对 Llama3 执行基准测试评估

近日 Meta 推出他们最新的开源 LLM(大语言模型)Llama3,吸引了众多科技领域业内人士的关注。Meta 同时也公布了 Llama3 的各项基准测试指标,Llama3 在各项指标的得分上表现优异,超过了目前市面上其他开源 LLM。今天我们就来聊聊 LLM 的基准测试指标,以及如何使用工具来评测 Llama3。
LLama3 介绍
Llama3 的发布无疑是人工智能领域的一个重磅消息,在 Meta 的官方介绍中罗列了 Llama3 的模型能力、训练参数等技术信息,有网友对这次发布进行了总结:

Llama3 开放了 8B 和 70B 两种参数的 LLM,各项能力比 Llama2 强很多,同时还有一个 400B 的 LLM 还在训练中。
模型下载
Llama3 可以在 HuggingFace 上进行下载,但在下载之前需要先提交申请,HuggingFace 上的申请页面如下:
申请后大约等待 1 个小时就审批通过了,接着可以使用 HuggingFace 的 CLI 命令进行下载,需要在终端进行登录再下载,以下载 Llama3-8B 为例,命令如下:
1 | huggingface-cli login |
或者直接下载但需要带上 HuggingFace 的 token,命令如下:
1 | huggingface-cli download meta-llama/Meta-Llama-3-8B --token YOUR_TOKEN |
LLM 基准测试
LLM 基准测试就像是 LLM 的考试,这个考试会用一系列的数据集、问题和任务来考验模型的聪明程度,然后根据模型的表现给出一个分数,满分是 100 分。LLM 基准测试给了一个统一的标准来衡量不同 LLM 的性能,这样一来,不管是公司里的决策者、产品经理还是开发人员,都能更容易地比较和选择最适合他们需求的模型,开发者更好地了解 LLM 的长处和短板之后,就能针对性地改进模型,让模型变得更好更强大。
LLM 基准测试包括以下方面:
- 通用能力:指的是模型的语言理解、对话理解等能力,常用的测试有 MMLU、MT-Bench 等
- Agent 能力:包括工具调用、自我调试、根据反馈信息、探索环境等方面的能力
- 逻辑推理:指的是模型的数学、编码等能力,常用的测试有 HumanEval、GSM8K 等
- 长文本能力:指的是模型的长文本总结、问答等能力
- 特定自然语言处理任务:包括阅读理解、常识推理、世界知识、特定领域知识等方面的能力,常用的测试有 ARC、HellaSwag、SIQA、WinoGrande、TruthfulQA 等
- 真实问答:指的是模型生成真实答案的能力,也是减少幻觉的能力
下面是 Llama3 8B 和 70B 模型的基准测试得分:
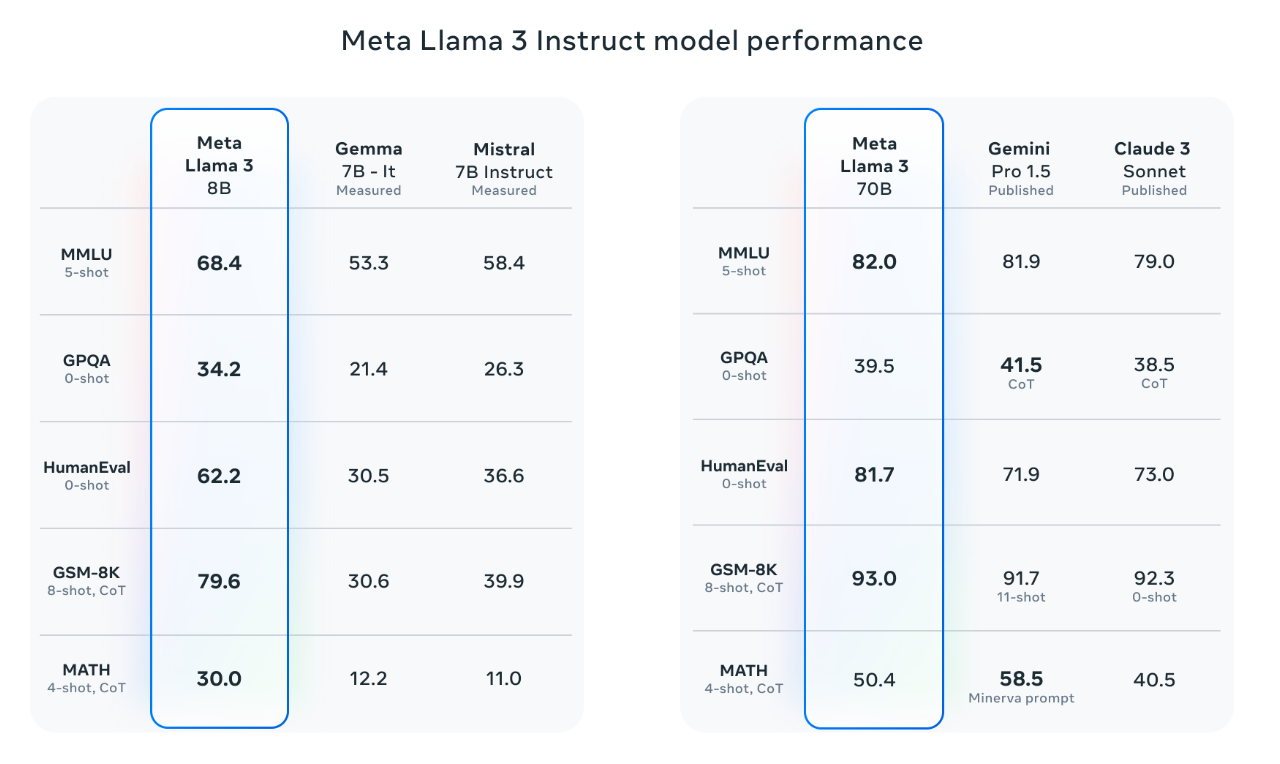
Meta 使用了 MMLU、HumanEval、GSM8K 等基准对 Llama3 8B 和 70B 的模型进行了评测,从图中可以看出,Llama3 在各项基准测试中的得分都很高,尤其是编码能力,HumanEval 和 GSM8K 的得分都比较高。
我们再看下 OpenAI 模型基准测试得分:
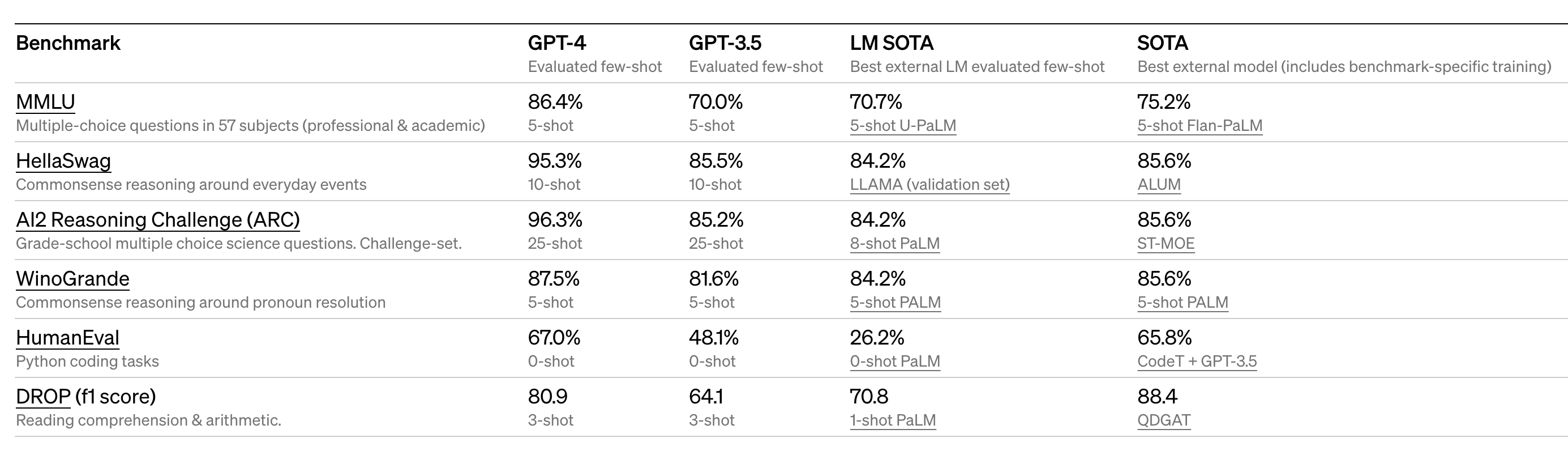
OpenAI 使用了 MMLU、HellaSwag、WinoGrande、ARC、HumanEval 等基准对 GPT-3.5 和 GPT-4 等模型进行了评测,但在 HumanEval 上的分数比 Llama3 低很多。
在 HuggingFace 上,一般是使用 ARC、 HellaSwag、MMLU、TruthQA、WinoGrande 和 GSM8K 这几个基准对 LLM 进行评测。
使用 OpenCompass 评测 Llama3
OpenCompass 介绍
OpenCompass 作为一个专业的大模型评测工具,为用户提供了全面、高效、灵活的评测解决方案,通过开源可复现的评测框架,支持对各类模型进行全面的能力评估。OpenCompass 将测评方向汇总为知识、语言、理解、推理、考试等五大能力维度,整合超过 70 个评测数据集,提供超过 40 万个模型评测问题,支持超过 70 种开源模型的评测,包括最新的 Llama3 模型。
