使用 Llama3 打造开发团队的私有 Copilot

相信很多开发人员都使用过 Github Copilot,这种崭新的开发方式可以帮助开发人员极大地提高开发效率,并且也正在逐渐改变开发人员的编程习惯。自从 Meta 开放了最新的开源 LLM(大语言模型) Llama3,业内的各种开发工具和开发框架都在积极地集成 Llama3,以便于使用这个迄今为止功能最强大的开源大模型。今天我们来介绍如何使用 Llama3 构建一个团队专属的私有化 Copilot,不仅可以提高团队的开发效率,还可以保护团队的代码隐私。
编程助手 Copilot
Copilot 是一种人工智能代码辅助工具,最早由 GitHub 和 OpenAI 共同开发,后面有其他产商也推出了类似的产品。Copilot 能够通过自然语言处理和机器学习技术自动生成高质量代码片段和上下文信息,相比于以前的自动补全工具,Copilot 的代码更加详细和智能,比如自动补全工具只能补全一两行的代码片段,但 Copilot 可以生成整个函数的代码,甚至是整个类,从而减轻程序员的工作量并节省时间和精力。除了代码生成外,Copilot 还是支持 AI 问答、代码解释、语言转换、生成单元测试等功能。目前 Copilot 的使用存在以下几种形式。
