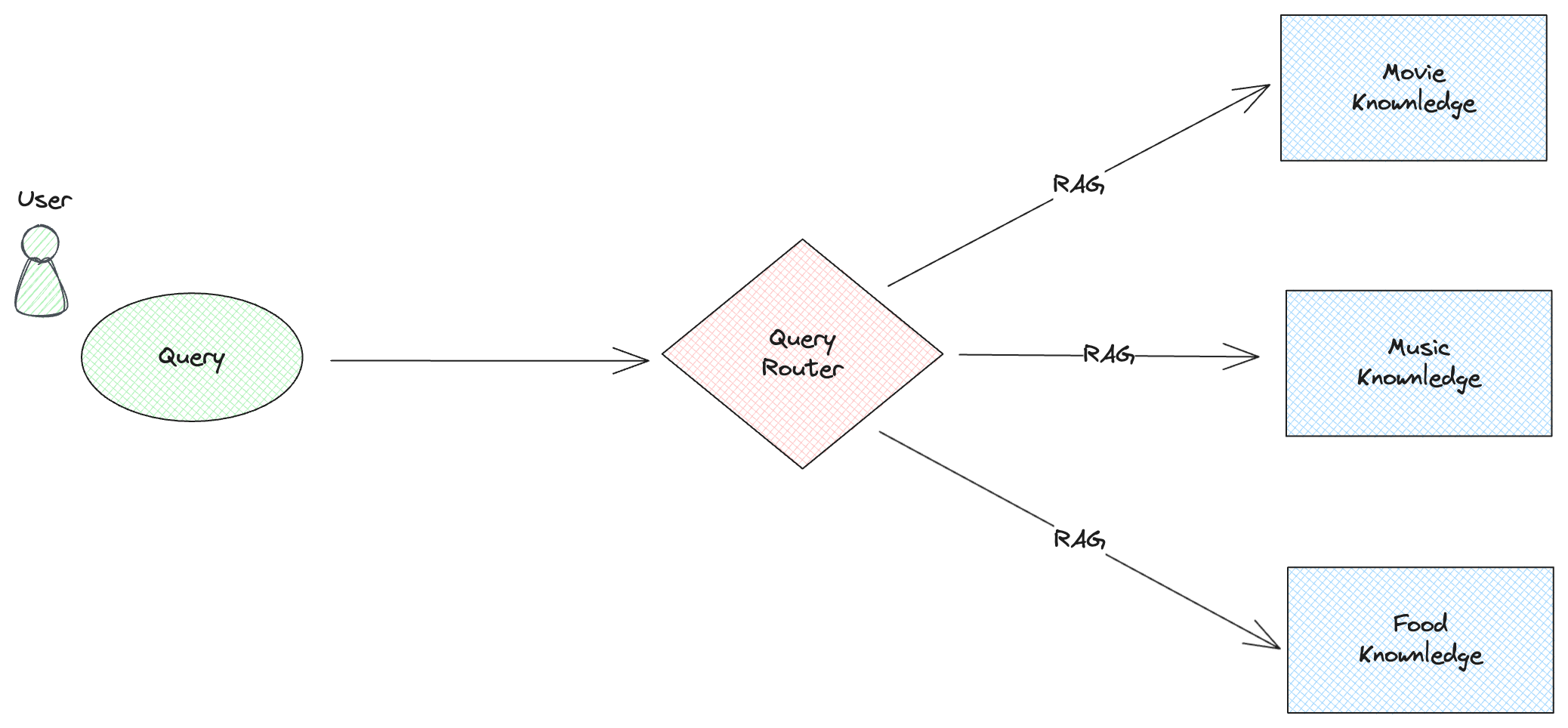
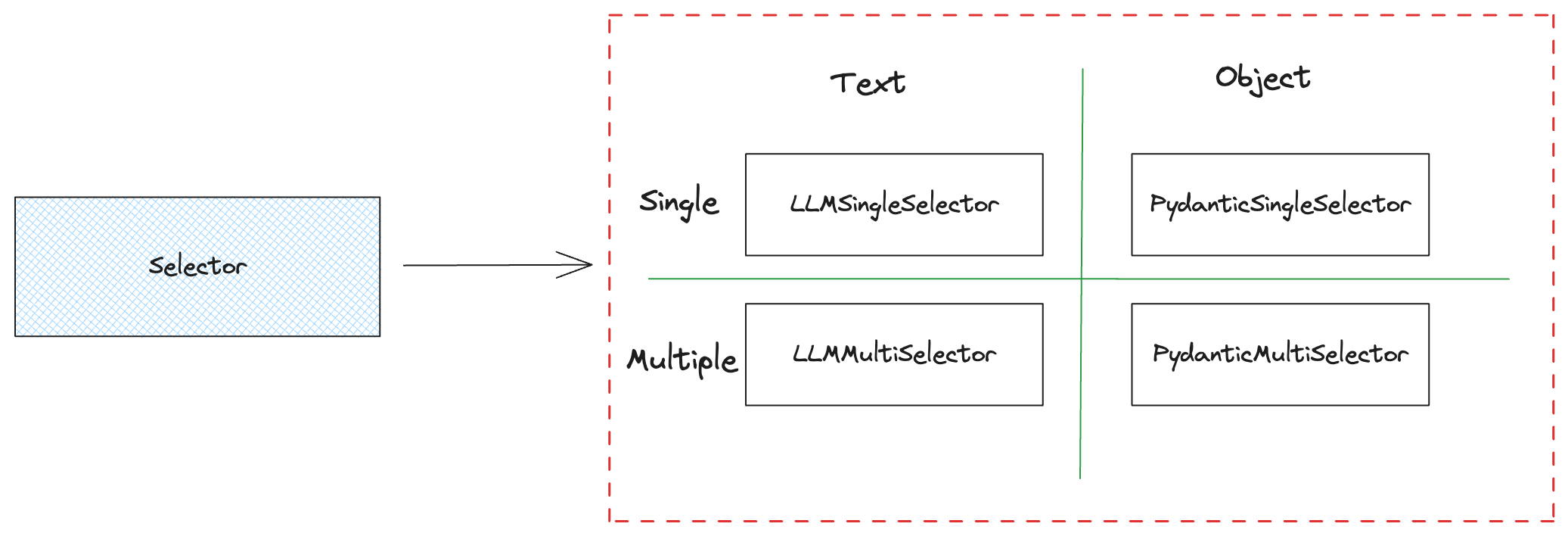
from llama_index.core.query_engine import RouterQueryEngine from llama_index.core.selectors import LLMSingleSelector from llama_index.core.tools import QueryEngineTool
# initialize tools list_tool = QueryEngineTool.from_defaults( query_engine=list_query_engine, description="Useful for summarization questions related to the data source", ) vector_tool = QueryEngineTool.from_defaults( query_engine=vector_query_engine, description="Useful for retrieving specific context related to the data source", )
DEFAULT_SINGLE_SELECT_PROMPT_TMPL = ( "Some choices are given below. It is provided in a numbered list " "(1 to {num_choices}), " "where each item in the list corresponds to a summary.\n" "---------------------\n" "{context_list}" "\n---------------------\n" "Using only the choices above and not prior knowledge, return " "the choice that is most relevant to the question: '{query_str}'\n" )
import os from semantic_router import Route from semantic_router.encoders import CohereEncoder, OpenAIEncoder from semantic_router.layer import RouteLayer
# we could use this as a guide for our chatbot to avoid political conversations politics = Route( name="politics", utterances=[ "isn't politics the best thing ever", "why don't you tell me about your political opinions", "don't you just love the president", "they're going to destroy this country!", "they will save the country!", ], )
# this could be used as an indicator to our chatbot to switch to a more # conversational prompt chitchat = Route( name="chitchat", utterances=[ "how's the weather today?", "how are things going?", "lovely weather today", "the weather is horrendous", "let's go to the chippy", ], )
# we place both of our decisions together into single list routes = [politics, chitchat]
rag_p.add_link("input", "retriever") rag_p.add_link("input", "output", dest_key="query_str") rag_p.add_link("retriever", "output", dest_key="nodes") output = rag_p.run(input="Which two members of the Avengers created Ultron?") print(f"Output: {output}")
