在 Solana 上实现布隆过滤器

在编程世界里,布隆过滤器早已是耳熟能详的高效工具,它能迅速判定一个元素是否存在于集合中,其应用在网络爬虫、数据库查询和缓存系统中屡见不鲜。布隆过滤器凭借其超快的查询速度和极低的内存占用,能巧妙地减少无谓的数据传输与处理,从而极大地提升运行效率。但如果我们想在区块链上实现一个布隆过滤器,是否也能跟中心化互联网世界一样,达到既能存储大量数据又能快速查询的效果呢?今天我们就来带大家在 Solana 这个高性能区块链网络上实现一个布隆过滤器,同时揭示其在实际运行中可能遇到的各种奇妙问题。
布隆过滤器
布隆过滤器由布尔顿・霍华德・布隆(Burton Howard Bloom)在 1970 年提出,它是一种用于检查元素是否属于集合的数据结构,以及在数据库和网络应用中进行高效的数据查询。布隆过滤器使用多个不同的哈希函数将元素映射到一个二进制数组中,通过检查相应的索引位置是否都被设置为 1 来判断元素是否存在。虽然布隆过滤器可能会产生误报(false positive),但不会产生漏报(false negative),即它能准确判断某元素不在集合中,但无法保证判断存在的元素确实存在。布隆过滤器的优势在于不管你要检测的集合有多大,使用布隆过滤器进行查找时所需的内存和时间都是非常低且固定的。此外,布隆过滤器的误报率可以通过调整哈希函数的数量和位数组的大小来控制。
重要属性
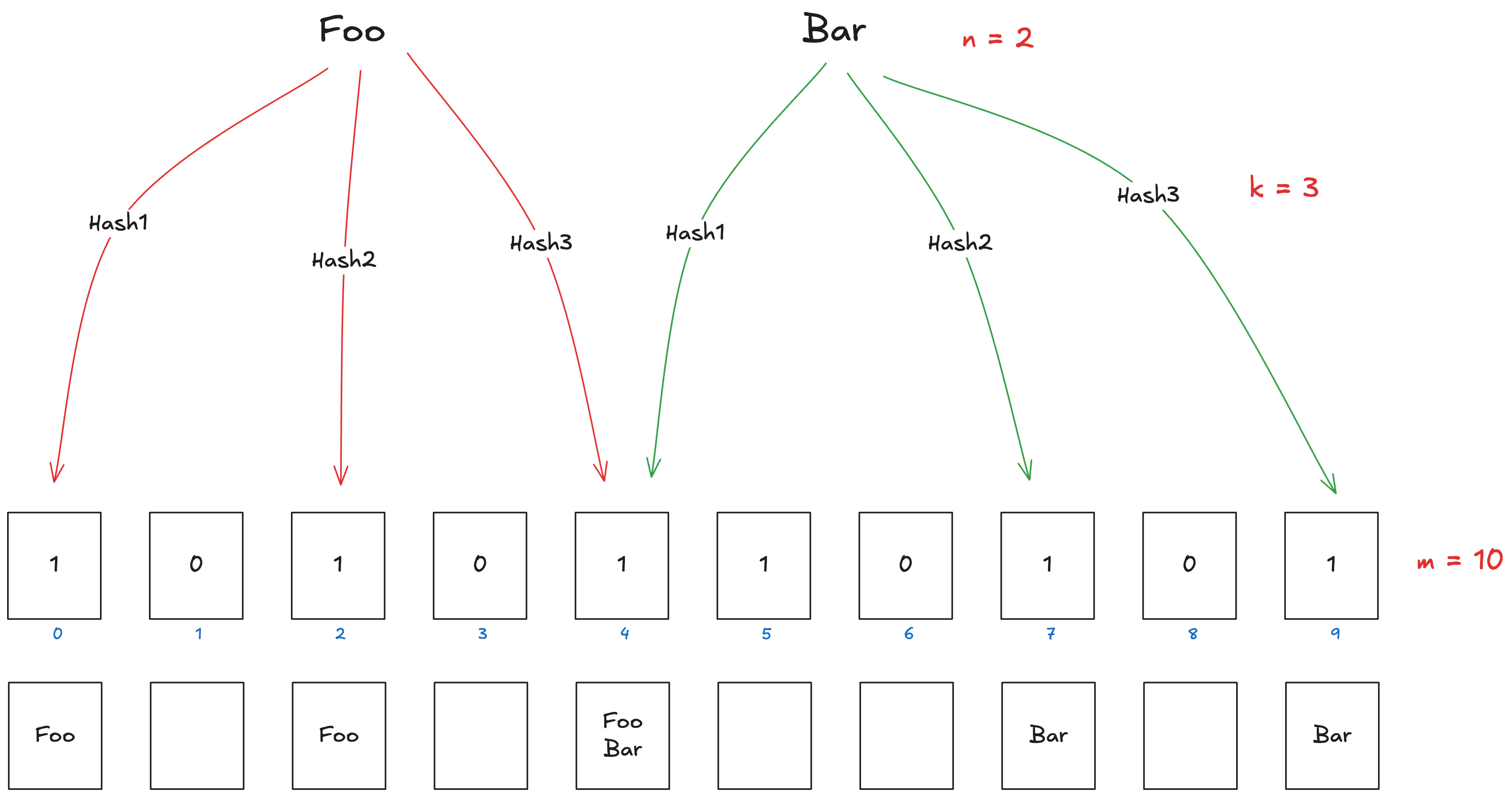
这是布隆过滤器的一个示例图,我们可以从中看到布隆过滤器的几个重要的属性:
- 位图大小(m):位图数组的长度,决定了布隆过滤器所需的存储空间。
- 哈希函数的数量(k):用于将元素映射到位图中的哈希函数个数,影响布隆过滤器的查询性能和误报率。
- 存储元素的数量(n):布隆过滤器中需要存储的元素个数。
- 误报率(p):表示的是一个不在布隆过滤器中的元素被错误地判断为在布隆过滤器中的概率。
以上面的示例图为例,位图(值为 0 和 1)数组长度为 10, 所以 m 为 10,哈希函数有 3 个,所以 k 为 3,存储的元素 分别是 Foo 和 Bar,所以 n 为 2。根据其中的任意 3 个属性,我们都可以计算出第 4 个属性的值,它们的计算公式分别为:
n = ceil(m / (-k / log(1 - exp(log(p) / k))))p = pow(1 - exp(-k / (m / n)), k)m = ceil((n \* log(p)) / log(1 / pow(2, log(2))))k = round((m / n) \* log(2))
为什么会出现误报率
以示例图中的例子为例,我们假设的情形如下:
- 初始化布隆过滤器,长度 m = 10 的布隆过滤器,初始时所有位都是 0,表示为:
0 0 0 0 0 0 0 0 0 0。 - 插入元素
Foo,假设使用的 3 个哈希函数得到的索引分别为:0、2、4,插入Foo后,将索引 0、2、4 位置的位设为 1,布隆过滤器变为:1 0 1 0 1 0 0 0 0 0。 - 插入元素
Bar,假设Bar的 3 个哈希函数得到的索引分别为:4、7、9,插入Bar后,将索引 4、7、9 位置的位设为 1,布隆过滤器变为:1 0 1 0 1 0 0 1 0 1。 - 产生误报的情况,现在假设查询一个未插入的元素
Baz,如果Baz的 3 个哈希函数计算出来的索引碰巧为:2、4、9,此时,我们在布隆过滤器中查看索引 2、4、9 的位,发现它们都为 1。因为所有对应位置都是 1,布隆过滤器会判断Baz可能存在,即返回存在的结果,实际上Baz并没有被插入,这就是误报。