线上服务
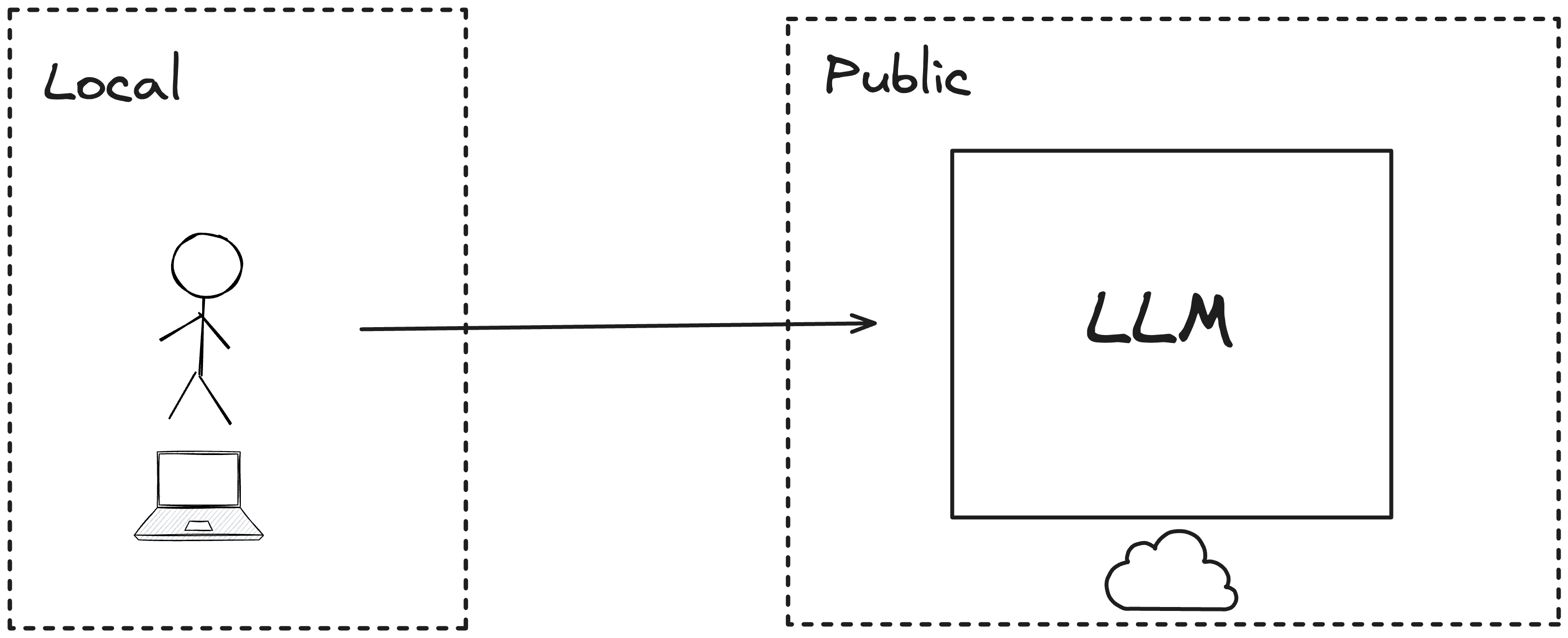
第一种是线上服务,比如 GitHub Copilot,这种服务用户一般只需安装 IDE 插件即可使用,无需关心模型的部署,优点是可以使用线上性能强大的模型,尤其是 Github Copilot,通过 GitHub 上的代码作为模型训练数据,使得生成的代码质量更高,缺点是无法保护代码隐私,因为你要使用 Copilot 服务,你的代码就会被上传到服务端。
除了 GitHub Copilot 外,其他类似的产品还有:
- Codeium:一家致力于为开发者提供更智能高效的编程体验的人工智能公司,支持 VSCode、Jetbrains 等 40 多种的 IDE,个人使用完全免费
- CodeGeeX:清华大学开发的代码辅助工具,支持多种语言,免费使用,使用了自研的模型
- CodeWhisperer:AWS 推出的代码辅助工具,免费使用,特点是具有安全扫描功能
