高级 RAG 检索策略之混合检索

古人云:兼听则明,偏信则暗,意思是要同时听取各方面的意见,才能正确认识事物,只相信单方面的话,必然会犯片面性的错误。在 RAG(Retrieval Augmented Generation)应用中也是如此,如果我们可以同时从多个信息源中获取信息,那么我们的检索结果会更加全面和准确。今天我们就来介绍高级 RAG 检索策略中的混合检索,并在实际操作中结合 ElaticSearch 和 Llama3 来实现混合检索的效果。
原理介绍
混合检索也叫融合检索,也叫多路召回,是指在检索过程中,同时使用多种检索方式,然后将多种检索结果进行融合,得到最终的检索结果。混合检索的优势在于可以充分利用多种检索方式的优势,弥补各种检索方式的不足,从而提高检索的准确性和效率,下面是混合检索的流程图:
- 首先是问题查询,这一过程的设计可以简单也可以复杂,简单的做法是直接将原始查询传递给检索器,而复杂一点的做法是通过 LLM(大语言模型)为原始查询生成子查询或相似查询,然后再将生成后的查询传递给检索器
- 然后是检索器执行检索,检索可以在同一数据源上进行不同维度的检索,比如向量检索和关键字检索,也可以是在不同数据源上进行检索,比如文档和数据库
- 检索过程从原来一个问题变成了多个问题检索,如果串行执行这些检索,那么检索的效率会大大降低,所以我们需要并行执行多个检索,这样才可以保证检索的效率
- 最后是融合检索结果,在这一过程中,我们需要对检索结果进行去重,因为在检索的多个结果中,有些结果可能是重复的,同时我们还需要对检索结果进行排序,排序方法一般采用 RRF(倒数排名融合),选出最匹配的检索结果
环境准备
为了更好地了解混合检索的原理和实现,今天我们将通过 LLM 应用框架LlamaIndex,结合 Meta 最新开源的模型Llama3和开源搜索引擎ElasticSearch,来实现一个高效的混合检索系统。在 RAG 检索过程中除了需要用到 LLM 的模型外,还需要用到 Embedding 模型和 Rerank 模型,这些模型我们也统一使用本地部署的模型,这样可以更好地了解各种模型的使用和部署。
LlamaIndex 集成 Llama3
首先是进行 Llama3 的本地化部署,有多种工具可以部署 Llama3,比如 Ollama 或 vllm,而且这些工具都提供了兼容 OpenAI 的 API 接口,vllm 的部署方式可以参考我之前的这篇文章。
部署完成后,我们再看如何在 LlamaIndex 中集成 Llama3。虽然 LlamaIndex 提供了自定义 LLM的功能,但继承自CustomeLLM类来实现自定义 LLM 的方式比较复杂,需要从头实现complete或chat等方法。这里推荐 LlamaInex 另外一个创建自定义 LLM 的方法,即使用OpenAILike类,这个类是对 OpenAI 类进行轻量级封装,只要有兼容 OpenAI 的 API 服务,就可以直接使用该类来获得 OpenAI LLM 的功能。
要使用OpenAILike类,首先需要安装相关依赖包pip install llama-index-llms-openai-like,然后使用以下代码进行集成:
1 | from llama_index.llms.openai_like import OpenAILike |
- 在
OpenAILike对象中,参数model为模型名称,api_base为本地 Llama3 的 API 服务地址 api_key可以随便填写,但不能不传这个参数,否则会出现连接超时的错误is_chat_model为是否是 chat 模型,因为 OpenAI 的模型分为 chat 模型和非 chat 模型- 然后我们使用 LLM 对象进行了一个普通的对话,结果可以正常返回
LlamaIndex 集成 ElasticSearch
在 RAG 应用中向量数据库是必不可少的一项功能,而 Elasticsearch 能够存储各种类型的数据,包括结构化和非结构化数据,并且支持全文检索和向量检索。ElasticSearch 本地环境的安装和部署可以参考我之前的这篇文章。