那么误报率多少是合适的呢?一般来说,1% 左右的误报率常见且合适,在很多应用场景中,1% 的误报率被认为是一个较好的折衷方案:既能节省内存,又不会对系统的整体性能产生太大影响。如果应用对准确性要求非常高,可以将误报率降低到 0.1% 甚至更低。但这通常会需要更大的位图大小 m 或者更多的哈希函数 k(但 k 并不是越大越好,太大了反而可能加大误报率),从而增加存储和计算开销。所以这个问题没有标准答案,选择多少误报率合适取决于你的具体场景。例如,在缓存系统、数据库索引等场景下,1% 的误报率已经足够;而在医疗或金融系统中,可能会追求更低的误报率以减少潜在风险。
在这里推荐一个布隆过滤器的在线计算工具:Bloom Filter Calculator,可以帮助你快速计算布隆过滤器的各种属性。
实现布隆过滤器
下面我们来演示如何在 Solana 上实现一个布隆过滤器,我们将使用 Anchor 来编写程序,实现的代码包括布隆过滤器的初始化、插入元素、查询元素等操作,同时有相关的测试代码,以便验证布隆过滤器的正确性。
Anchor 是 Solana 区块链上广泛使用的开发框架,用于简化程序(智能合约)和去中心化应用(DApp)的开发流程。它为开发者提供了一套高效且直观的工具和库,极大降低了 Solana 应用开发的门槛,Solana 官方推荐使用 Anchor 进行开发。
初始化指令
首先我们需要定义一个布隆过滤器的数据结构,包括布隆过滤器的名称、位图大小、哈希函数数量等属性,示例代码如下:
1 | // state.rs |
- 名称 name 用于标识布隆过滤器,长度最大为 32 字节
bit_array是一个布尔类型的数组,用于存储布隆过滤器的位图,因为 Solana Account 在初始化时需要指定固定的长度,所以我们定义了一个最大长度MAX_FILTER_SIZE来作为 bit_array 的最大长度m是位图的大小,是 bit_array 的实际长度k是哈希函数的数量n是布隆过滤器中存储的元素数量false_positive_rate是误报率,范围为 0 到 1
定义好数据结构后,我们来实现布隆过滤器的初始化指令,示例代码如下:
1 | // instructions/init.rs |
- 定义了一个
Init上下文结构,在 Anchor 框架中,每个指令都需要有一个关联的 Context 结构 - 在这个结构中,我们用到了指令的参数
new_filter,可以看到在init方法中也有同样的参数。#[instruction(...)]属性用于声明指令的参数,这些参数会被传递到指令处理函数中作为额外的参数,参数可以在账户验证逻辑中使用 Init结构中包含了用户签名、布隆过滤器账号、系统程序等信息,其中filter是 通过程序派生地址(PDA) 创建的账号- 这个 PDA 账号使用了
BLOOM_FILTER_NAME、用户地址和新布隆过滤器的名称作为种子,通过bump参数来生成地址 filter账号的数据结构实际上就是我们之前定义的BloomFilterinit函数用于初始化布隆过滤器,首先使用参数new_filter来验证新布隆过滤器的参数,然后通过上下文对象ctx获取filter账号,最后调用filter的init方法来初始化布隆过滤器
我们再来看初始化指令中用到的一些参数和方法:
1 | // state.rs |
NewFilter结构用于表示初始化指令的参数,表示我们初始化一个布隆过滤器需要传入这几个参数:名称、位图大小和哈希函数数量validate方法用于验证参数的有效性,包括位图大小和哈希函数数量不能为 0,位图大小不能超过MAX_FILTER_SIZEinit方法用于初始化布隆过滤器,首先根据参数new_filter初始化位图数组bit_array,然后设置布隆过滤器的名称、位图大小、哈希函数数量,位图数组中的元素数量初始化时为 0,误报率也为 0
最后在 lib.rs 中导入相关模块和方法,这样我们的初始化指令就完成了:
1 | // lib.rs |
其他还有add、check 等指令的实现,这里就不再赘述了,完整代码可以参考 bloom-filter-solana 仓库。
测试代码
