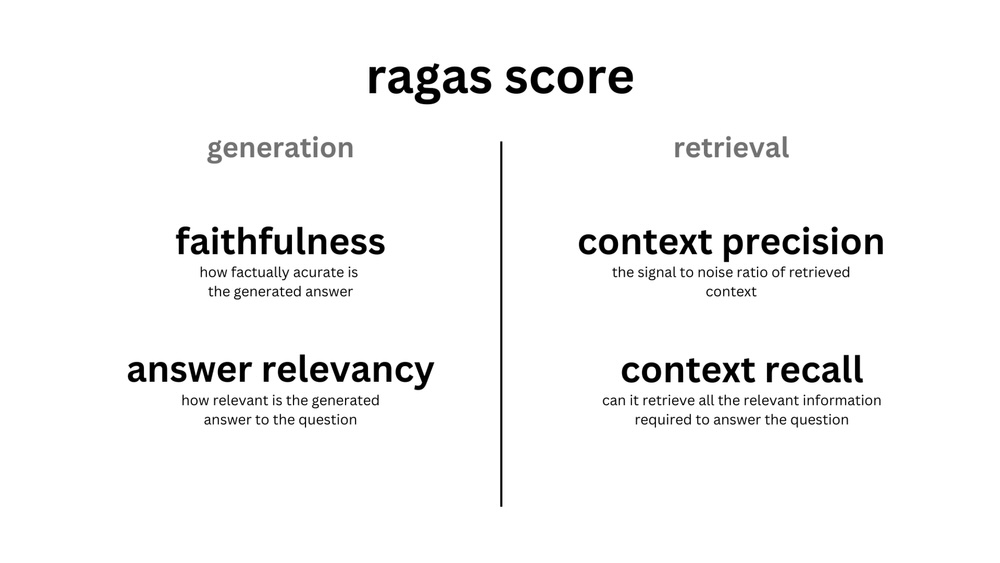
评估指标
Ragas 主要使用以下指标来评估 RAG 应用:
- Faithfulness: 评估
Question和Context的一致性,类似于 Trulens 的 Groundedness - Answer Relevance: 评估
Answer和Question的一致性,类似于 Trulens 的 Answer Relevance - Context Precision: 评估
Ground Truth在Context中是否排名靠前 - Context Recall: 评估
Ground Truth和Context的一致性 - Context Entities Recall: 评估
Ground Truth中的实体和Context中的实体的一致性 - Context Relevancy: 评估
Question和Context的一致性,类似于 Trulens 的 Context Relevance - Answer Semantic Similarity: 评估
Answer和Ground Truth的语义相似性 - Answer Correctness: 评估
Answer相对于Ground Truth的正确性,这个指标会用到Answer Semantic Similarity的结果,类似于 Trulens 的 Ground Truth - Aspect Critique: 其他方面的评估,比如有害性、正确性等
使用示例
在 Ragas 的官方文档集成 LlamaIndex 的示例中,里面的代码已经过时,Ragas 在最新版本中已经不再支持这种集成方式,因此我们需要自己手动集成 LlamaIndex,下面是一个简单的集成示例:
1 | from ragas.metrics import ( |
- 我们还是使用原来的问题和答案数据:
questions和ground_truth - 使用和 Trulens 类似的评估指标,包括
faithfulness、answer_relevancy、context_relevancy和answer_correctness - 需要手动构造评估的数据集,通过提问每个问题获取生成答案和上下文,添加到
data中 - 最后将数据集传入
evaluate函数进行评估,并将评估结果保存到本地文件中
评估结果