部署完 ElasticSearch 后,还需要安装 LlamaIndex 的 Elasticsearch 依赖包pip install llama-index-vector-stores-elasticsearch,然后使用以下代码示例就可以集成 ElasticSearch:
1 | from llama_index.vector_stores.elasticsearch import ElasticsearchStore |
index_name是 ElasticSearch 的索引名称,es_url是 ElasticSearch 服务的地址
自定义 Embedding 和 Rerank 模型
在高级 RAG 的检索过程中,需要用到 Embedding 模型来对文档和问题进行向量化,然后使用 Rerank 模型对检索结果进行重排序。同样有很多工具可以部署这 2 种模型,比如TEI 和 Xinference等。这里我们使用 TEI 来部署这 2 种模型,TEI 和模型的部署可以参考我之前的这篇文章。
Embedding 模型的启动命令如下,这里我们使用了BAAI/bge-base-en-v1.5这个 Embeddings 模型,服务端口为 6006:
1 | text-embeddings-router --model-id BAAI/bge-base-en-v1.5 --revision refs/pr/4 --port 6006 |
Rerank 模型的启动命令如下,这里我们使用了BAAI/bge-reranker-base这个 Rerank 模型,服务端口为 7007:
1 | text-embeddings-router --model-id BAAI/bge-reranker-base --revision refs/pr/4 --port 7007 |
多种检索方式
数据入库
在介绍检索之前,我们先来了解下 LlamaIndex 如何使用 ElasticSearch 对文档进行解析和入库,这里的测试文档还是用维基百科上的复仇者联盟电影剧情,示例代码如下:
1 | from llama_index.vector_stores.elasticsearch import ElasticsearchStore |
- 首先定义了一个 ElasticsearchStore 对象来连接 ElaticSearch 本地服务
- 然后使用 SimpleDirectoryReader 加载本地的文档数据
- 使用 SentenceSplitter 对文档进行分块处理,因为 TEI 的输入 Token 数最大只能 512,所以这里的 chunk_size 设置为 256,chunk_overlap 设置为 50
- 构建 StorageContext 对象,指定向量存储为之前定义的 ElasticsearchStore 对象
- 创建一个自定义 Embeddings 对象,使用的是 TEI 部署的 Embeddings 模型服务,这里
CustomEmbeddings的代码可以参考这篇文章中的代码 - 最后使用 VectorStoreIndex 对象将文档数据入库
当执行完代码后,可以在 ElasticSearch 的avengers索引中看到文档数据,如下图所示:
全文检索
数据入库后,我们再来看下如何在 LlamaIndex 中使用 Elasticsearch 进行全文检索。
全文检索是 Elasticsearch 的基本功能,有时候也叫关键字检索,是指根据关键字在文档中进行检索,支持精确匹配,同时高级功能也支持模糊匹配、同义词替换、近义词搜索等。在 LlamaIndex 中使用 Elasticsearch 进行全文检索的代码如下:
1 | from llama_index.vector_stores.elasticsearch import AsyncBM25Strategy |