所有的程序指令完成之后,我们需要编写测试来验证我们的布隆过滤器是否能正常工作,所幸 Anchor 提供了一套完善的测试框架,可以方便地编写测试代码。
在写测试案例之前,我们需要准备好测试的上下文环境,示例代码如下:
1 | import { |
- 首先我们初始化 Solana 环境的 Provider、Connection 和 Program
- 然后在
before钩子函数中创建一个用户账号user,并对这个账号空投了 500 SOL 作为账号的测试费用 - 接着通过 PDA 推导的方式得到布隆过滤器账号
filterAddress的账号地址,后面可以用这个账号来进行验证
接着我们再来看布隆过滤器初始化指令 init 的测试代码:
1 | // tests/bloom_filter.ts |
- 测试程序中首先定义了
init方法的参数newFilter,包括布隆过滤器的名称、位图大小和哈希函数数量 - 然后调用
program.methods.init方法来初始化布隆过滤器,传入参数newFilter,并指定用户账号user为签名者 - 虽然在 Rust 代码中
init方法的 Context 结构中有 3 个账号, 但在测试代码中只需要传入一个用户账号user即可,program.methods.init方法会根据 Rust 程序中定义的 seeds 和 bump 自动推导出 filter 账户的地址,并且会自动包含 system_program 作为依赖 - 最后通过
program.account.bloomFilter.fetch方法获取布隆过滤器账号的数据,然后验证布隆过滤器的名称、位图大小和哈希函数数量是否正确
其他指令的测试代码与 init 指令的测试代码类似,这里就不再赘述了,完整代码可以参考 bloom-filter-solana 仓库。
性能分析
现在我们了解了布隆过滤器在 Solana 程序中的基本实现,但是布隆过滤器在 Solana 网络中实际运行的结果可能与我们期望的有所不同。虽然布隆过滤器可以使用少量的资源来存储和检查大量的数据,但是区块链网络的资源是非常受限的,不管是存储空间还是计算单元(CU),只要程序运行时超过任何一方的限制都会导致程序运行失败,接下来我们就来看看布隆过滤器在 Solana 网络中实际运行的情况。
在 Solana 区块链中,CU 是衡量交易执行时消耗的计算资源最小单位。每笔交易在链上运行时,由于执行不同的指令(如账户写入、跨程序调用、系统调用等),会消耗一定数量的 CU。
存储大小
我们可以通过 init 初始化指令的测试代码来分析布隆过滤器在 Solana 网络中实际的存储大小,我们在之前的测试代码上加上获取布隆过滤器账号存储大小的代码:
1 | // tests/bloom_filter.ts |
- 在测试代码中,我们初始化了一个位图数组长度为 1000 且哈希函数数量为 8 的布隆过滤器
- 在测试方法最后通过
connection.getAccountInfo方法获取布隆过滤器账号的存储大小
然后我们运行这个测试用例,看看实际的存储大小是多少:
1 | $ anchor test |
从测试结果中我们可以看到,布隆过滤器账号的存储大小为 10065 字节。我们继续实验,将测试代码中的位图数组长度 size 修改为 2000,看看修改后账号的存储大小是否有变化,再次运行完程序后,我们惊奇地发现,布隆过滤器账号的存储大小并没有变化,仍然是 10065 字节。这是什么原因呢?
我们回过头去看下 init 指令的 Rust 代码,发现布隆过滤器的位图数组的最大长度在最开始时是由常量 MAX_FILTER_SIZE 决定的,因为 Solana 账号在初始化时需要指定固定长度,而 init 指令中传递的位图数组长度是实际使用的长度,这个长度不能超过 MAX_FILTER_SIZE 的值。
1 | // state.rs |
所以无论我们在测试代码中初始化时设置的位图数组长度是多少,布隆过滤器的账号的存储大小都不会变化,其大小都是按照位图数组最大长度 10000 来计算的。
