高级 RAG 检索策略之 Self-RAG

Self-RAG 是另外一种形式的 RAG(Retrieval Augmented Generation),它与其他 RAG 检索策略不同,它并不是在 RAG 流程上对某个模块进行增强, 而是在 RAG 不同的模块上进行优化改进,从而达到改进整体 RAG 流程的目的。如果你对 Self-RAG 比较陌生或者只是听说它的名字,那么今天请跟我一起来了解 Self-RAG 的实现原理,以及通过学习 Self-RAG 的代码实现来更好地理解其中的细节。
Self-RAG 整体概览
Self-RAG 是一种新的 RAG 方式,通过训练后的 LLM(大语言模型)进行检索、生成和评估等任务,以提高生成结果的准确性和质量。研究团队经过实验证明,Self-RAG 在开放领域问答、推理和事实验证任务中表现优异,效果要比商业模型 ChatGPT 好,同时也比开源模型 Llama2 使用普通 RAG 的效果更好,Self-RAG 的论文地址可以看这里。
Self-RAG 旨在解决普通 RAG 的几个问题:
- 过度检索:普通 RAG 对输入问题始终进行相关知识检索,可能引入无用甚至偏离主题的内容,从而影响输出结果
- 输出不准确:因为不能保证 LLM 始终是基于检索知识来回答问题,所以输出结果可能与检索到的知识不一致
在后面的介绍中我们会慢慢了解为什么 Self-RAG 能解决这些问题。
Self-RAG 流程
为了更好地理解 Self-RAG,我们来看下它与普通 RAG 的区别,首先我们来看下普通 RAG 的流程图:

- 这个流程图省略了文档入库的部分,主要展示检索和生成的过程
- 每一次查询,普通 RAG 都会去检索相关文档,然后将所有的文档和问题一起输入到 LLM 中,然后生成结果
- 生成结果的提示词需要添加所有的检索文档作为问题的上下文,一般会要求 LLM 优先根据上下文知识进行回答
我们再来看下 Self-RAG 的流程图:
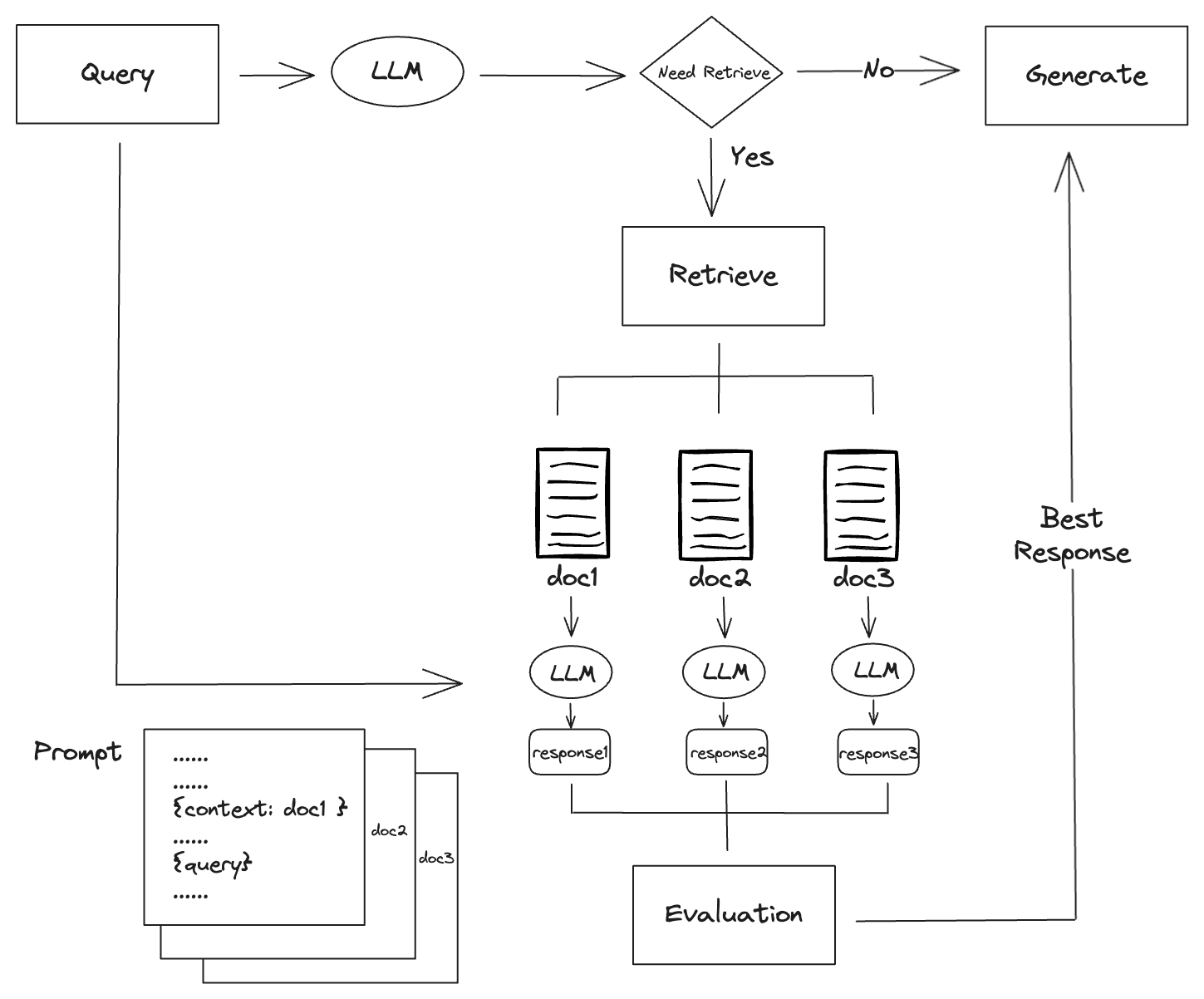
- Self-RAG 首先会使用 LLM 对问题进行首次结果生成(这里的 LLM 是经过特殊训练后的 LLM,后面会详细介绍),然后根据生成的结果可以直接判断是否需要检索,如果不需要检索,则直接返回结果
- 如果需要检索,Self-RAG 会检索出相关文档,然后将每个文档和问题一起输入到 LLM 中,获取每个文档的生成结果,生成结果的提示词只用到了单个文档来作为问题的上下文
- 然后对每个文档的生成结果进行评估,评选出得分最高的结果,最终返回这个结果
Self-RAG 与普通 RAG 的区别
从以上 2 个流程图可以看出,Self-RAG 与普通 RAG 的区别主要有以下几点:
- 普通 RAG 每次查询都需要检索,而 Self-RAG 可以根据生成的结果判断是否需要检索