- 这里重新定义了一个 ElasticsearchStore 对象,但这次指定了检索策略为 BM25,如果要使用全文检索则必须指定这个检索策略
- 将
ElasticsearchStore对象作为参数来创建VectorStoreIndex对象 - 最后通过
VectorStoreIndex对象创建全文检索的检索器,这里设置检索结果的数量为 2
BM25 是一种在信息检索领域广泛采用的排名函数,主要用于评估文档与用户查询的相关性。该算法的基本原理是将用户查询(query)分解为若干语素(qi),然后计算每个语素与搜索结果之间(document D)的相关性。通过累加这些相关性得分,BM25 最终得出查询与特定文档之间的总相关性评分。这种检索策略在现代搜索引擎中非常常见。
向量检索
我们再来了解 LlamaIndex 中如何使用 Elasticsearch 进行向量检索。
向量检索是一种基于机器学习的信息检索技术,它使用数学向量来表示文档和查询。在 LlamaIndex 中使用 Elasticsearch 进行向量检索有 2 种检索策略,分别是Dense和Sparse,这两种策略的区别在于向量的稠密度,Dense检索的号码每一位都是有用的数字,就像一个充满数字的电话号码,而Sparse检索的号码大部分都是零,只有少数几个位置有数字,就像一个电话号码大部分是零,只有几个位置有数字。如果需要更精细、更复杂的检索方法,用Dense检索,如果需要简单快速的方法,用Sparse检索。ElasicsearchStore类默认的检索策略是Dense,下面是向量检索的代码示例:
1 | from llama_index.vector_stores.elasticsearch import AsyncDenseVectorStrategy, AsyncSparseVectorStrategy |
- 向量检索的代码和全文检索的代码类似
- 如果是使用
Dense检索策略,可以指定retrieval_strategy=AsyncDenseVectorStrategy(),也可以不指定retrieval_strategy参数 - 如果是使用
Sparse检索策略,需要指定retrieval_strategy=AsyncSparseVectorStrategy(model_id=".elser_model_2"),这里需要额外部署 ElasticSearch 的 ELSER 模型
混合检索
定义好了 2 种检索器后,我们再来了解如何将这些检索进行融合,在 LlamaIndex 的 ElasticsearchStore 类中提供了混合检索的方法,示例代码如下:
1 | from llama_index.vector_stores.elasticsearch import AsyncDenseVectorStrategy |
- 这里的检索策略还是使用
Dense检索策略,但是指定了hybrid=True参数,表示使用混合检索
设置了混合检索策略后,在融合检索结果时会自动使用 Elasicsearch 的 RRF 功能。
RRF(倒数排名融合) 是一种融合检索算法,用于结合多个检索结果列表。每个结果列表中的每个文档被分配一个分数,分数基于文档在列表中的排名位置。该算法的基本思想是,通过对多个检索器的结果进行融合,来提高检索性能。
但在 Elasticsearch 的免费版本中,这个功能是不可用的:
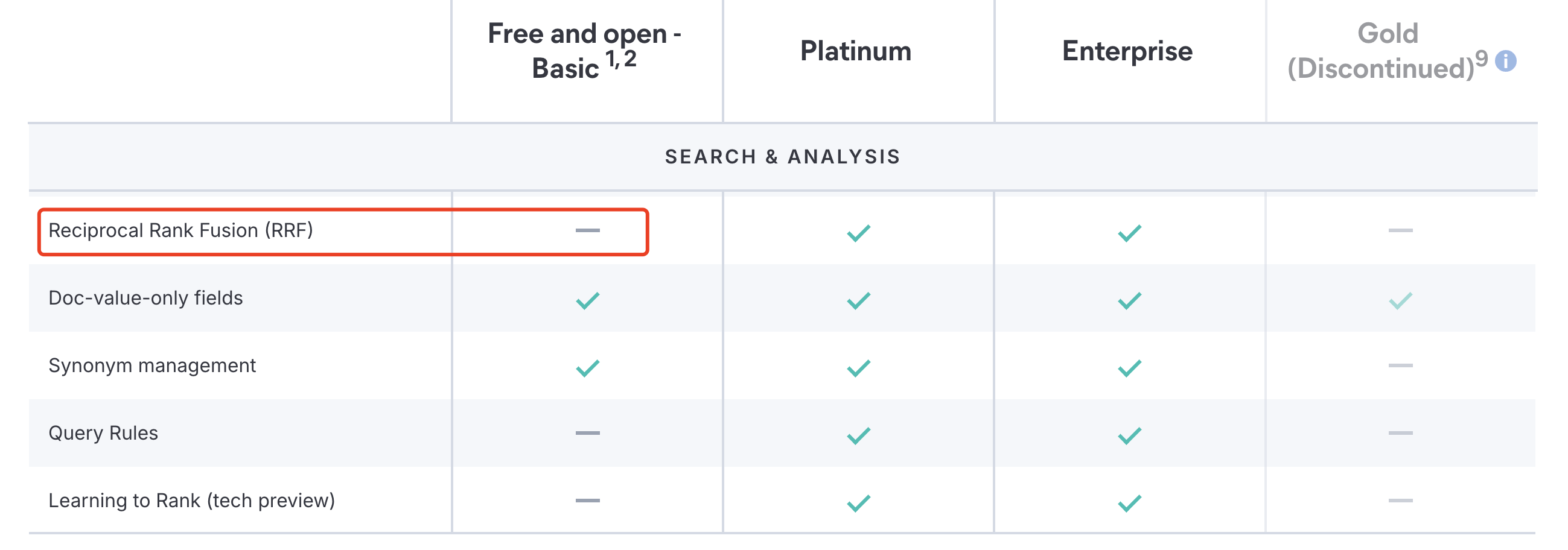
因此我们需要自己实现 RRF 功能,RRF 的论文可以看这里,下面是 RRF 的代码实现:
1 | from typing import List |
- 方法的参数
results_dict是所有检索器的检索结果集合,similarity_top_k是最相似的结果数量 - 假设
results_dict的值是{'full-text': [nodes], 'vector': [nodes]},这个方法方法的作用是将所有的检索结果节点进行融合,然后选出最相似的similarity_top_k个节点 - 方法开头是初始化一些变量,