如果我们修改了位图数组最大长度 MAX_FILTER_SIZE 的值,比如设置为 2000(原来的五分之一),看看实际的存储大小是否有变化:
1 | $ anchor test |
可以看到,这一次布隆过滤器账号的存储大小变成了 2065 字节,证明我们的推断是正确的。然而当我们把最大长度修改为 20000 后(原来的两倍),运行程序则会直接报错,这是因为 Anchor 通过 Cross Program Invocation(CPI)作为内部指令来为账户分配存储空间,每个内部指令允许的最大重新分配空间为 10240 字节,也就是 10KB,当我们的账号大小超过这个限制时,就会报错。
1 | bloom-filter |
小结: 布隆过滤器的存储大小与账号初始化时设置的位图数组最大长度有关,最大长度越大,账号的存储大小越大,但最大长度建议不要超过 10000,否则会报超过账号重分配大小限制的错误。
CU 消耗
现在我们知道布隆过滤器在 Solana 网络的存储大小限制下,可以存储的位图数组是大约 10000 个元素,但在实际运行中,布隆过滤器真的可以存储这么多元素吗?我们可以通过运行测试代码来观察布隆过滤器在实际运行中消耗的 CU 情况。
init 指令
首先我们看下 init 指令的 CU 消耗情况,init 指令的测试代码如之前所示(it("initialize bloom filter with correct name, size and hash functions" 方法),我们分别运行当 size = 1000、2000、3000 且 k = 8 时的测试程序,当执行测试命令 anchor test 后,我们可以在 .anchor/program-logs 目录下找到对应的日志文件,日志文件中会记录每个测试方法的 CU 消耗情况,运行后的测试结果如下:
1 | // tests/bloom_filter.ts |
从测试结果可以看出,当 size = 1000 时,init 指令的 CU 消耗为 65965 CU,而当 size 为 2000 和 3000 时,init 指令的 CU 消耗成倍增长,分别为 122965 CU 和 179967 CU。如果继续将 size 增加到 4000 ,init 指令的 CU 消耗就会超过指令的 CU 限制,导致程序运行失败:
1 | bloom-filter |
我们再来看修改函数数量 k 的 CU 消耗情况,我们用同样的方式进行测试,分别运行当 k = 8、16、32 且 size = 1000 时的测试程序,运行后的测试结果如下:
1 | // tests/bloom_filter.ts |
从测试结果可以看出,函数数量的增长对于 CU 的消耗影响不大,init 指令的 CU 消耗基本保持不变。
add 指令
接下来我们看下 add 指令的 CU 消耗情况,add 指令的测试代码(describe("add element") 方法)可在 bloom-filter-solana 仓库中找到,我们分别运行当布隆过滤器的 size = 1000、2000、3000 且 k = 8 时的 add 指令测试程序,运行后的测试结果如下:
1 | // tests/bloom_filter.ts |
从测试结果可以看出,当 size = 1000 时,add 指令的 CU 消耗为 99756 CU,当 size 为 2000 时,add 指令的 CU 消耗为 179865 CU,当 size 为 3000 时,add 指令的 CU 消耗超过了单个指令的 CU 限制(200000 CU),导致程序运行失败。
我们再来看修改函数数量 k 后 add 指令的 CU 消耗情况,我们用同样的方式进行测试,分别运行当 k = 8、16、32 且 size = 1000 时的测试程序,运行后的测试结果如下:
1 | // tests/bloom_filter.ts |