import os from typing importDict, Any from llama_index.core.query_pipeline import CustomQueryComponent from llama_index.tools.bing_search import BingSearchToolSpec from llama_index.agent.openai import OpenAIAgent
chitchat = Route( name="chitchat", utterances=[ "how's the weather today?", "how are things going?", "lovely weather today", "the weather is horrendous", "let's go to the chippy", ], )
rag = Route( name="rag", utterances=[ "What mysterious object did Loki use in his attempt to conquer Earth?", "Which two members of the Avengers created Ultron?", "How did Thanos achieve his plan of exterminating half of all life in the universe?", "What method did the Avengers use to reverse Thanos' actions?", "Which member of the Avengers sacrificed themselves to defeat Thanos?", ], )
web = Route( name="web", utterances=[ "Search online for the top three countries in the 2024 Paris Olympics medal table.", "Find the latest news about the U.S. presidential election.", "Look up the current updates on NVIDIA’s stock performance today.", "Search for what Musk said on X last month.", "Find the latest AI news.", ], )
这里我们定义了 3 个 Route,分别针对 3 种不同的问题类型
chitchat Route 的示例语句是一些闲聊语句,对应 chitchat 工具组件
rag Route 的示例语句是一些关于复仇者联盟电影剧情的问题,对应 rag 工具组件
web Route 的示例语句是一些关于网络搜索的问题, 其中有不少 Search、Find 等关键词,对应 web 工具组件
output = p.run(input="hello") # Selection: chitchat # Output: assistant: Hello! How can I assist you today?
output = p.run(input="Which two members of the Avengers created Ultron?") # Selection: rag # Output: Tony Stark and Bruce Banner.
output = p.run(input="Search online for the top three countries in the 2024 Paris Olympics medal table.") # Selection: web # Output: The top three countries in the latest medal table for the 2024 Paris Olympics are as follows: # 1. United States # 2. China # 3. Great Britain