OpenCompass 安装
OpenCompass 的安装方式分为 GPU 环境和 CPU 环境,我们以 GPU 环境为例进行讲解,首先使用conda创建一个新的 Python 环境:
1 | conda create --name opencompass python=3.10 pytorch torchvision pytorch-cuda -c nvidia -c pytorch -y |
然后下载 OpenCompass 的代码仓库并安装相关依赖:
1 | git clone https://github.com/open-compass/opencompass.git |
因为我们后面还要做 HumanEval 的评测,所以还需要额外安装 HumanEval :
1 | git clone https://github.com/openai/human-eval.git |
OpenCompass 提供了基准测试的数据集,包含 HuggingFace 和其他第三方的数据集,还有 OpenCompass 自己的数据集,下载这些数据集并解压到 OpenCompass 的目录下,解压完成后 OpenCompass 目录下会出现一个 data 目录:
1 | cd opencompass |
Llama3 基准评测
在开始测评之前,先介绍一下硬件配置和评测模型:
- 硬件配置:Nvidia 4090 24G 显存
- 评测模型:Meta-Llama-3-8B-Instruct
同时设置好测试时所需的环境变量,如果不设置运行程序会报错:
1 | export MKL_SERVICE_FORCE_INTEL=1 |
- MKL_SERVICE_FORCE_INTEL=1: 表示应用程序在执行使用英特尔数学核心库(MKL)的操作时,强制使用英特尔的服务层,即使在非英特尔的硬件上也是如此。
- MKL_THREADING_LAYER=GNU: 指定 MKL 使用的线程库为 GNU(GOMP,即 GNU OpenMP),选择正确的线程层可以优化并行性能,减少线程竞争和管理开销。
- TF_ENABLE_ONEDNN_OPTS=1: 这个环境变量是为 TensorFlow 设置的,表示启动一些基于 OneDNN(之前称为 MKL-DNN)的优化。
我们首先进行 SocialIQA 和 WinoGrande 的评测,这 2 个评估指标是用于评估 LLM 理解社会常识和解决歧义问题能力的基准,测试代码如下:
1 | python run.py --datasets siqa_gen winograd_ppl \ |
- datasets: 数据集名称
- hf-path: HuggingFace 模型地址,如果本地没有该模型会自动下载
- model-kwargs: 构造 model 的参数
- tokenizer-kwargs: 构造 tokenizer 的参数
- max-seq-len: 模型能接受的最大序列长度
- max-out-len: 最长生成 token 数
- batch-size: 批次大小,如果运行过程中提示显存不足,可以适当调小 batch-size
- num-gpus: 运行模型所需的最少 GPU 数量
- debug: 是否开启 debug 模式,建议是开启调试模式,这样如果有报错会更容易定位问题
如果程序执行成功,最后在终端会输出下面的信息:
1 | dataset version metric mode opencompass....-Llama-3-8B-Instruct |
这就是 Llama3 在 SocialIQA 和 WinoGrande 评测中的得分,分别是 38.59 和 57.19。评测结果可以在 OpenCompass 的 outputs/default/{timestamp}/summary目录下的 CSV 文件中查看,内容如下所示:

我们再来进行 HumanEval 基准测试,HumanEval 是 OpenAI 创建的基准测试,主要用于评估语言模型在代码生成任务上的能力。它包含多种编程问题,模型的任务是生成符合问题要求的代码。评估方式包括运行模型生成的代码并检测其输出是否正确,以及验证代码的功能是否符合问题的需求,测试代码如下:
1 | python run.py --datasets humaneval_gen_8e312c \ |
可以看到运行代码代与之前的基本一致,只是 datasets 参数改为 humaneval_gen_8e312c,数据集的名称可以在 OpenCompass 的 configs/datasets目录下找到,每个数据集对应一个 Python 文件,以 humaneval_gen_8e312c 数据集为例,对应的就是configs/datasets/humaneval/humaneval_gen_8e312c.py这个文件。
在执行 HumanEval 评测时,还需要修改之前下载的 human-eval 代码库中的 human_eval/execution.py 文件,将第 58 行的注释取消,启用代码执行评测,这样才能得到正确的评测结果。
1 | # WARNING |
执行完 HumanEval 评测后的结果如下:

这里 HumanEval 的分数是 51.83,而 Llama3 官方的分数是 62.2,相差比较多,可能是因为官方评测所用的提示词与 OpenCompass 的不相同,所以得分会有所差异。
最后再来进行 GSM8K 评测,GSM8K 是一个用于评估语言模型在数学推理和问题解决能力方面的基准。这个基准包含 8000 个基于小学数学的题目,涵盖了各种数学主题。评估主要看模型在解决这些数学问题时的准确性和推理能力,测试代码如下:
1 | python run.py --datasets gsm8k_gen_1d7fe4 \ |
执行完 GSM8K 评测后的结果如下:

实际评测 GSM8K 的分数是 78.7,而 Llama3 官方得分是 79.6,这一次两者的得分比较接近。
总结
本文主要介绍了 LLM 的基准测试指标,以及如何使用 OpenCompass 评测最新的开源模型 Llama3 并得到指标得分。通过 OpenCompass 的评测,我们可以更全面地了解 Llama3 的性能表现。LLM 基准在一般情况下是有帮助的,但随着基准的日益普及,新的模型可以被训练或微调以获得基准测试高分,这使得模型的得分并不真实反映其在被评估方面的能力,期待这一问题能在日后可以得到改善。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。