- 普通 RAG 将检索到的所有文档作为上下文,而 Self-RAG 只用到了单个文档作为上下文,但需要对每个文档进行结果生成
- Self-RAG 对生成结果有一个评估和挑选的过程,而普通 RAG 没有这个过程,因为普通 RAG 的生成结果只有一个
- 普通 RAG 使用的是通用 LLM,而 Self-RAG 使用的是经过特殊训练后的 LLM
按需检索
了解了 Self-RAG 的整体流程后,我们再来了解一下 Self-RAG 每个阶段的实现原理,首先是首次查询阶段。
与普通的 RAG 不同,Self-RAG 使用的是经过训练的 LLM,这种 LLM 在文本生成的过程中,会输出一些特殊的 Token,这些 Token 叫 Reflection Token。在 RAG 流程中,Self-RAG 会使用 Reflection Token 来进行不同的操作。
Self-RAG 开始使用 LLM 对问题进行生成时,会输出 Retrieve 类型的 Reflection Token,这种类型的 Token 的值有 3 种,分别是:
- Retrieval:表示需要检索
- No Retrieval:表示不需要检索
- Continue to Use Evidence: 表示模型可以继续使用先前检索到的证据
我们来通过几个例子来看一下 Self-RAG 生成的 Reflection Token 是怎样的,首先我们提问一个不需要检索的问题,问题和输出结果示例如下:
1 | Question: Write a essay of your best summer vacation. |
在返回结果中我们可以看到包含了[No Retrieval]关键字,表示这个问题不需要检索,可以直接返回结果。
我们再问一个需要检索的问题,问题和输出结果示例如下:
1 | Question: How did US statues get their names? |
在返回结果中我们可以看到包含了[Retrieval]<paragraph> 关键字,表示这个问题需要补充外部知识,即需要检索。
当然,普通 RAG 也可以通过其他方式来实现按需检索,比如首先通过 LLM 确定查询问题是否需要检索,返回一个yes/no的结果,如果不需要检索,则再用 LLM 生成最终结果。这意味着,如果查询问题不需要检索,普通 RAG 需要调用 2 次 LLM,而 Self-RAG 只需要调用 1 次 LLM。

可以看到在不需要检索这个分支上,Self-RAG 比普通 RAG 的效率更高。
检索与生成
当 Self-RAG 经过首次查询后,发现需要检索,那么就会使用检索器根据问题检索文档,在检索方面,Self-RAG 和普通 RAG 并没有什么不同,都是通过向量相似性来检索文档。当检索完文档后,会将每个文档和问题一起输入到 LLM 中,获取每个文档的生成结果。