我们可以在本地文件中查看 Ragas 的评估结果,评估结果中包括了各个评估指标的得分,下面是 Ragas 的评估结果:
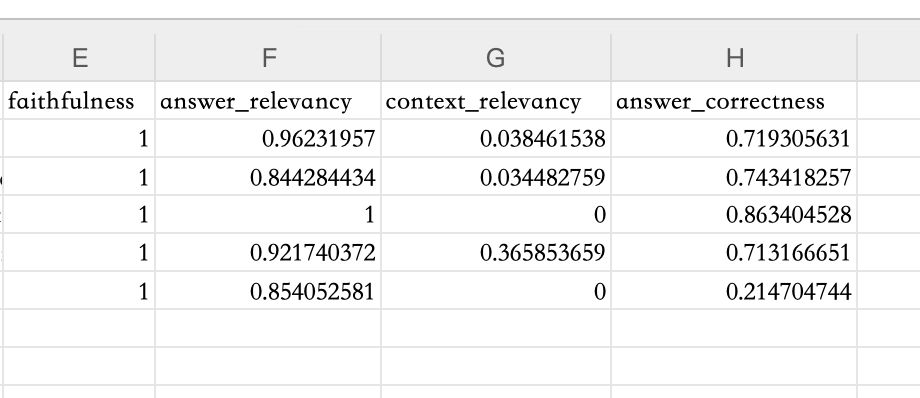
可以看到 Ragas 的评估结果和 Trulens 的评估结果差别还是比较大的,特别是Context Relevancy的评估结果,得分比较低,其实在评估Context时 Ragas 更推荐使用Context Precision和Context Recall这 2 个评估指标,这里我们为了和 Trulens 的评估结果对比,所以使用了Context Relevancy。
在 Ragas 的评估结果中,我们只看到了分数,但没有看到得分的具体原因。
DeepEval
DeepEval 是一个面向 LLM 的开源评估框架,它的最大特点是可以像单元测试一样来运行评估任务,这样可以更方便地对 RAG 应用进行检查和优化。
评估指标
DeepEval 主要使用以下评估指标,其中只有部分指标是用来评估 RAG 应用的,另一部分的指标是针对其他方面的 LLM 应用:
- Faithfulness: 评估
Question和Context的一致性,类似于 Trulens 的 Groundedness - Answer Relevance: 评估
Answer和Question的一致性,类似于 Trulens 的 Answer Relevance - Contextual Precision: 评估
Ground Truth在Context中是否排名靠前,类似于 Ragas 的 Context Precision - Contextual Recall: 评估
Ground Truth和Context的一致性,类似于 Ragas 的 Context Recall - Contextual Relevancy: 评估
Question和Context的一致性,类似于 Trulens 的 Context Relevance - Hullucination:评估幻觉存在程度
- Bias:评估偏见存在程度
- Toxicity: 评估毒性存在程度,毒性是指人身攻击、嘲讽、厌恶、贬低、威胁和恐吓等
- Ragas: 可以使用 Ragas 的评估,并生成得分的原因
- Knowledge Retention: 评估 LLM 应用的信息持久化情况