k用于计算倒数排名分数,fused_scores用于存储节点文本和融合后分数的映射,text_to_node用于存储节点文本到节点的映射 - 然后是计算每个节点的倒数排名分数,先将
results_dict中的每个节点按照分数进行排序,然后计算每个节点的倒数排名分数,将结果保存到fused_scores中,同时将节点文本和节点的关系保存到text_to_nodes中 - 接着再对
fused_scores按照倒数排名分数进行排序,得到reranked_results - 然后根据
reranked_results将结果还原成节点集合的形式,并将节点的分数设置为融合后的分数,最终结果保存到reranked_nodes列表中 - 最后返回最相似的结果,返回
reranked_nodes列表中的前similarity_top_k个节点
定义好融合函数后,我们再定义一个方法来执行多个检索器,这个方法返回的结果就是融合函数的参数 results_dict,示例代码如下:
1 | from tqdm.asyncio import tqdm |
- 方法的参数
query是原始问题,retrievers是多个检索器的集合 - 将问题传给每个检索器,构建异步任务列表
tasks - 然后使用
await tqdm.gather(*tasks)来并行执行所有的检索器,并行执行可以提高检索效率 - 最后将检索结果保存到
results_dict中,返回results_dict
因为我们使用了异步方式进行检索,原先的CustomEmbeddings中的方法也需要修改,示例代码如下:
1 | +import asyncio |
然后我们构建一个融合检索器来将上面定义的方法组合到一起,示例代码如下:
1 | from typing import List |
- 这个融合检索器的类继承自
BaseRetriever类,重写了_retrieve方法 - 构造方法中的参数
retrievers是多个检索器的集合,similarity_top_k是最相似的结果数量 - 在
_retrieve方法中,调用了run_queries方法来获取检索结果results - 然后调用了
fuse_results方法来融合检索结果并返回
我们来看融合检索器运行后的检索结果,代码示例如下:
1 | fusion_retriever = FusionRetriever( |
- 首先定义了一个 FusionRetriever 对象,传入了全文检索器和向量检索器,同时设置了最相似的结果数量为 2
- 然后传入了一个问题,获取检索结果
从结果中可以看到,检索结果节点返回的分数是经过 RRF 融合后的分数,分数值比较低,与原始的 Rerank 分数值不太匹配,这时我们可以使用 Rerank 模型来对检索结果进行重排序。
1 | from llama_index.core.query_engine import RetrieverQueryEngine |
CustomRerank类是一个自定义的 Rerank 类,这个类的代码可以参考这篇文章中的代码- 在系统设置中设置了 LLM 模型来生成答案
- 通过混合检索器构建查询引擎,并在
node_postprocessors参数中传入了 Rerank 模型,表示在检索结果后使用 Rerank 模型对检索结果进行重排序 - 最后传入问题,获取检索结果
从结果中可以看到,检索结果节点返回的分数是经过 Rerank 模型重排序后的分数,分数值比较高,这样我们的混合检索系统就构建完成了。
总结
混合检索是一种在 RAG 应用中常用的检索策略,通过融合多种检索方式,可以提高检索的准确性和效率。今天我们通过 LlamaIndex 的代码实践,了解了构建混合检索系统的流程,同时也学习了如何使用 Llama3 和 ElasticSearch 来实现混合检索的效果,以及混合检索中一些常见的检索策略和排序算法。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。