- 通义灵码:阿里云推出的代码辅助工具,使用阿里研发的 Qwen 大模型,支持多种语言,免费使用
本地服务
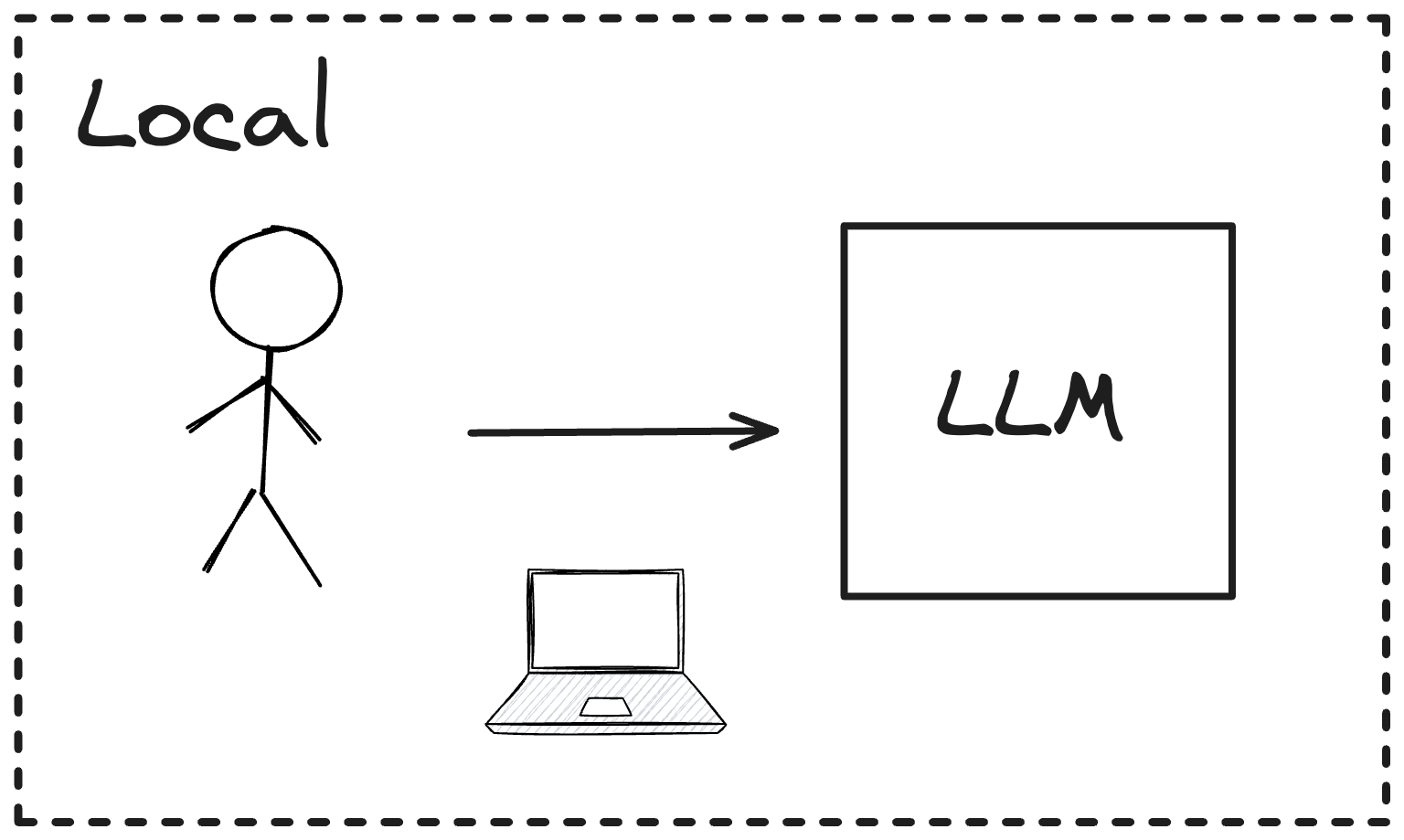
第二种是本地服务,这种方式需要在本地部署 LLM,然后通过 IDE 插件调用本地 LLM 的 API 服务。部署本地 LLM 的工具比较多,常用的有Ollama、LocalAI 等,这些工具支持在 CPU 的机器上运行 LLM,这种方式的优点是无需联网即可使用,并且可以很好地保护代码隐私,缺点是需要每个开发人员都需要安装本地 LLM。
私有化服务
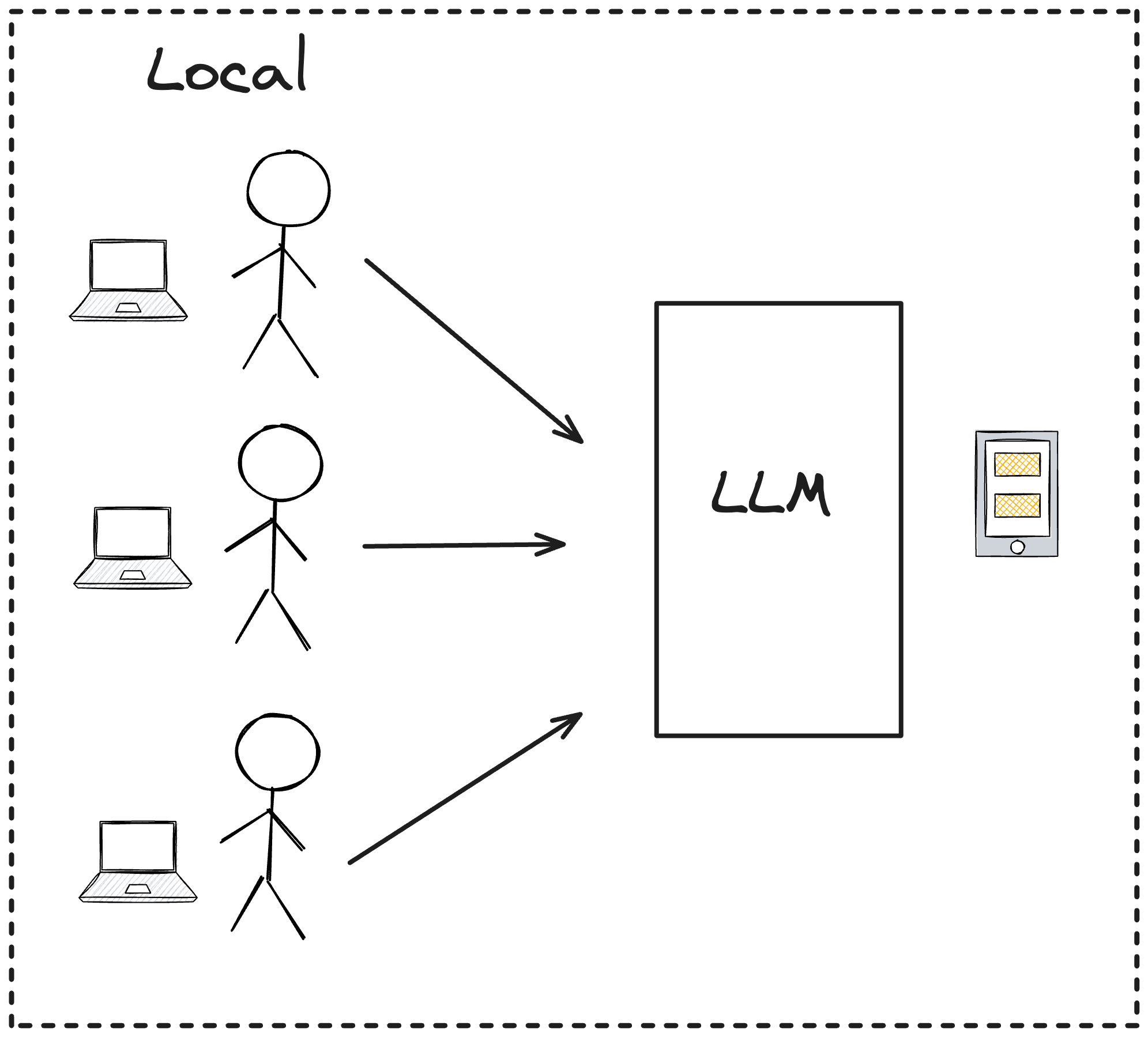
私有化服务也是一种本地服务,但与本地服务不同的是,开发人员无需安装本地 LLM,而是通过开发团队统一来部署 LLM 服务,然后开发人员通过 IDE 插件调用团队内部的 LLM 服务。这种方式的优点是可以保护代码隐私,同时也可以提高团队的开发效率,这也是我们今天要介绍的 Copilot 使用方式。