- Summarization:对于文档总结效果的评估
- G-Eval:G-Eval 是一个使用具有思维链 (CoT) 的 LLM 来执行评估任务的框架,它可以根据任何自定义标准评估 LLM 的输出结果,这里是相关论文
使用示例
DeepEval 可以像执行单元测试一样来运行评估任务,所以执行文件需要以test_开头,下面是一个简单的使用示例:
1 | import pytest |
- 执行 DeepEval 评估任务同样需要先构造测试数据集,数据集中包含了问题、生成答案、上下文和标准答案这些信息
- 评估指标我们使用了
Faithfulness,Answer Relevance和Context Relevance,因为 DeepEval 中没有Ground Truth这个指标,所以无法和 Trulens 和 Ragas 的评估结果保持一致 - DeepEval 默认使用的是
gpt-4模型,如果要省钱的话,建议在评估指标中指定模型名称,比如gpt-3.5-turbo - DeepEval 的评估指标类中还有一个
threshold参数,默认值是 0.5,表示评估指标的阈值,如果得分低于阈值,则表示测试失败
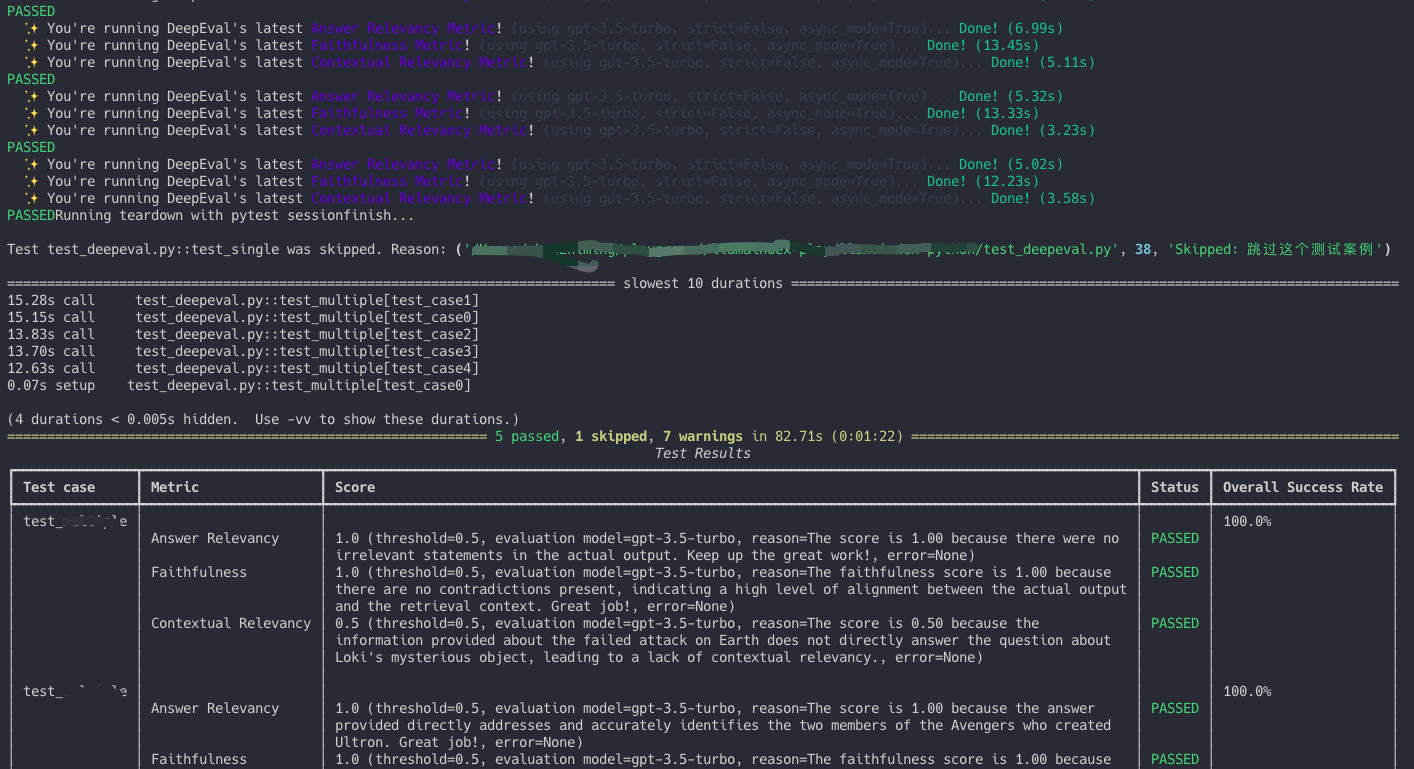
然后在终端中运行命令deepeval test run test_deepeval.py来执行评估任务,执行了命令后,DeepEval 会自动运行评估任务,并输出评估结果,如果测试通过,则会显示PASSED,否则会显示FAILED,最终显示完整的评估结果。
评估结果
在终端查看评估结果可能不太方便,DeepEvel 提供另外几种方式供我们更好地查看评估结果。
一种方式是将评估结果保存到本地文件中,需要在执行测试命令之前设置环境变量export DEEPEVAL_RESULTS_FOLDER="./output",这样执行后的结果就会以 JSON 的形式保存到output目录的文件中,我们可以通过查看文件来查看评估结果。
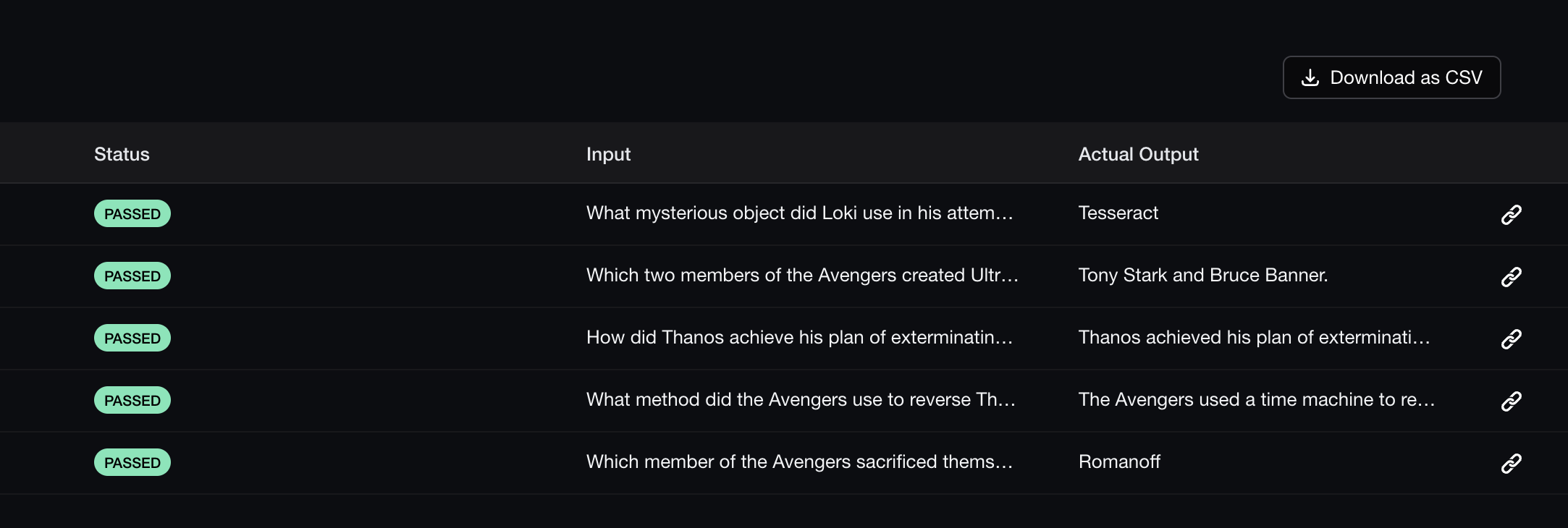
另外一种方式是注册Confident账号,获取 API_KEY,然后在终端使用命令deepeval login --confident-api-key your_api_key进行登录,然后再执行测试命令,这样命令执行完成后会自动将结果上传到 Confident 平台,方便查看,下面是 Confident 平台的评估结果截图:
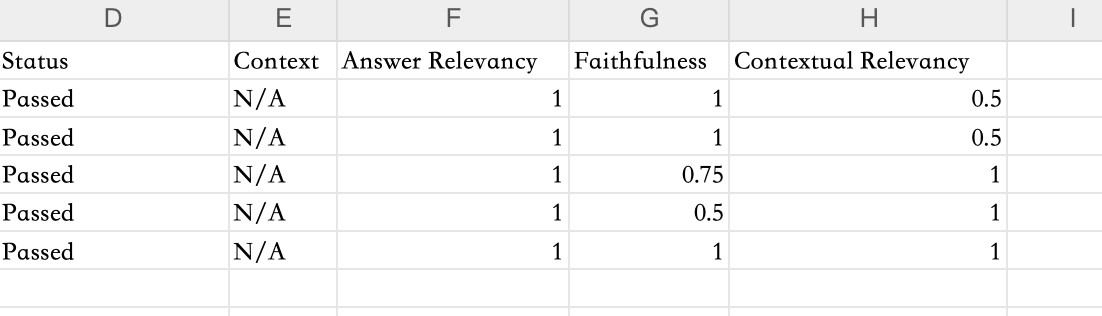
在网站上还可以将评估结果导出为 CSV 文件,这样在本地也可以进行查看:
UpTrain
UpTrain 是一个用于评估和改进的 LLM 应用程序的开源平台,与其他评估工具相比,UpTrain 具有最为丰富的评估指标,可以帮助开发人员更全面地了解和优化 RAG 应用。

评估指标
UpTrain 主要使用以下评估指标,不仅适用于 RAG 应用,还适用于其他 LLM 应用:
- Response Matching: 评估
Answer和Ground Truth的一致性,类似于 Trulens 的 Ground Truth - Response Completeness: 评估
Answer是否回答了Question的所有方面 - Response Conciseness: 评估
Answer是否回答了跟Question不相关的内容 - Response Relevance: 评估
Answer和Question的相关性,类似于 Trulens 的 Answer Relevance - Response Validity: 评估
Answer是否有效,无效的回答是指答案为空或者我不知道等诸如此类的回答 - Response Consistency: 评估
Answer和Question以及Context的一致性 - Context Relevance: 评估
Context和Question的相关性,类似于 Trulens 的 Context Relevance - Context Utilization: 评估
Answer根据Context是否完整回答了Question的所有问题点 - Factual Accuracy: 评估
Answer是事实正确的,并且是通过Context得到的答案,感觉是 Trulens 的 Groundedness 的加强版 - Context Conciseness: 评估
Context是否简洁关键,没有包含无关信息,需要添加 concise_context 参数进行评估 - Context Reranking: 评估重排后的
Context和原始Context的有效性,需要添加 rerank_context 参数进行评估 - Jailbreak detection: 评估