在第二次的生成结果中,Self-RAG 的 LLM 会生成 3 种类型的 Reflection Token,分别是:
- IsREL:检查检索到的文档是否为问题提供了有用的信息,它的值有
[Relevant]和[Irrelevant],表示文档的相关性 - IsSUP:检查检索到的文档是否都为生成的答案提供了支持,它的值有
[Fully supported],[Partially supported],[No support / Contradictory],表示支持的程度 - IsUSE:表示生成的答案是否对问题有帮助,它的值有
[Utility:5]、[Utility:4]、[Utility:3]、[Utility:2]、[Utility:1],表示答案的质量,数字越大表示质量越高
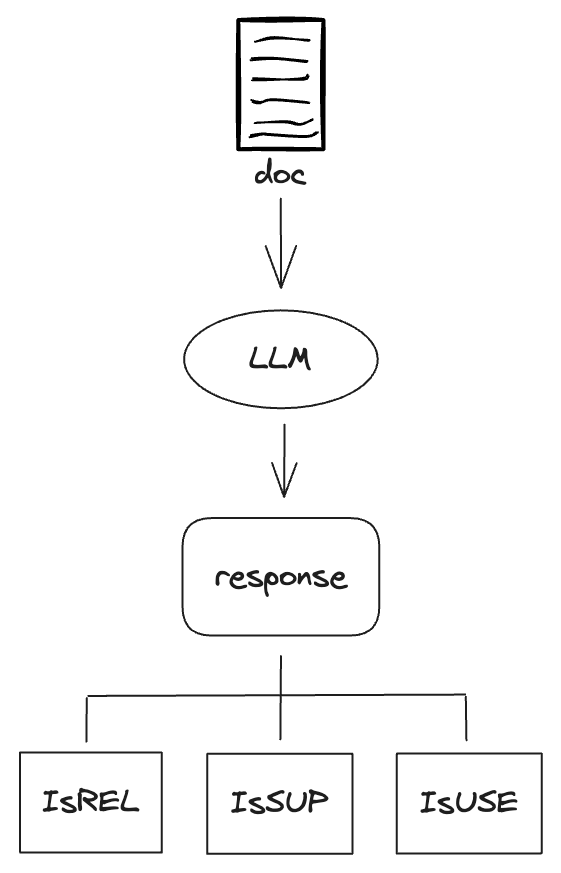
我们来看下 Self-RAG 在这个阶段的生成结果,问题和输出结果示例如下:
1 | Question: What mysterious object did Loki use in his attempt to conquer Earth? |
可以看到,在每个生成结果中,基本上都包含了以上 3 种 Reflection Token,这些 Token 会在后面的评估阶段进行使用。
优化生成效率
在这个阶段因为需要使用 LLM 对每个文档生成结果,可能会有人觉得这个阶段的效率会比普通 RAG 低,但实际上可以使用并发的方式来进行结果生成,从而提高效率。

上图中 Self-RAG 虽然需要调用 3 次 LLM,但通过并发的方式,执行时间和调用 1 次 LLM 的时间是一样的,所以在这个阶段 Self-RAG 的效率和普通 RAG 基本一致,虽然 Self-RAG 耗费的 token 会多一些。
评估与选择
当生成了每个文档的结果后,Self-RAG 会对每个文档的结果进行评估,评估的方式是通过上个阶段生成的 Reflection Token 来计算每个文档的得分,然后选择得分最高的文档作为最终结果。
评估参数 logprobs
在了解评估的方式之前,我们先来了解一下 Self-RAG 评估的一个重要参数logprobs,这个参数指的是对每个生成的 token(即单词或子词)的概率对数,这个参数是在生成结果时 LLM 输出的,通过这个参数可以计算每个 token 的得分。

我们来看下 OpenAI API 返回的一个结果示例:
1 | { |
在这个示例中,logprobs 参数的输出如下:
- tokens:生成的 token 列表 [“ I’m”, “ good”, “,”, “ thanks”, “!”]