Llama3 部署
我们要使用 Llama3 来打造团队的私有 Copilot,首先需要部署 Llama3 ,这里我们使用 vllm来部署 Llama3。vllm 是一个高效、易用的库,用于 LLM 的推理和提供服务,它可以部署兼容 OpenAI API 的服务。相比同类产品,vllm 的主要特点是吞吐率高、延迟低、速度快。
首先下载 Llama3 的模型,Llama3 可以在 HuggingFace 上进行下载,但在下载之前需要先提交申请,申请后大约等待一段时间即可审批通过,接着使用 HuggingFace 的 CLI 命令进行下载,我们要下载Meta-Llama-3-8B-Instruct这个模型,命令如下:
1 | huggingface-cli download meta-llama/Meta-Llama-3-8B-Instruct --token YOUR_HF_TOKEN |
然后安装 vllm,vllm 可以通过 pip 安装,命令如下:
1 | conda create -n vllm python=3.9 -y |
安装完成后,我们使用 vllm 的命令来启动兼容 OpenAI 的 API 服务,命令如下:
1 | python -m vllm.entrypoints.openai.api_server \ |
gpu-memory-utilization是 GPU 内存的使用率,这里设置为 0.85,表示服务启动后会占用 85%的 GPU 内存。
启动服务后,服务地址是http://localhost:8000,我们可以通过 curl 命令来验证 API 服务:
1 | curl http://localhost:8000/v1/chat/completions \ |
IDE 插件 Continue
部署完服务端后,我们再来安装客户端。Continue 是一个帮助开发人员轻松创建自己的模块化人工智能软件开发系统的 IDE 插件,它支持 VSCode 和 JetBrains 等 IDE,支持一般 Copilot 的功能,包括代码生成、代码解释、AI 问答等。
插件安装
我们以 VSCode 为例介绍 Continue 插件的安装,首先进去 VSCode 的插件商店搜索 Continue 插件,然后点击安装即可:
修改配置
然后修改 Continue 的配置,使用快捷键打开插件配置文件:cmd/ctrl + shift + P,输入 Continue config, 选择Open config.json:

然后修改配置文件,Continue 默认使用 Ollama 来做本地 LLM 部署,但如果我们已经部署好了 LLM 服务,就可以将原来配置文件中的models和tabAutocompleteModel的配置修改为我们自己的 LLM 服务,如下所示:
1 | "models": [ |
- LLM 配置信息中填写
provider为openai,这里利用了 OpenAI 的配置格式 - 在
apiBase中填写我们部署的 LLM 服务地址,这里是http://your-llama3-api-host:8000/v1,注意要加上最后的v1路径 model填写我们下载的 Llama3 模型,这里是meta-llama/Meta-Llama-3-8B-InstructapiKey属性可以随便填title属性是显示在插件中的模型名称models属性是指在 AI 问答和代码生成功能中可以使用的模型tabAutocompleteModel属性是指在代码补全功能中使用的模型
然后我们在 Continue 插件中选择模型llama3-8b,这样就可以开始使用 Llama3 了:

使用介绍
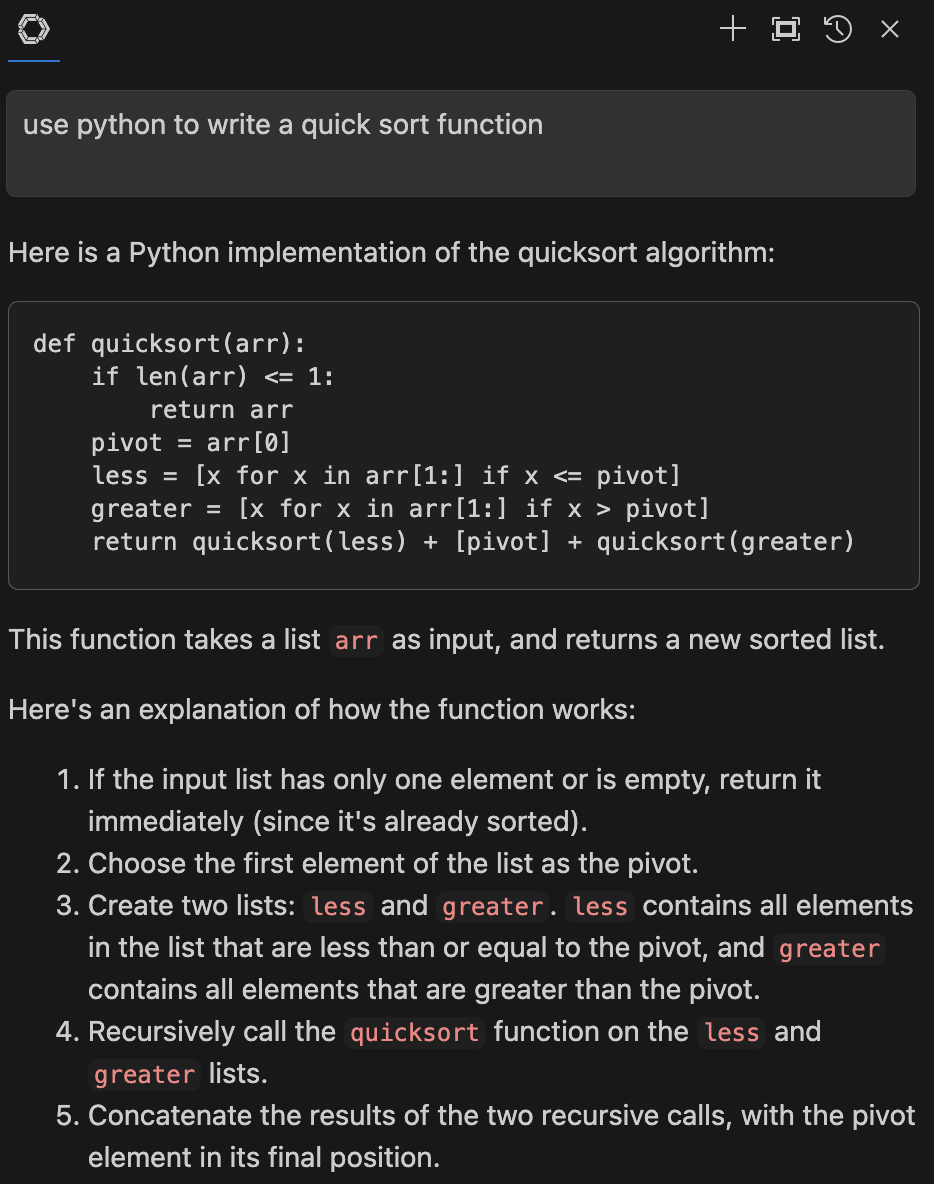
我们先看下 AI 问答功能, 输入问题后 LLM 生成回答:
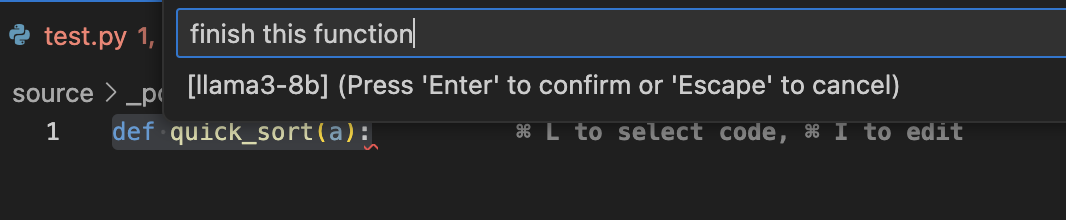
再看看代码生成功能,选中代码后后按住 cmd/ctrl + I 键会弹出输入框,我们在输入框中让 LLM 帮我们完成这个方法:
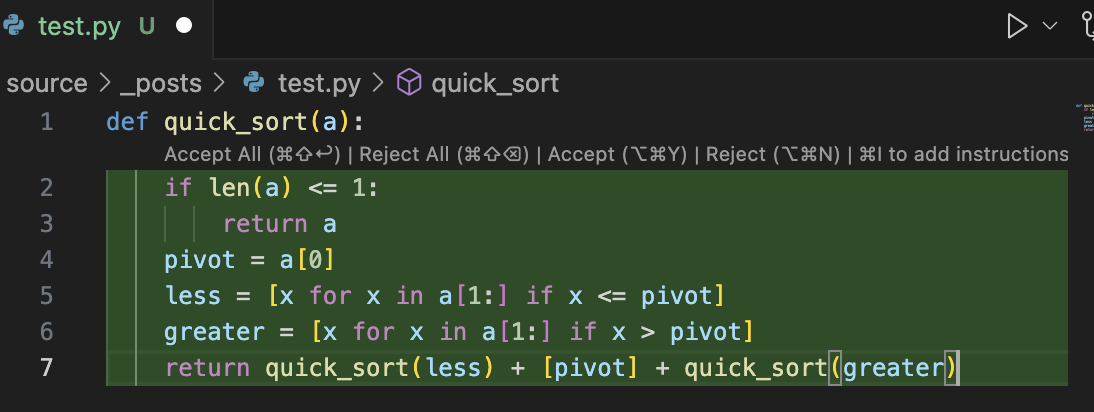
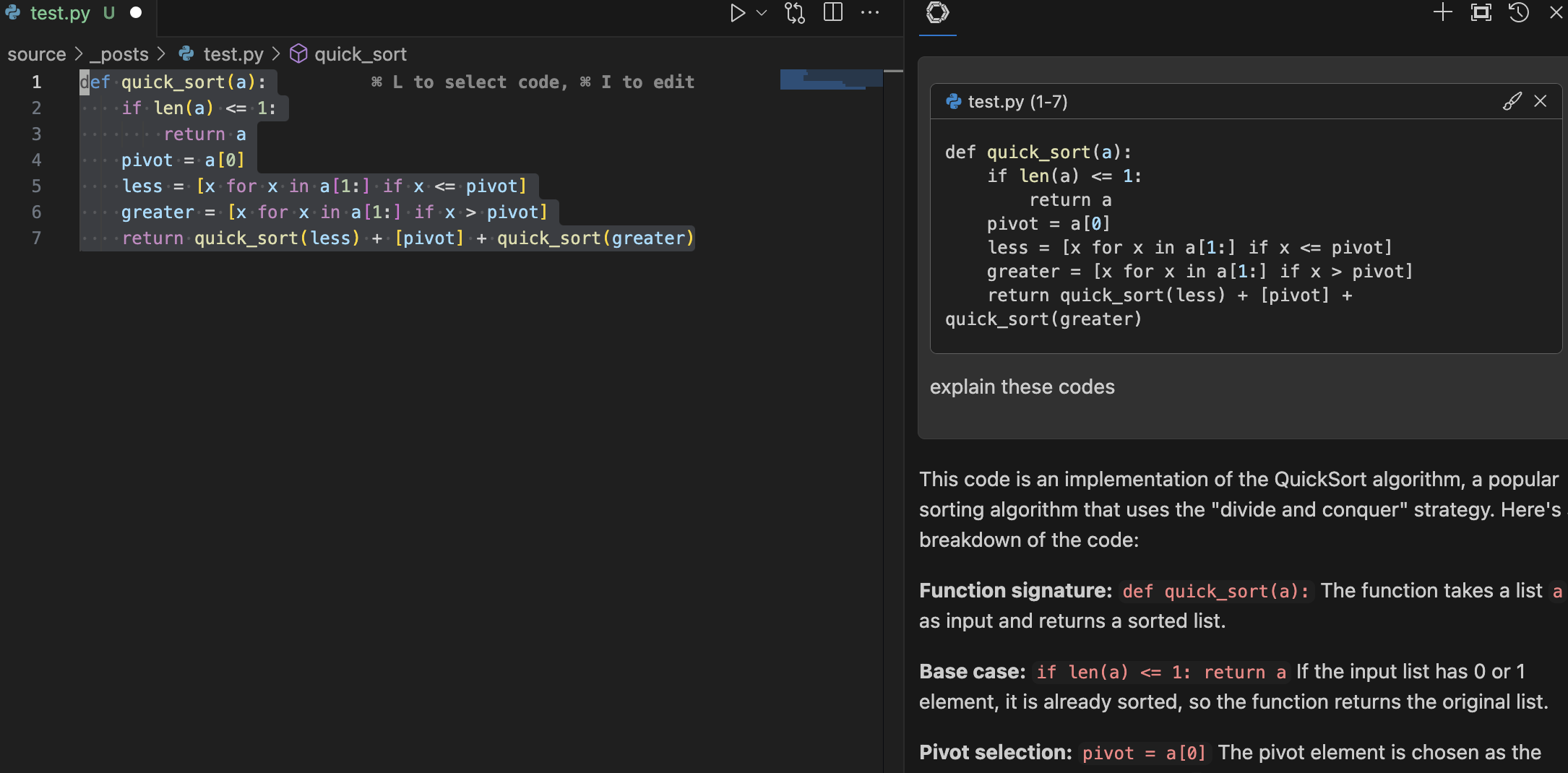
接着看解释代码,选中代码后后按住 cmd/ctrl + L 键会将选中的代码复制到问答框中,输入问题后 LLM 根据代码进行回答:
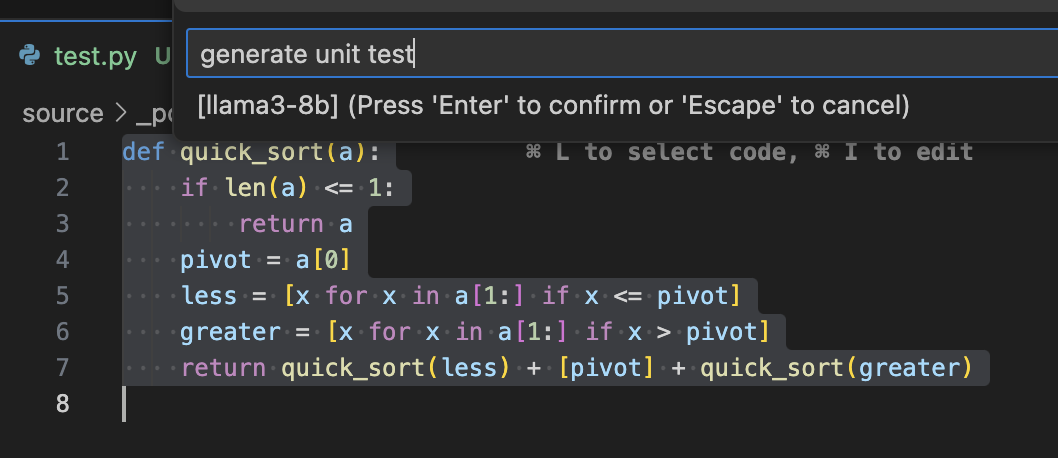