Question是否含有越狱提示词,引导生成不良信息 - Prompt Injection: 评估
Question是否会泄露 LLM 应用的系统提示词 - Language Features: 评估
Answer是否简洁、连贯,没有语法错误等 - Tonality: 评估
Answer是否符合某个角色的语气,需要额外的参数参与评估 - Sub-query Completeness: 评估子问题是否能覆盖原始
Question的所有方面,需要添加 sub_questions 参数进行评估 - Multi-query Accuracy: 评估变种问题是否与原始
Question一致,需要添加 variants 参数进行评估 - Code Hallucination: 评估
Answer中的代码是否与Context相关联 - User Satisfaction: 评估对话中的用户满意度
使用示例
UpTrain 集成了 LlamaIndex,因此我们可以使用它的EvalLlamaIndex来创建评估对象,它可以帮助我们自动生成Answer和Context,下面是一个简单的使用示例:
1 | import os |
- UpTrain 默认使用 OpenAI 的模型进行评估,因此需要设置 OpenAI 的 API_KEY
- 在初始的测试数据集中,我们只需要提供问题和标准答案,其他的数据会由 EvalLlamaIndex 自动生成
- 在评估指标中,我们使用了和其他评估工具类似的评估指标
- 最后将评估结果保存到本地文件中
评估结果
评估结果保存在 JSON 文件中,为了方便对比,我们将评估结果转换为 CSV 文件,下面是 UpTrain 的评估结果:
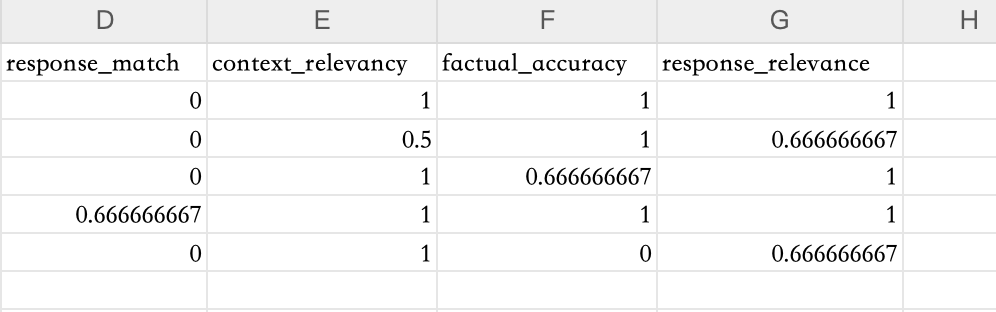
UpTrain 评估结果中的Response Matching的结果感觉不太准确,实际上运行了Response Matching评估指标后会产生 3 个分数,分别是score_response_match、score_response_match_recall、score_response_match_recall,但即使Answer和Ground Truth类似,这几个分数有时候也是 0,不太清楚这个问题的原因,如果有人知道,欢迎在评论区留言。
对比分析