- token_logprobs:每个生成的 token 的对数概率值 [-0.1, -0.05, -0.2, -0.3, -0.15]
- top_logprobs:每个生成的 token 的前几名候选 token 的对数概率值及其对应的 token,例如第一个 token
I’m的前几名候选 token 及其对数概率值为{" I’m": -0.1, " I am": -2.3, " I": -3.1} - text_offset:每个 token 在生成文本中的偏移量 [5, 9, 14, 15, 21]
在 Self-RAG 中,评估功能使用logprobs参数来计算IsREL、IsSUP和IsUSE这 3 种 Reflection Token 的得分。比如输出中出现了[Fully supported]这个 token,那么说明 LLM 推理的时候计算出了[Fully supported]、[Partially supported]等可能的 token 输出的概率,但最后选择了[Fully supported]。因此,在评估这次输出的 IsSUP 的分数时,就可以基于 logprobs 中这些 tokens 的概率来计算。
评估公式
了解了logprobs参数后,我们再来看下 Self-RAG 3 个评估指标的计算公式,首先是IsREL的计算公式:
s(ISREL) = p(ISREL = RELEVANT) / (p(ISREL = RELEVANT) + p(ISREL = IRRELEVANT))
- p(ISREL = RELEVANT) 代表模型预测 ISREL 为 Relevant 的概率
- p(ISREL = IRRELEVANT) 代表模型预测 ISREL 为 Irrelevant 的概率
然后是IsSUP的计算公式:
s(ISSUP) = p(ISSUP = FULLY) / S + 0.5 * p(ISSUP = PARTIALLY) / S
- p(ISSUP = FULLY) 代表模型预测 ISSUP 为 Fully Supported 的概率
- p(ISSUP = PARTIALLY) 代表模型预测 ISSUP 为 Partially Supported 的概率
- S 代表三种可能值的概率之和: S = ∑t∈{FULLY,PARTIALLY,NO} p(ISSUP = t)
最后是IsUSE的计算公式:
s(ISUSE) = (∑i wi * p(ISUSE = i)) / S
- wi 代表每个等级的权重,分别为:{-1, -0.5, 0, 0.5, 1},对应 ISUSE={1, 2, 3, 4, 5}
- p(ISUSE = i) 代表模型预测 ISUSE 为等级 i 的概率
- S 代表五种等级的概率之和:S = ∑t∈{1,2,3,4,5} p(ISUSE = t)
可以看到这些计算公式都是基于 logprobs 参数来计算的,这样可以更好地评估每个文档的生成结果,从而选择得分最高的文档作为最终结果。
模型训练
Self-RAG 需要训练的模型有 2 种,一种是评估模型(Critic),另一种是生成模型(Generator)。评估模型使用 GPT4 生成的数据作为训练语料,生成模型则是使用检索数据和评估模型的生成数据作为训练语料,两者都可以基于基础大模型进行训练。
Self-RAG 研究团队分别基于 Llama2-7b 和 Llama2-13b 这 2 个模型进行训练,训练好的模型可以在 Huggingface 上进行下载,但官方的模型并没有明确区分是评估模型还是生成模型,也就是说这些模型可以同时用于评估和生成。
我们来看下模型训练的数据,首先是评估模型的训练数据,下面是训练数据的截取片段:
1 | { |
- 评估模型的每项训练数据都是一项任务,任务类型分别有
retrieval、groundness、utility和multi_retrieval这 4 种任务 retrieval任务用来训练生成IsREL评估指标groudness任务用来训练生成IsSUP评估指标utility任务用来训练生成IsUSE评估指标multi_retrieval任务用来训练生成Retrieve类型的 Reflection Token,即是否需要检索
通过训练数据可以看出,评估模型主要训练如何评估这 4 类任务,根据指令和输入数据,输出正确的评估结果。
再来看生成模型的训练数据,下面是训练数据的截取片段:
1 | { |
通过训练数据可以看出,生成模型主要训练如何生成带有 Reflection Token 的综合性结果。
LlamaIndex Self-RAG Pack
目前已经有了一些开源的 Self-RAG 实现,比如在 LlamaIndex 的 Llama Packs 上就有人提供了 Self-RAG 的实现,下面我们来看下如何使用 LlamaIndex 的 Self-RAG Pack。