从测试结果可以看出,函数数量的增长对于 CU 的消耗影响不大,add 指令的 CU 消耗随着函数数量的增加而增加,增幅大约为 10000 CU。
check 指令
最后我们来看下 check 指令的 CU 消耗情况,check 指令的测试代码(describe("check element") 方法)可在 bloom-filter-solana 仓库中找到,我们分别运行当布隆过滤器的 size = 1000、2000、3000 且 k = 8 时的 check 指令测试程序,运行后的测试结果如下:
1 | // tests/bloom_filter.ts |
check 指令首先需要通过 add 指令来添加布隆过滤器的元素,所以它的 CU 消耗受限于 add 指令的 CU 消耗。从测试结果可以看出,check 指令的 CU 消耗从位图数组长度 1000 增加到 2000 时,增加的幅度不足位图数组长度 1000 时的 2 倍。当位图数组长度增加到 3000 时,check 指令由于 add 指令的 CU 消耗超过了单个指令的 CU 限制,导致程序运行失败。
我们再来看修改函数数量 k 后 check 指令的 CU 消耗情况,我们用同样的方式进行测试,分别运行当 k = 8、16、32 且 size = 1000 时的测试程序,运行后的测试结果如下:
1 | // tests/bloom_filter.ts |
从测试结果可以看出,函数数量的增长对于 CU 的消耗影响不大,check 指令的 CU 消耗随着函数数量的增加而增加,增幅大约为 5000~10000 CU。
最终结论
通过以上测试,我们可以得到以下结论:
- 布隆过滤器在 Solana 网络中,位图数组长度
m最大可以设置为 2000 多一些,且不能超过 3000 - 函数数量
k可以设置为 1~32+ ,但不是越大越好,k超过一定数量之后误判率反而会升高
如果我们想控制布隆过滤器的误报率 p 在 0.01 以下,那么根据公式:
1 | n = ceil(m / (-k / log(1 - exp(log(p) / k)))) |
我们可以算出存储元素的数量 n 的值:
1 | p = 0.01 (1 in 100) |
也就是说,当布隆过滤器的位图数组长度为 2000 且函数数量为 8 时,最多可以存储 207 个元素,如果超过这个数量,布隆过滤器的误报率会超过 0.01,我们可以写一个性能测试来验证这个结论:
1 | describe("performance", () => { |
测试中我们通过调用 add 方法添加了 207 个元素, 然后分别打印出布隆过滤器的名称、位图数组长度、函数数量、存储元素的数量、误报率,通过测试结果可以看出,布隆过滤器的误报率大约为 0.01,与理论计算结果一致。
总结
Solana 上的布隆过滤器虽然有诸多限制,但通过合理的设计和优化,它仍然能在许多场景中发挥重要作用。以下是几个典型的应用场景:
- 特定场景下的应用价值:即使只能存储 200 多个元素,在某些特定用例中仍然非常有用。例如验证小型白名单、简单权限控制或轻量级重复数据检测等场景。
- 链下与链上结合使用:可以将布隆过滤器作为链上和链下系统的桥梁。大量数据存储在链下,只在链上保存验证所需的布隆过滤器。
- 分片使用:可以创建多个布隆过滤器账号,每个处理不同的数据子集,类似于分布式哈希表的思想。
- 作为初筛工具:布隆过滤器可以作为第一道防线,快速排除明确不在集合中的元素,减少需要进行更详细验证的数据量。
布隆过滤器在 Solana 上的应用需要针对其限制进行优化设计。它不适合存储大量数据,但对于特定用例和优化场景下仍有其独特价值,关键是理解你的应用需求,评估布隆过滤器是否真的是最佳选择。
参考
关注我,一起学习各种最新的 AI 和编程开发技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。