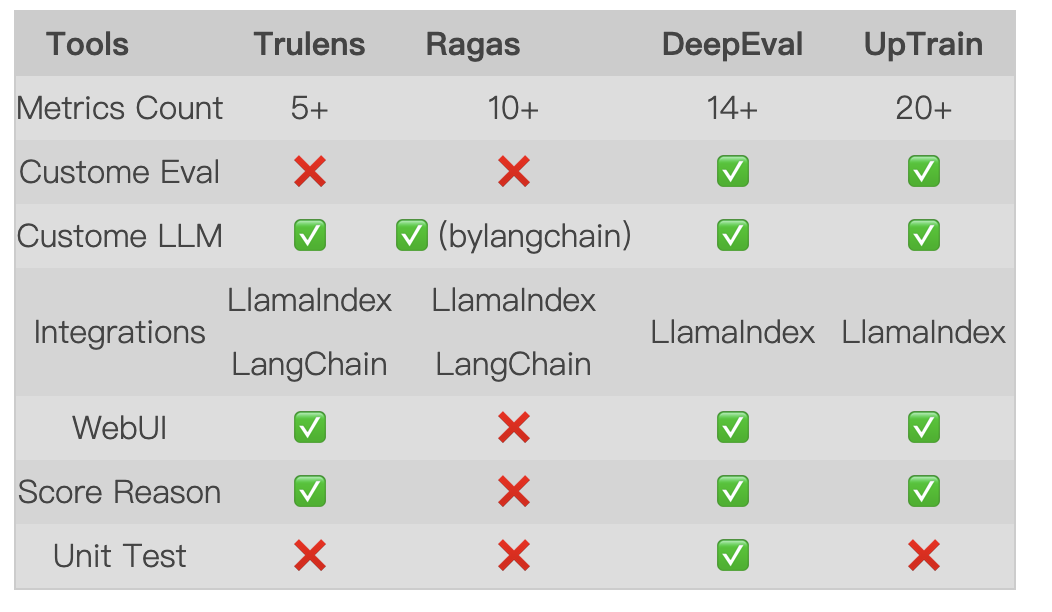
- 评估指标:Trulens 的评估指标相对较少,DeepEval 和 UpTrain 的评估指标虽然较多,但有一部分不是给 RAG 应用使用的,Ragas 的评估指标虽然不多,但基本上覆盖了 RAG 应用的所有方面
- 自定义评估:DeepEval 和 UpTrain 支持自定义评估指标,可以根据实际需求来进行评估,Trulens 和 Ragas 不支持自定义评估指标
- 自定义 LLM:这几个评估工具基本上都支持自定义 LLM,Ragas 通过 LangChain 来实现自定义 LLM
- 框架集成:这里主要比较是否支持 LlamaIndex 和 LangChain 这 2 个主流的 LLM 开发框架,Trulens 和 Ragas 都支持这 2 个框架,DeepEval 和 UpTrain 只支持 LlamaIndex
- WebUI:WebUI 页面可以方便查看评估结果,除了 Ragas,其他评估工具都支持 WebUI,但 Ragas 可以通过第三方工具来实现 WebUI
- 得分原因:除了 Ragas,其他评估工具都支持生成得分原因,Ragas 不支持,但 DeepEvel 可以帮助 Ragas 生成得分原因
- 单元测试:这个特性是 DeepEvel 独有的,可以像单元测试一样来运行评估任务,其他评估工具都不支持
Trulens 和 Ragas 是相对出现较早的 RAG 评估工具,而 DeepEval 和 UpTrain 是后起之秀,它们可能是受到 Trulens 和 Ragas 的启发而开发的,因此在评估指标和功能上都有所增加和改进,但 Trulens 和 Ragas 也有自己的优势,比如 Trulens 的评估结果比较直观,Ragas 的评估指标更加适合 RAG 应用。
总结
本文介绍了可以和 LlamaIndex 集成使用的 RAG 评估工具,并对它们进行了对比,这些评估工具都可以帮助开发人员更好地了解和优化 RAG 应用。实际上还有其他评估工具,比如 LlamaIndex 自带的评估工具、Tonic Validate等,因为篇幅有限,这里就不一一介绍了,如果你不知道该选择哪个评估工具,建议是先选择其中一个并在实际项目中使用,如果发现不合适,再尝试其他评估工具。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。