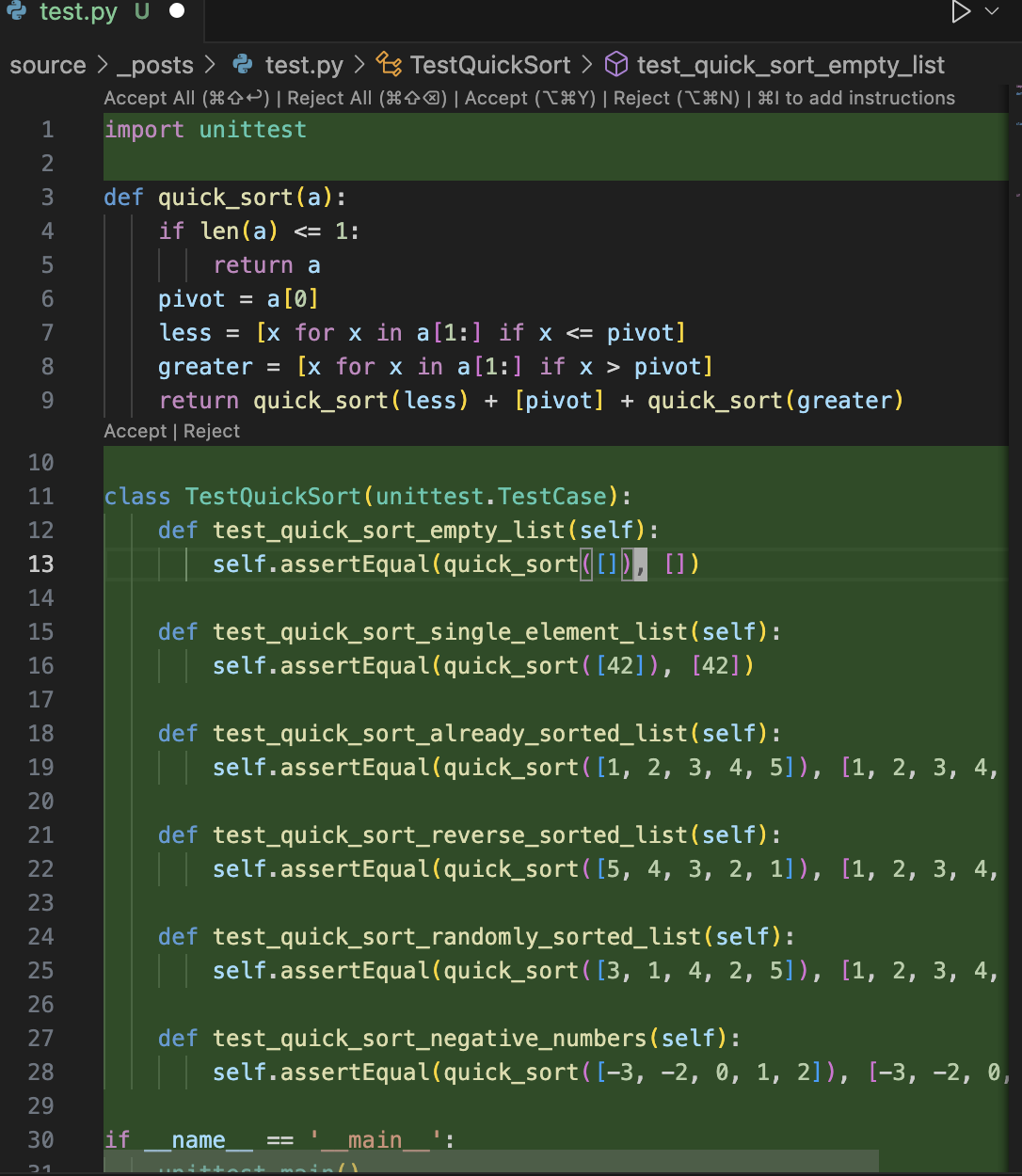
生成单元测试,也属于代码生成功能,与之前操作相同:
关于Continue插件的更多使用方法,可以参考官方文档。
注意事项
如果在使用的过程中发现 Llama3 的输出一直没有结束,可以在配置文件中添加completionOptions配置信息来修复这个问题:
1 | { |
另外除了 Llama3 之外,还有其他的开源 LLM 也可以用来作为代码辅助工具,比如CodeQwen1.5-7B-Chat就是一个不错的选择。
总结
使用开源 LLM 作为团队的代码辅助工具,可以提高团队的开发效率,同时也可以保护团队的代码隐私,虽然目前开源的 LLM 相比 Github Copilot 等公司的线上 LLM 还有一些差距,但是随着开源 LLM 的不断发展,相信两者的差距以后会越来越小。以上就是今天介绍的内容,希望对大家有所帮助。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。