Llama Packs 是一个社区驱动的预包装模块或模板集合,用于快速开始构建基于 LLM 的应用程序,如果把 LlamaIndex 比作 VsCode 的话,那么 Llama Packs 就是 VsCode 的插件。
使用介绍
首先我们需要下载 Self-RAG 模型, 这里我们下载量化版的 Self-RAG 模型,这样我们可以在没有 GPU 的机器上运行模型,下载命令如下:
1 | pip3 install -q huggingface-hub |
然后下载 LlamaIndex 的 Self-RAG Pack,下载命令如下:
1 | llamaindex-cli download-llamapack SelfRAGPack --download-dir ./self_rag_pack |
下载完成后,我们可以看到下载的文件夹中包含了 Self-RAG Pack 的源码,我们可以通过以下代码来调用 Self-RAG Pack:
1 | from self_rag_pack.llama_index.packs.self_rag.base import SelfRAGQueryEngine |
SelfRAGQueryEngine 初始化需要模型路径和检索器,检索器可以使用普通 RAG 的检索器 VectorStoreIndex。
核心代码解读
Self-RAG Pack 的核心代码在 SelfRAGQueryEngine 类中,这个类包含了 Self-RAG 的整个流程,首先我们看下 custom_query 方法:
1 | def custom_query(self, query_str: str) -> Response: |
- 通过 LLM 进行首次查询,获取生成结果
- 对生成结果进行判断,如果需要检索,则调用检索器进行检索,这部分代码后面介绍
- 如果无需检索,则对结果进行后处理,然后返回结果,这里的后处理主要是去掉 Reflection Token
再来看custom_query方法中的检索部分代码:
1 | def custom_query(self, query_str: str) -> Response: |
- 通过判断生成结果中是否包含
[Retrieval]来判断是否需要检索 - 如果需要检索,则调用检索器进行检索,获取检索到的文档, 并将检索到的文档内容和问题一起构建成提示词列表
paragraphs - 执行
_run_critic方法进行结果生成并评估,这个方法的代码后面介绍 - 从
_run_critic方法中得到每个文档的分数列表paragraphs_final_score,每个文档的生成结果列表llm_response_per_paragraph和文档列表source_nodes - 在
paragraphs_final_score中选择得分最高的文档作为最终结果,然后返回该结果
接下来我们看下 _run_critic 方法的实现:
1 | def _run_critic(self, paragraphs: List[str]) -> CriticOutput: |
- 初始化几个变量:每个文档的分数列表
paragraphs_final_score,每个文档的生成结果列表llm_response_per_paragraph和文档列表source_nodes - 遍历提示词列表
paragraphs,每个提示词是问题加检索文档,将提示词发送给 LLM,获取生成结果,这里是串行地调用 LLM,如果换成并发的方式效率更高 - 从 LLM 的生成结果中获取生成的文本和
logprobs参数,将文本内容保存到llm_response_text中,将logprobs参数用来计算IsREL、IsSUP和IsUSE的得分 - 分别计算
IsREL、IsSUP和IsUSE的得分,然后通过这个计算公式计算出每个文档的最终得分:final_score = IsREL + IsSUP + 0.5 * IsUSE,并将结果保存到paragraphs_final_score中 - 将每个文档转换为
NodeWithScore对象保存到source_nodes中 - 最后返回
CriticOutput对象,包含了每个文档的生成结果、分数和文档列表
关于更多 Self-RAG Pack 的代码实现,可以查看这里。
总结
通过今天的介绍,我们了解了 Self-RAG 的实现原理,以及通过 LlamaIndex 的 Self-RAG Pack 代码来学习 Self-RAG 的具体实现,让我们可以更好地理解 Self-RAG 的细节和流程。Self-RAG 主要通过自训练的 LLM 来为生成结果提供 Reflection Token,从而可以轻松实现按需检索和评估等功能,无需再次调用 LLM 或者使用其他第三方库,这样可以提高效率和准确性。希望通过今天的介绍大家可以更好地理解 Self-RAG,将来可以更好地应用 Self-RAG 到实际项目中。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。

